OpenVINO™ 2026.0 重磅发布:更多新模型、更强 GenAI、压缩更智能
 openlab_96bf3613
更新于 21天前
openlab_96bf3613
更新于 21天前
作者:武卓
2026 年马年新年已至,也欢迎体验 OpenVINO™本年度的首个版本发布!随着 AI 持续快速演进,我们始终致力于为开发者提供所需工具,帮助大家在英特尔硬件上高效落地这些创新。OpenVINO™ 2026.0 以更丰富的模型支持、GenAI 能力增强以及更出色的压缩优化,为新一年强势开局。无论你是在部署对话式 AI、构建 Agentic 系统,还是打造自主机器人,OpenVINO™都能作为底座,把这些想法变成加速、可量产、可上线的解决方案。下面就让我们一起看看有哪些更新。
目录
新模型: 混合专家模型
从流水线升级到投机解码
以更智能量化实现高级压缩
新模型:混合专家模型
此次发布为 AI 社区涌现出的更多主流模型带来了支持,并已针对 Intel CPU、GPU 和 NPU 进行了优化。最值得关注的是,混合专家(Mixture of Experts,MoE)架构支持从预览版走向了正式可用,适用于 GPT-OSS-20B 和 Qwen3-30B-A3B 等模型。这类模型在每次推理时只激活部分参数,能够以更低的计算成本实现接近大模型的效果。我们还新增了对 MiniCPM-o-2.6 的支持。这是一款高效的端到端多模态模型,可同时处理文本、图像和音频。
在视觉语言模型方面,Qwen2.5-VL-7B-Instruct 和 MiniCPM-V-4.5-8B 提供了视觉理解与指令跟随能力,可用于从视觉问答到文档分析等多种应用场景。上述模型支持在 CPU 和 GPU 上运行,其中 MiniCPM-o-2.6 还支持在 NPU 上运行。我们还进一步扩展了 NPU 支持,新增包括 Qwen2.5-1B-Instruct、Qwen3-Embedding-0.6B 和 Qwen-2.5-coder-0.5B 在内的模型支持,使你能够以显著提升的速度和能效,高性能地完成文本生成、代码补全和语义嵌入等任务。
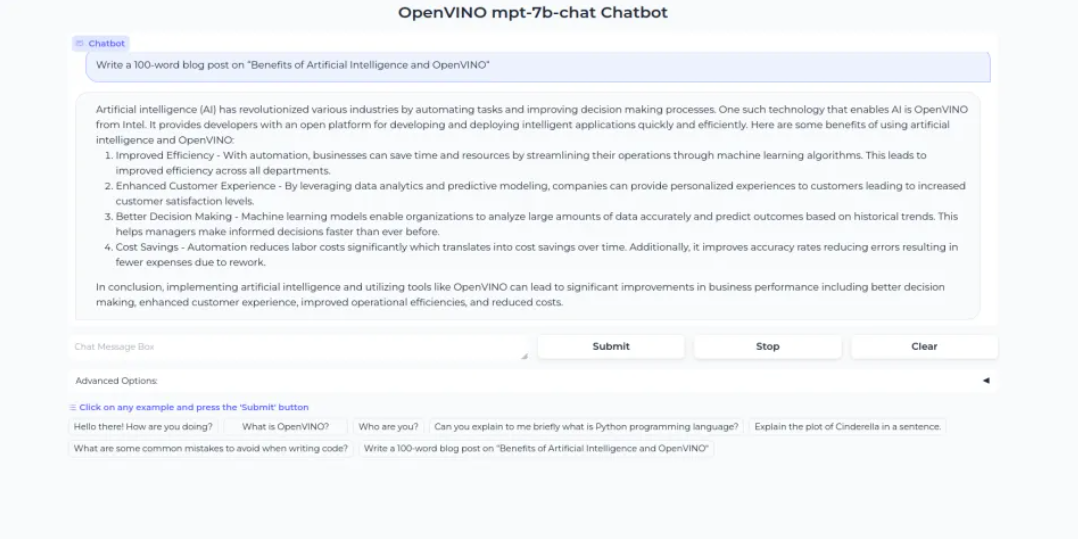
快来尝试使用 OpenVINO™构建基于LLM的聊天机器人中的GPT-OSS-20B 以及Qwen3-30B-A3B模型
从流水线升级到投机解码
OpenVINO™ GenAI 持续扩展能力边界,带来了强大的新特性与性能优化。
在语音应用方面,我们为 Whisper pipeline 新增了“词级时间戳(word-level timestamp)”功能,并已覆盖 CPU、GPU 和 NPU,与 OpenAI 和 FasterWhisper 的实现保持一致。该功能对于需要精确转录对齐、自动字幕生成以及细粒度语音分析的应用非常有帮助。此外,VLM 流水线支持进一步增强了现有的智能体AI( Agentic AI) 集成能力;chat_history 功能现已扩展为可处理图像和视频项,从而支持构建更复杂的多模态对话智能体。
pipe = openvino_genai.Text2VideoPipeline(arg***odel_dir, "CPU") # GPU can be used as wellframe_rate = 25def callback(step, num_steps, latent):print(f"Generation step {step + 1} / {num_steps}")return Falseoutput = pipe.generate(args.prompt,negative_prompt="worst quality, inconsistent motion, blurry, jittery, distorted",height=480,width=704,num_frames=161,num_inference_steps=25,num_videos_per_prompt=1,callback=callback,frame_rate=frame_rate,guidance_scale=3,)save_video("genai_video.avi", output.video, frame_rate)
OpenVINO™ GenAI 早已在 CPU 和 GPU 上支持投机解码(speculative decoding):由轻量级草稿模型先生成 token,再由完整模型周期性校验,从而实现高效文本生成。在此次发布中,我们也将这一能力带到了 NPU,使你的模型现在能够以更高能效运行。与此配套,Phi-3-mini FastDraft 模型现已在 Hugging Face 上提供,用于加速 NPU 上的 LLM 推理。我们还新增了对 EAGLE-3 投机解码的支持,以加速 CPU 和 GPU 上的 LLM 推理;在 Qwen3-8B 上的验证显示其吞吐量有显著提升。与传统投机解码需要单独草稿模型不同,EAGLE-3 在主模型内部直接加入一个小型预测组件,使其能够同时预测多个可能的下一个 token,并且相比传统投机解码方法具有更高的准确性。
以更智能量化实现高级压缩
高效的模型部署离不开先进的压缩技术,而此次发布在神经网络压缩框架(NNCF)方面带来了重要进展。我们引入了面向3D 矩阵乘(3D MatMul)的INT4 数据感知权重压缩(data-aware weight compression),专门用于优化 MoE 大语言模型(LLM)。该技术在降低内存占用和带宽需求的同时,相比无数据压缩方案(data-free compression)能够更好地保持精度。此外,NNCF 现已支持 FP8-4BLUT 量化中的逐层(per-layer)和逐组(per-group)查找表(LUT, Look-Up Table)。这使得基于码本(codebook-based)的细粒度压缩成为可能,在减小模型体积和带宽占用的同时,还能提升 LLM 和 Transformer 工作负载的推理速度与精度。这些压缩技术让在内存和算力资源有限的设备上部署更大模型变得更加容易。
小结
OpenVINO™ 2026.0 体现了我们持续推动生成式 AI 在英特尔硬件产品组合上实现更易用、更高性能、更多样化的承诺。凭借新模型、先进的 GenAI 流水线 以及智能压缩技术,此次发布为你提供了构建和部署高性能 AI 应用所需的关键工具。我们非常期待看到你利用这些新能力创造出怎样的应用。欢迎立即下载 OpenVINO™ 2026.0!
OpenVINO™ DevCon中国系列工作坊 2025回放也同样为您准备好了,欢迎前往回看、了解一系列精彩主题,包括 AI 助手、Hugging Face、机器人技术(Robotics)以及 Agentic AI。
声明与免责声明
*其他名称和品牌可能归其各自所有者所有。
性能因使用场景、配置及其他因素而异。更多信息请参阅性能指标网站。
性能结果基于配置中所示日期的测试,可能未反映所有公开可用的更新。
任何产品或组件都无法做到绝对安全。
你的成本和结果可能会有所不同。
英特尔技术可能需要启用相应硬件、软件或服务激活。
© Intel Corporation。Intel、Intel 标识及其他 Intel 标志均为 Intel Corporation 或其子公司的商标。
OpenVINO 小助手微信: OpenVINO-China
如需咨询或交流相关信息,欢迎添加OpenVINO小助手微信,加入专属社群,与技术专家实时沟通互动。