OpenVINO™ Day 0 支持 ERNIE-Image:8B 文生图模型第一时间跑在 Intel CPU 和 GPU 上
 openlab_96bf3613
更新于 2月前
openlab_96bf3613
更新于 2月前
百度文心大模型团队最新推出的 ERNIE-Image,是一款基于 DiT 架构的 8B 文生图模型。它不仅强调通用图像生成能力,更在复杂指令遵循、精准文字渲染、结构化生成和多风格表达方面展现出很强的潜力;同时,消费级 GPU 即可完成部署,这让它天然具备较高的开发者价值。
现在,OpenVINO™ 已正式实现对 ERNIE-Image 的 Day 0 支持。这意味着开发者可以在模型发布后的第一时间,将 ERNIE-Image 更方便地跑在 Intel CPU 和 GPU 上,快速完成从模型导出、推理验证到应用落地的全流程实践。借助 OpenVINO™,ERNIE-Image 现已支持导出为FP16 / INT8 / INT4 格式的 OpenVINO™ IR,并通过 OVErnieImagePipeline 直接进行推理与验证,进一步降低了新模型部署和优化的门槛。与此同时,OpenVINO™ 也已同步支持 ERNIE-Image-Turbo,进一步覆盖了更快生成、轻量化部署的需求场景,为开发者在效果与速度之间提供了更灵活的选择。这样一来,无论是追求更强生成质量的标准版,还是更强调响应速度和部署效率的 Turbo 版本,开发者都可以在 Intel 平台上第一时间开展测试和落地实践。
接下来,我们来看看具体怎么把模型通过OpenVINO™优化以及部署起来。
第一步: 克隆仓库并创建虚拟环境
git clone https://github.com/openvino-dev-samples/optimum-intel.gitcd optimum-intelgit checkout ernie-imagegit checkout 6a55b811e51bf0dd2e09dc9f4f826c99704cf457Python -m venv py_envpy_env\Scripts\activate# Linux: source py_env/bin/activate
第二步:安装依赖
pip install "git+https://github.com/huggingface/optimum.git@ec676fd4e0b1440e91549e7a1aa82e0de85e79b5"pip install "git+https://github.com/huggingface/diffusers.git@6a339ce637db184c2e1a10ec90ac0e292beb76ac"pip install transformers==4.57.6pip install openvino==2026.1.0pip install openvino-tokenizers==2026.1.0.0pip install nncf==3.0.0pip install torch==2.10.0 --index-url https://download.pytorch.org/whl/cpupip install -e ".[openvino,nncf,diffusers]"
第三步:准备原始模型
拿到原始 PyTorch 权重后,目录应类似如下:
ERNIE-Image/├── model_index.json├── scheduler/├── text_encoder/├── tokenizer/├── transformer/└── vae/
第四步:将模型导出为 OpenVINO™ IR格式,并进行量化压缩
可以采用如下命令,导出FP16精度的模型:
optimum-cli export openvino \--model /path/to/ERNIE-Image-Turbo \--task text-to-image \--weight-format fp16 \./ernie_image_turbo_fp16
可以采用如下命令,导出INT4精度的经过量化压缩后的模型:
optimum-cli export openvino \--model /path/to/ERNIE-Image \--task text-to-image \--weight-format int4 \./ernie_image_int4
导出后的 INT4 目录会包含 model_index.json、openvino_config.json、scheduler、tokenizer、text_encoder、transformer、vae_encoder 和 vae_decoder 等组件。
第五步:开始 OpenVINO™ 推理
导出完成后,可以直接用 OVErnieImagePipeline 进行推理:
from optimum.intel import OVErnieImagePipelineimport torchpipe = OVErnieImagePipeline.from_pretrained("./ernie_image_int4",device="CPU",#或者GPU)generator = torch.Generator("cpu").manual_seed(42)result = pipe(prompt="a cute cat sitting on a colorful cushion, studio lighting, high quality",num_inference_steps=20,height=512,width=512,generator=generator,)result.images[0].save("output.png")
几个建议参数也可以顺手记住:
num_inference_steps:Base模型推荐50,Turbo模型推荐8
height / width:建议使用 64 的整数倍
guidance_scale:建议不超过 5.0
generator:用于复现实验结果。
最终在Intel Core Ultra X7 358H的笔记本电脑的GPU上的运行Turbo模型的效果如下:
效果视频:https://live.csdn.net/v/521777
运行50steps的Base模型量化为INT4精度的OpenVINO™ IR模型的效果如下:
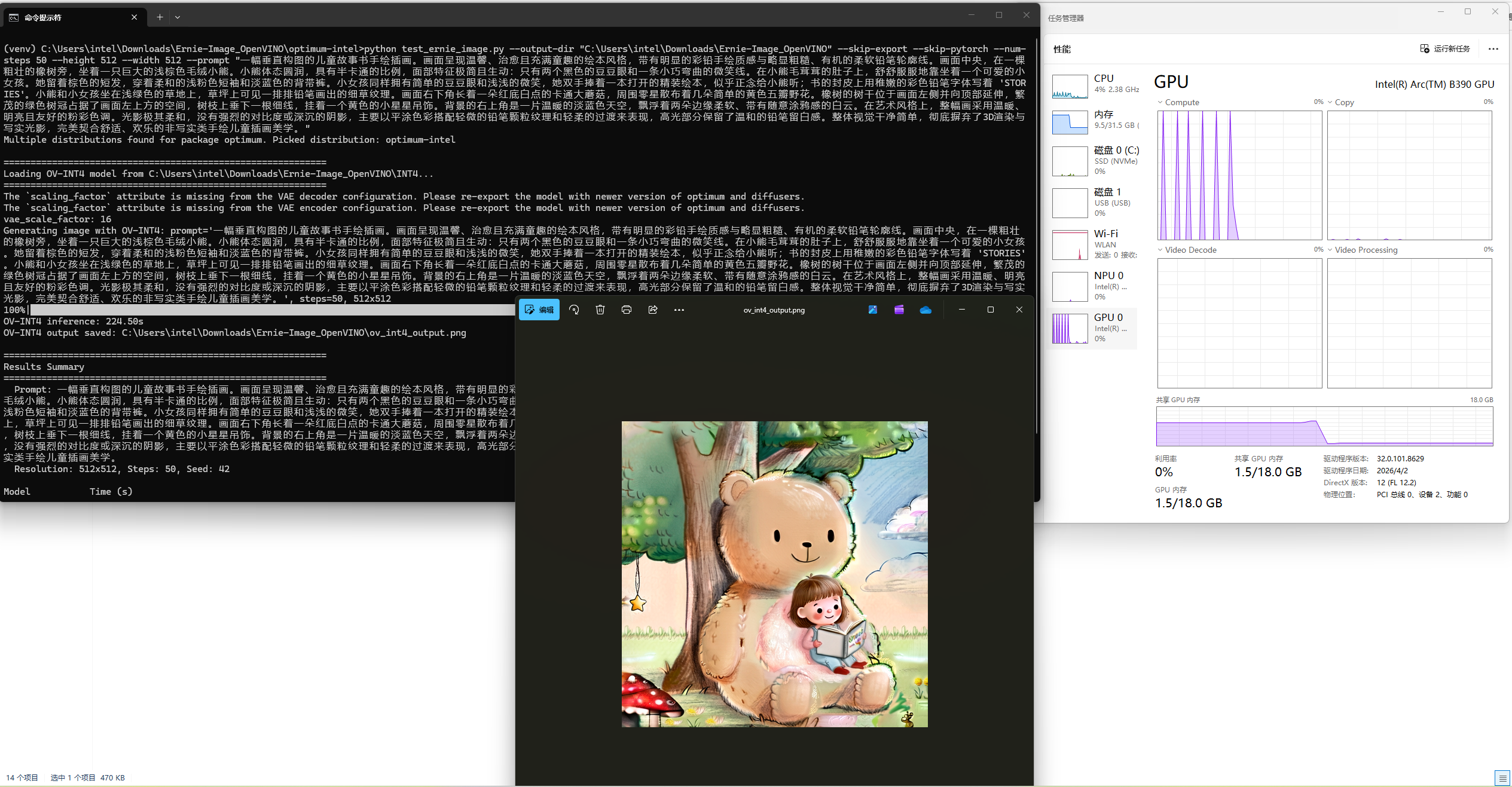
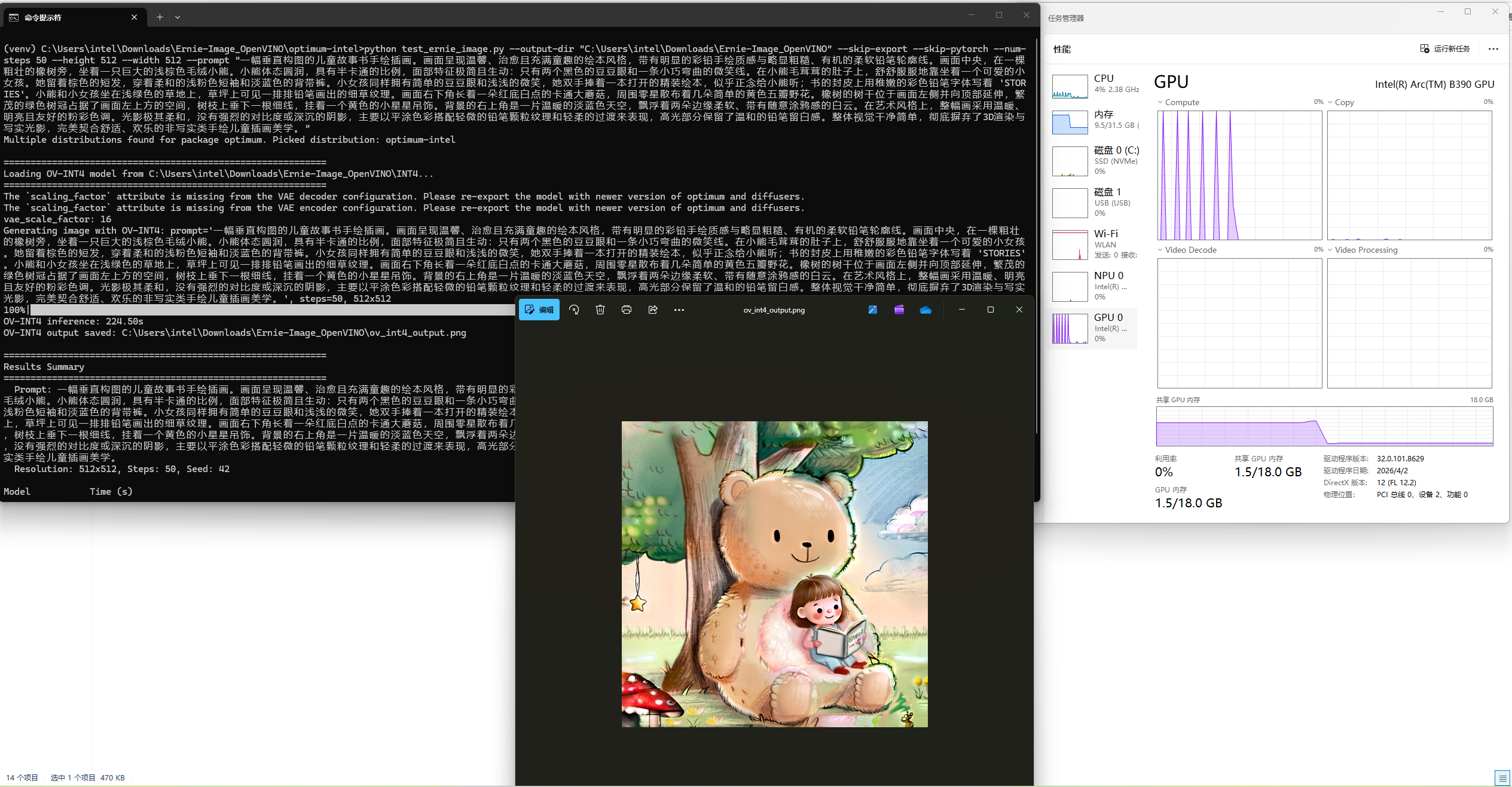
总结
对 Intel 平台开发者来说,这次 OpenVINO™ 对 ERNIE-Image 的 Day 0 支持,意义不只是“多支持了一个新模型”,而是把一个具备复杂指令遵循、文字渲染、结构化生成和多风格表达能力的 8B 文生图模型,第一时间带到了可部署、可验证、可集成的状态。现在,开发者已经可以基于已验证的依赖组合,把原始 PyTorch 权重导出为 FP16 / INT8 / INT4 OpenVINO™ IR,并通过 OpenVINO™在 Intel CPU 和 GPU 路线上更快完成测试与应用验证。
如果你正在关注下一代文生图模型的本地部署,尤其关心复杂 prompt 理解、文字生成、结构化视觉任务这些更接近真实场景的能力,那么 ERNIE-Image 非常值得现在就试,而 OpenVINO 已经把这条路打通了。
如果你正在使用 OpenVINO™ 做生成式 AI 模型部署,或者希望把新的文生图模型更快跑在 Intel CPU / GPU 上,欢迎继续关注 OpenVINO™ 中文社区的后续更新与开发者内容。我们也会继续补充更多实践经验、性能调优和部署示例。
ERNIE-Image 已经来了,OpenVINO™ 也已经把 Day 0 支持准备好了。
现在,就是把它跑起来、验证它、把它接进你自己的应用里的时候。