OpenClaw 爆火之后,很多人的 Token 账单开始让他们怀疑人生
OpenClaw 爆火之后,很多人的 Token 账单开始让他们怀疑人生
最近有一个挺有意思的现象。
身边不少朋友开始用 OpenClaw 搭 AI Agent,第一个月用下来兴奋得不行——自动处理邮件、生成报告、帮公司跑数据流程。结果第二个月,账单一来,人直接傻了。
"我就用了个 AI 助手,怎么 Token 费用比我的云服务器还贵?"
其实这个问题,有点像早年大家刚开始用手机流量的感觉:觉得自己只是"偶尔刷刷",结果月底账单显示你刷了 20GB。
Token 暴涨,不是因为你"多说了几句话"
OpenClaw 爆火之后,很多人的 Token 账单开始让他们怀疑人生
最近有一个挺有意思的现象。
身边不少朋友开始用 OpenClaw 搭 AI Agent,第一个月用下来兴奋得不行——自动处理邮件、生成报告、帮公司跑数据流程。结果第二个月,账单一来,人直接傻了。
"我就用了个 AI 助手,怎么 Token 费用比我的云服务器还贵?"
其实这个问题,有点像早年大家刚开始用手机流量的感觉:觉得自己只是"偶尔刷刷",结果月底账单显示你刷了 20GB。
Token 暴涨,不是因为你"多说了几句话"
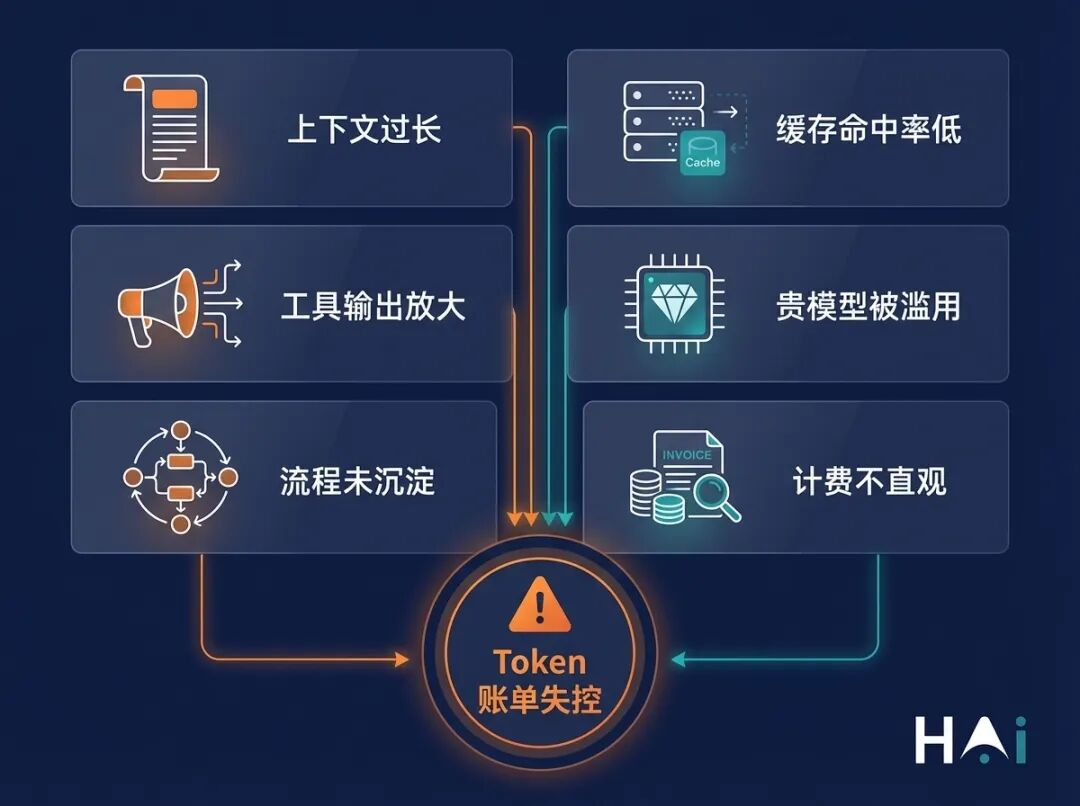
很多人以为 Token 就是对话字数,所以节省 Token 的方式是"少说话"。这个理解差得有点远。
在 AI Agent 的场景里,Token 的消耗来自至少六个维度,任何一个没管好,账单都会悄悄膨胀:
1. 上下文越来越长
Agent 是持续运行的工作流,不是聊一句答一句。每次调用,历史对话、任务记录、工具返回结果都要带进去。会话越长,每次调用就越贵——哪怕你只问了一个很简单的问题,背着几千字的旧上下文,照样是大消耗。
2. 缓存命中率低,同样的内容反复发送
系统提示、角色设定、工具定义——这些内容每次都要发给模型。如果前缀不稳定(哪怕只改了一个字),缓存就失效,重新计费。很多人不知道,"让前缀保持稳定"这件事,可以直接影响几十个百分点的成本。
3. 工具调用放大了输入量
Agent 调用工具时,会把工具的返回结果一起塞进上下文。问题是工具返回的内容往往很"原始"——几百行日志、整份文件、完整 API 响应。你只需要其中三行,但模型要"看完"全部。
4. 贵模型被滥用
格式转换、简单分类、文本总结——这类任务根本不需要最顶级的模型来做。但如果你的 Agent 默认全部走高阶模型,成本就不是线性增加,是指数级浪费。
5. 流程没有沉淀,同样的事反复做
高频任务如果没有变成模板、Skill 或知识库,每次都要从头推理,每次都要烧一遍 Token。有些团队每天都在重复做同一件事,成本却没有随着使用频次降低。
6. 计费不直观,用户没有"Token 等于钱"的直觉
这是最容易被忽视的一个问题。Token 是技术计量单位,不是用户熟悉的消费单位。同一个任务,因为上下文不同、模型不同、工具回传量不同,实际消耗可能相差十倍。你不知道一次任务要花多少,任务跑完也不清楚为什么贵了。
说白了,Token 失控不是"你说话太多",是整个系统设计没有考虑成本。
企业场景更严重:成本乘以人头数
个人用 OpenClaw 成本飙升,还可以靠自己摸索优化。企业就麻烦了。
一个团队 10 个人,每人每天用 AI Agent 处理工作流,上下文管理不好,缓存没命中,模型没分层……这些问题叠加起来,成本乘以 10。
更关键的是,企业面对的不只是"贵"的问题,还有不可预测的问题。
Token 按量计费,月底账单是多少,跑之前没人知道。一个复杂任务跑出来,CEO 看到账单,问你为什么贵——你也说不清楚哪一步烧了多少。预算管控基本靠"感觉"。
这就是为什么不少团队开始寻找按量计费之外的选择。
HAI 的逻辑:用公平秤,而不是计量器

HAI 做的事,本质是把"原材料批发"变成"服务包月"。
不同于直接在各家模型厂商那里按 Token 单独计费,HAI 提供的是统一 API 入口 + 更稳定的计费结构。你不需要分别去管 DeepSeek、千问、Kimi 、OpenAI、Claude各自的账单,通过一个接口,按实际需要调用不同的模型。
这对 OpenClaw 用户来说有几个直接的好处:
多模型灵活切换,成本可以自己控
简单任务走轻量模型,复杂推理再上高阶模型——这件事 HAI 的 API 支持一个接口切换,不需要你自己对接多家厂商。模型分层的成本优化,变成了一个配置问题,而不是工程问题。
用量透明,账单不再是谜
HAI 提供统一的调用记录和用量追踪,你可以清楚地看到每次调用消耗了多少,哪个模型、哪个任务、哪段时间成本最高。这个透明度,对企业做预算管控非常实际。
按需付费,不锁定、不浪费
不像某些服务要你先充一大笔再用,HAI 支持按实际需求付费,不用担心预充的额度到期失效,也不用为了"用完额度"而故意多调用。
对于个人开发者,HAI 降低了接触多家顶级模型的门槛——不用分别申请 OpenAI、Anthropic 的 API,一个接入点搞定。
优化 Token 消耗,可以从今天开始做的几件事
聊完背景,来点实操的。不管你用不用 HAI,这几件事都值得做:
压缩历史上下文 — 长会话定期做 compact,不需要的旧对话不要一直带着跑。
稳定系统提示前缀 — 系统提示、角色设定写完就别动,静态内容放前面,动态内容放后面,缓存命中率会明显提升。
工具输出先过滤 — 日志先 grep 出关键行,文件先提取关键段,再送给模型。别让模型"看全文"。
建立模型分层 — 格式转换、分类任务用小模型,需要深度推理的任务再用大模型。贵的模型留给真正值钱的问题。
高频任务模板化 — 反复做的事情,沉淀成 Skill 或模板,不要每次从头推理。
做好这五件事,Token 消耗降 30%~50% 不是难事。
说到底,Token 优化是 AI 能不能规模落地的基础
现在很多人用 AI Agent 还处在"尝鲜"阶段,成本高点无所谓,觉得值。
但当 AI Agent 真正成为工作流的一部分,每天、每周、每月持续运行,成本就从"可以忽略"变成了"必须优化"。
Token 优化不是省小钱,是决定 AI 应用能不能在企业里跑通的基础能力。
那些在早期就把这个问题想清楚的团队,会有很大的优势。
如果你也在用 OpenClaw 或者搭 AI Agent,用量开始上来了,不妨了解一下 HAI 的 API 服务——多模型统一入口,账单透明可追踪,按需付费,不预充不浪费,是目前对开发者比较友好的选择之一
如果想进一步了解大模型 API 服务以及 AI 应用落地的一些实践案例,可以参考一些聚合型 AI 平台的资料,比如 hai.network,里面整理了不少不同模型的接口和使用方式。
关注「Hybrid AI Hub」,持续追踪 AI 前沿,不错过每一个值得关注的行业动态。
很多人以为 Token 就是对话字数,所以节省 Token 的方式是"少说话"。这个理解差得有点远。
在 AI Agent 的场景里,Token 的消耗来自至少六个维度,任何一个没管好,账单都会悄悄膨胀:
1. 上下文越来越长
Agent 是持续运行的工作流,不是聊一句答一句。每次调用,历史对话、任务记录、工具返回结果都要带进去。会话越长,每次调用就越贵——哪怕你只问了一个很简单的问题,背着几千字的旧上下文,照样是大消耗。
2. 缓存命中率低,同样的内容反复发送
系统提示、角色设定、工具定义——这些内容每次都要发给模型。如果前缀不稳定(哪怕只改了一个字),缓存就失效,重新计费。很多人不知道,"让前缀保持稳定"这件事,可以直接影响几十个百分点的成本。
3. 工具调用放大了输入量
Agent 调用工具时,会把工具的返回结果一起塞进上下文。问题是工具返回的内容往往很"原始"——几百行日志、整份文件、完整 API 响应。你只需要其中三行,但模型要"看完"全部。
4. 贵模型被滥用
格式转换、简单分类、文本总结——这类任务根本不需要最顶级的模型来做。但如果你的 Agent 默认全部走高阶模型,成本就不是线性增加,是指数级浪费。
5. 流程没有沉淀,同样的事反复做
高频任务如果没有变成模板、Skill 或知识库,每次都要从头推理,每次都要烧一遍 Token。有些团队每天都在重复做同一件事,成本却没有随着使用频次降低。
6. 计费不直观,用户没有"Token 等于钱"的直觉
这是最容易被忽视的一个问题。Token 是技术计量单位,不是用户熟悉的消费单位。同一个任务,因为上下文不同、模型不同、工具回传量不同,实际消耗可能相差十倍。你不知道一次任务要花多少,任务跑完也不清楚为什么贵了。
说白了,Token 失控不是"你说话太多",是整个系统设计没有考虑成本。
企业场景更严重:成本乘以人头数
个人用 OpenClaw 成本飙升,还可以靠自己摸索优化。企业就麻烦了。
一个团队 10 个人,每人每天用 AI Agent 处理工作流,上下文管理不好,缓存没命中,模型没分层……这些问题叠加起来,成本乘以 10。
更关键的是,企业面对的不只是"贵"的问题,还有不可预测的问题。
Token 按量计费,月底账单是多少,跑之前没人知道。一个复杂任务跑出来,CEO 看到账单,问你为什么贵——你也说不清楚哪一步烧了多少。预算管控基本靠"感觉"。
这就是为什么不少团队开始寻找按量计费之外的选择。
HAI 的逻辑:用公平秤,而不是计量器

HAI 做的事,本质是把"原材料批发"变成"服务包月"。
不同于直接在各家模型厂商那里按 Token 单独计费,HAI 提供的是统一 API 入口 + 更稳定的计费结构。你不需要分别去管 DeepSeek、千问、Kimi 、OpenAI、Claude各自的账单,通过一个接口,按实际需要调用不同的模型。
这对 OpenClaw 用户来说有几个直接的好处:
多模型灵活切换,成本可以自己控
简单任务走轻量模型,复杂推理再上高阶模型——这件事 HAI 的 API 支持一个接口切换,不需要你自己对接多家厂商。模型分层的成本优化,变成了一个配置问题,而不是工程问题。
用量透明,账单不再是谜
HAI 提供统一的调用记录和用量追踪,你可以清楚地看到每次调用消耗了多少,哪个模型、哪个任务、哪段时间成本最高。这个透明度,对企业做预算管控非常实际。
按需付费,不锁定、不浪费
不像某些服务要你先充一大笔再用,HAI 支持按实际需求付费,不用担心预充的额度到期失效,也不用为了"用完额度"而故意多调用。
对于个人开发者,HAI 降低了接触多家顶级模型的门槛——不用分别申请 OpenAI、Anthropic 的 API,一个接入点搞定。
优化 Token 消耗,可以从今天开始做的几件事
聊完背景,来点实操的。不管你用不用 HAI,这几件事都值得做:
压缩历史上下文 — 长会话定期做 compact,不需要的旧对话不要一直带着跑。
稳定系统提示前缀 — 系统提示、角色设定写完就别动,静态内容放前面,动态内容放后面,缓存命中率会明显提升。
工具输出先过滤 — 日志先 grep 出关键行,文件先提取关键段,再送给模型。别让模型"看全文"。
建立模型分层 — 格式转换、分类任务用小模型,需要深度推理的任务再用大模型。贵的模型留给真正值钱的问题。
高频任务模板化 — 反复做的事情,沉淀成 Skill 或模板,不要每次从头推理。
做好这五件事,Token 消耗降 30%~50% 不是难事。
说到底,Token 优化是 AI 能不能规模落地的基础
现在很多人用 AI Agent 还处在"尝鲜"阶段,成本高点无所谓,觉得值。
但当 AI Agent 真正成为工作流的一部分,每天、每周、每月持续运行,成本就从"可以忽略"变成了"必须优化"。
Token 优化不是省小钱,是决定 AI 应用能不能在企业里跑通的基础能力。
那些在早期就把这个问题想清楚的团队,会有很大的优势
如果你也在用 OpenClaw 或者搭 AI Agent,用量开始上来了,不妨了解一下 HAI 的 API 服务——多模型统一入口,账单透明可追踪,按需付费,不预充不浪费,是目前对开发者比较友好的选择之一。
如果想进一步了解大模型 API 服务以及 AI 应用落地的一些实践案例,可以参考一些聚合型 AI 平台的资料,比如 hai.network,里面整理了不少不同模型的接口和使用方式。
Build with HAI - 访问hai.network,一站接入全球顶尖模型