基于LightX2V优化的混元Video模型在英特尔 AI PC 上的自动化适配实践
 openlab_96bf3613
更新于 2月前
openlab_96bf3613
更新于 2月前
作者:雍洋(LightX2V),许紫妍(英特尔),谭嫣然(英特尔)
LightX2V 是一个先进的轻量级图像视频生成推理框架,专为提供高性能的图像视频生成推理解决方案而设计。LightX2V集成了多种前沿的图像视频生成加速技术,支持多种推理平台部署,支持文本生成视频、图像生成视频、文本生图片、图像编辑以及世界模型等多样化生成任务。
第三代英特尔酷睿 Ultra处理器家族以卓越性能、领先显卡表现、强大AI算力与数日电池续航,不仅可以全面满足用户对AI PC的多样化需求,更以其广泛的适用性和规模化部署能力,重塑了轻薄本的性能标杆。
结合 LightX2V 轻量级图像视频生成框架与基于英特尔酷睿 Ultra 处理器的的AI PC,依托 卓越的CPU、GPU、NPU 三引擎协同算力,实现端侧高效推理。无需依赖云端,即可快速完成文生视频、图生视频、图像编辑等任务,兼顾性能与功耗,为用户带来流畅、安全、便捷的本地生成体验。
现在有了人工智能的加持,利用已在Lighxt2V社区发布的./claude/skill/ Model_Enable_Intel_XPU skill就可以轻松的在基于英特尔酷睿 Ultra 处理器的的AI PC适配图像视频生成,上享受到LightX2V推理方案带来的优异性能。
实践案例:基于AI skills,在 Intel AI PC 上适配基于 LightX2V的 HunyuanVideo‑1.5 视频生成模型
本节以 HunyuanVideo‑1.5 为例,介绍在 Intel AI PC(Intel Arc XPU,系统内存为 32 GB,其中 iGPU 侧可用显存约为 16 GB) 上,如何利用AI skills 来 完成基于LightX2V优化的一个 10B+ 级的视频生成模型的适配和视频生成过程。
HunyuanVideo-1.5模型简介:HunyuanVideo‑1.5 是腾讯开源的视频生成模型,采用 Diffusion Transformer(DiT) 架构,具备高质量文本到视频与图像到视频生成能力。在保持生成质量的同时显著降低了推理门槛;其推理流程依赖 DiT 主干、视觉‑语言文本编码器以及时空 VAE 等组件,对端侧内存调度提出了较高要求。
发布在lightX2V 社区的Model_Enable_Intel_XPU_Skill 将整个模型的适配过程封装为一套固定流程,使众多开发者能够利用该Skill 采用当前流行的native AI模式快速完成新模型 Intel AI PC 平台上基于LightX2V的快速适配,并利用适配好的模型进行视频生成。
准备:
- 硬件平台:实验运行于搭载 Intel Core Ultra 7 258V 的 Intel AI PC,内置 Intel Arc 140V GPU(统一内存 32 GB,XPU 侧约 16GB),操作系统为 Windows 11。
- 软件环境:XPU 推理依赖 Intel oneAPI 工具链,需提前安装,点击https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/base-toolkit-download.html 的安装包下载安装。需初始化 oneAPI 环境变量:call "C:\Program Files (x86)\Intel\oneAPI\setvar***at"
推理框架使用 LightX2V(GitHub: ModelTC/LightX2V),配套包含的预打包环境
- 模型来源:HunyuanVideo-1.5(下载地址:https://huggingface.co/tencent/HunyuanVideo-1.5 )原始总体积约 50GB。
- Model_Enable_Intel_XPU_Skill 下载地址 :https://github.com/ModelTC/LightX2V/tree/main/.claude/skills/Model_Enable_Intel_XPU
本次的实践是利用 Claude Opus 4.6 来配合该Skill去完成相关工作,可以看到利用Model_Enable_Intel_XPU_Skill 会主要完成下面的一些工作
Step 1:分析模型结构,指定适配策略
根据提供模型的路径与基本规模信息,对模型权重结构进行确认,用于确定适配策略,包括是否需要量化、是否启用 Offload,以及文本编码器与 VAE 是否需要单独处理。
Step 2:根据适配策略,生成 相关脚本并执行
在确定适配策略后,生先成相关转化脚本,如在本案例中会根据系统配置在完成 DiT 主干的权重准备后准备 FP8 量化以及按 Transformer block 拆分权重,生成 Offload 可用的权重布局。必要的非 block 权重将被保留用于模型初始化。
而整个过程遵循 Skill 的既定约定,具体的量化算法或权重格式细节这些都不再需要关注。
执行 fp8‑intel‑xpu 转换的日志如下:
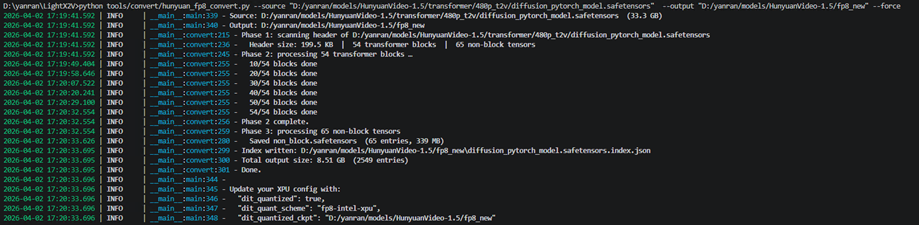
当文本编码器在 fp16 精度**积接近或超过 XPU 可用内存预算时,按 XPU Skill 的规范会启用 INT8 量化加载,以避免加载阶段 OOM,并确保其内存占用不与 DiT 推理阶段叠加。
Step 3: LightX2V 的高级特性使能( Offload 推理执行)
在模型完成接入后,会根据系统条件启用LighX2V的高级特性 DiT offload推理执行,并对文本编码器与 VAE 采用按需加载与卸载策略,使模型权重在 Disk → CPU → XPU 之间按需流转。
Offload 启用后的推理配置示例
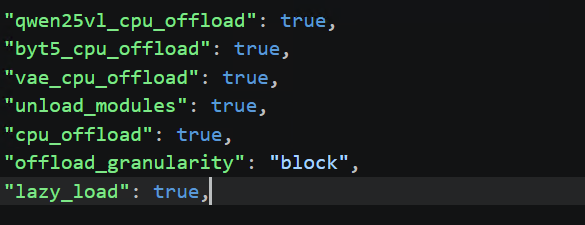
此外该Skill提供了平台约束优化推理流程 来更好地优化客户在Intel Arc 140V上应用体验。
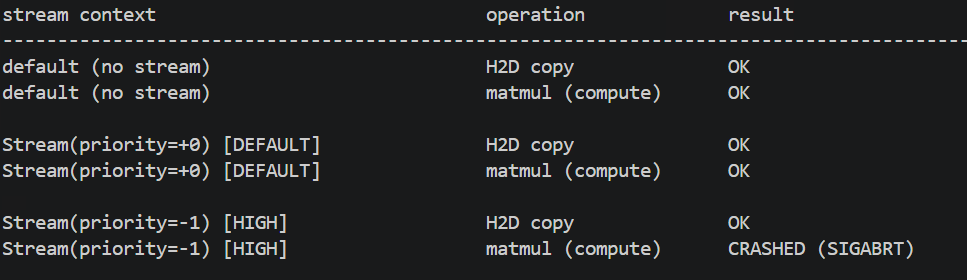
1. Stream 不设置 priority 参数
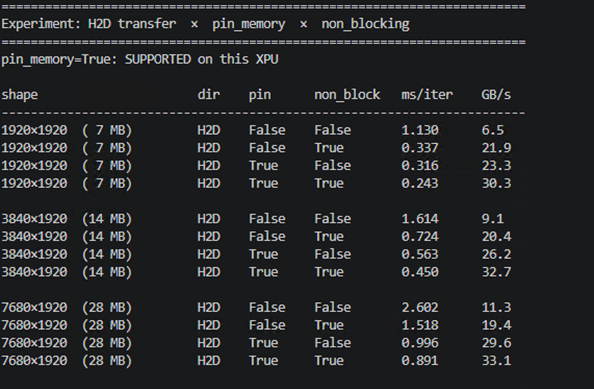
2. 同时启用 pinned memory 与 non‑blocking 传输,确保权重预取与计算流水能够有效重叠
结果:可以看到HunyuanVideo1.5 可在这台32GB的Intel AI PC 上稳定运行,顺利完成T2V任务
prompt " a cute cat walking on a wooden table "


同时,通过系统任务管理器,可以看到HunyuanVideo-1.5 在视频生成过程中GPU的运行状态
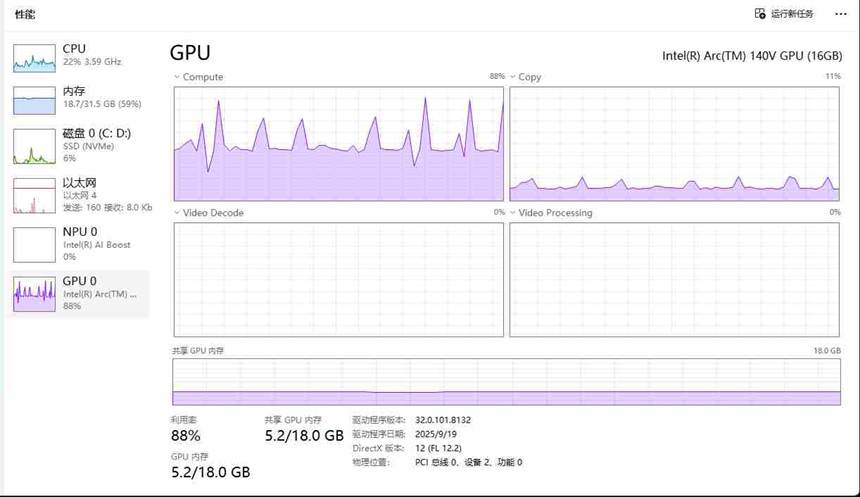
展望:
通过上述的实践过程,我们顺利完成了基于LightX2V 的hunyunvideo-1.5模型在Intel AI PC上的适配,后续还会有更多性能优化的Skill在社区发布,也欢迎开发者们利用这些Skill 来贡献更多的模型的适配到LightxX2V社区。