在英特尔® 硬件上加快推理速度的几个步骤
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
前言
为了支持云开发人员从云端到边缘测的旅程,英特尔构建了多个开发工具加速开发流程。我们将在本博文中介绍其中三个开发工具。您可以使用 AWS SageMaker 在 AWS 云中构建和训练模型,然后使用 OpenVINO™ 工具套件模型优化器优化这些模型。优化后,您将能够在英特尔® DevCloud 中,基于各类英特尔®硬件对模型进行性能指标评测。最后,我们将介绍如何搭建基于英特尔® OpenVINO™ 工具套件分发版和 AWS Greengrass的边缘环境,以及如何使用AWS Greengrass Python Lambda服务,在边缘测部署利用英特尔® OpenVINO™ 工具套件分发版执行的图像分类和对象检测应用。
英特尔® OpenVINO™工具套件分发版概述
得益于 AI 领域的最新发展,开发人员如今在框架、模型和硬件方面有多种选择。然而,开发人员需要使用正确的硬件及其相关软件,才能够充分利用底层硬件算力,提高AI推理性能。英特尔® OpenVINO™ 工具套件分发版就是这样一款加速工具,借助预优化的模型,它可帮助开发人员最大限度提高推理性能。具体而言,英特尔® OpenVINO™ 工具套件分发版是一款全面的工具套件,支持开发人员快速开发可模拟人类视觉的AI应用和解决方案。基于卷积神经网络 (CNN),该工具套件可将计算机视觉工作负载扩展至各类英特尔® 硬件,并实现卓越性能。更多信息请访问 OpenVINO™ 工具套件概述。
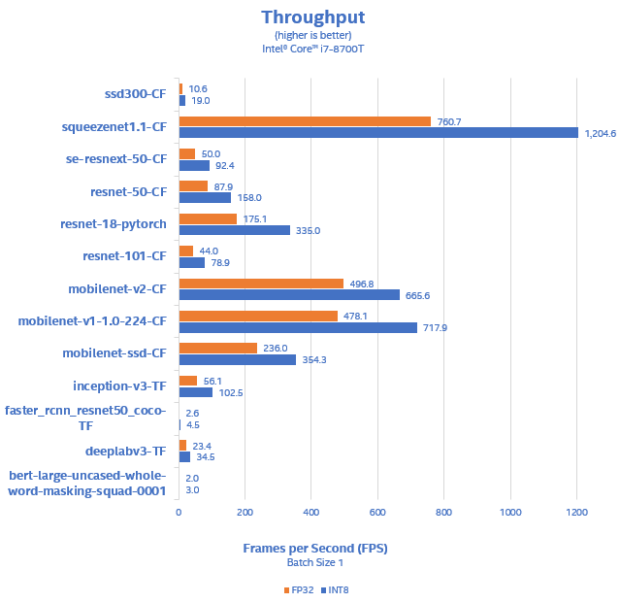
硬件方面,英特尔提供 CPU、VPU 和 FPGA 等可扩展的产品组合,能够充分满足您AI推理解决方案的需求。表 1 向我们展示了英特尔® 酷睿® i7 处理器的高性能输出。您可以看到使用英特尔® OpenVINO™ 工具套件分发版后,对于某些模型,可实现高达每秒 1200 帧的性能。更多信息请访问系统配置和更多性能指标评测。
了解如何在 AWS SageMaker 中使用 OpenVINO™ 工具套件模型优化器
现在,我们将介绍如何在 AWS SageMaker 中使用 OpenVINO™ 工具套件模型优化器轻松优化模型。为帮助您轻松进行模型优化,我们开发了 python 函数,该函数简化并实现了内联模型转换。它使用 OpenVINO™ 工具套件 docker 容器来转换 TensorFlow 和 Keras 模型(当前,英特尔® OpenVINO™ 工具套件分发版仅支持部分 Tensorflow Hub 和 Keras App模型)。利用OpenVINO中间表示格式IR,您只需编写一次推理代码,即可使用这些从不同框架转换的IR格式模型。为方便起见,我们提供了支持的 TFHub 模型及其input shape。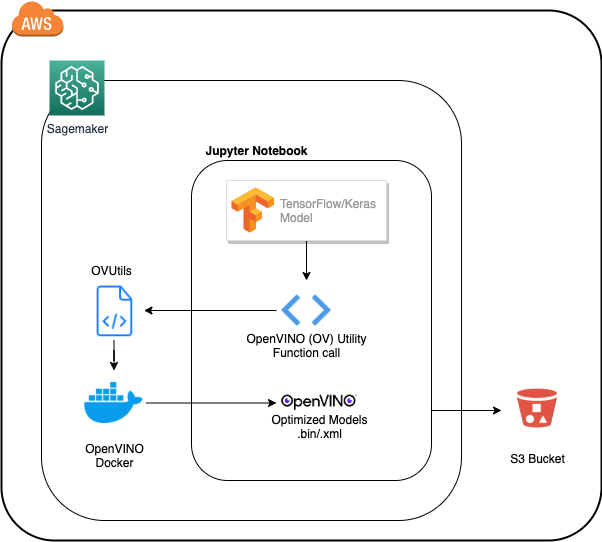
立即开始
1. 创建一个 SageMaker Notebook 并将 Github repo 克隆到您的 SageMaker Notebook 实例
2.打开 SageMaker Notebook,转向 aw*****o-utility 目录
3.转向 aw*****o-utility 目录后,您将看到以下文件:
|
|
|
|
create_ir_for_keras.ipynb |
|
|
create_ir_for_tfhub.ipynb |
|
|
create_ir_for_obj_det.ipynb |
|
|
ov_utils.py |
|
|
TFHub-SupportedModelList.md |
|
|
Keras-SupportedModelList.md |
|
|
ObjDet-SupportedModelList.md |
|
|
TFHub-TF1-SupportedModelList.pdf |
|
|
TFHub-TF2-SupportedModelList.pdf |
|
|
Keras-SupportedModelList.pdf |
|
|
ObjDet-SupportedModelList.pdf |
|
|
requirements.txt |
|
|
README.md |
README file |
|
ov-utils-arch.png |
|
- 将 Keras App模型转换为 OpenVINO™ IR 的流程一览
- 将 Tensorflow Hub模型转换为 OpenVINO™ IR 的流程一览
- 将对象检测模型转换为 OpenVINO™ IR 的流程一览
在下一节中,我们将探讨如何使用面向边缘的英特尔® DevCloud对模型在各类英特尔® 硬件上的性能指标进行评测。
英特尔® DevCloud,一键使用/零成本,评估深度学习模型在各类英特尔®硬件上的推理性能
您是否想知道您的模型在不同英特尔® 硬件上的性能如何?英特尔提供了设备沙盒英特尔® DevCloud,可帮助您在最新的英特尔® 硬件系列中免费开发、测试和运行您的工作负载。在一站式访问所有最新英特尔® 硬件的同时,您也需要了解哪款英特尔® 硬件最适合您的应用。为此,我们提供英特尔® DevCloud这一强大的工具,帮助您明确哪款硬件最适合您的深度学习模型。
在上一节中,您已经了解了如何将 TensorFlow 和 Keras 图像分类模型,以及 TensorFlow 对象检测模型,转换为 OpenVINO IR中间表示格式,并将其存储在 S3 存储桶中。
在本节中,您将了解如何直接从 S3 存储桶中获取 OpenVINO IR 模型,并使用提供的Jupyter notebook示例,借助英特尔® DevCloud 在不同硬件上对您的模型进行一键式性能指标评测。
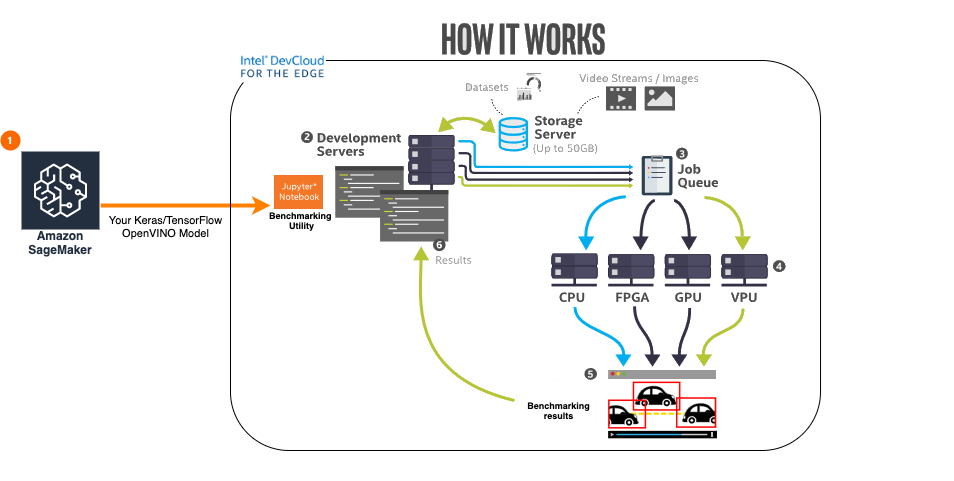
想要基于您的模型进行尝试?请查看英特尔® DevCloud性能指标评测示例。您只需提供 AWS 凭证和 S3 存储桶,我们就会为您从 S3 存储桶中提取模型。
Jupyter Notebook示例概览
在运行了Jupyter Notebook中的所有单元之后,您将通过详细的输出表格,了解到模型在哪种硬件上可实现最佳性能,类似于以下内容: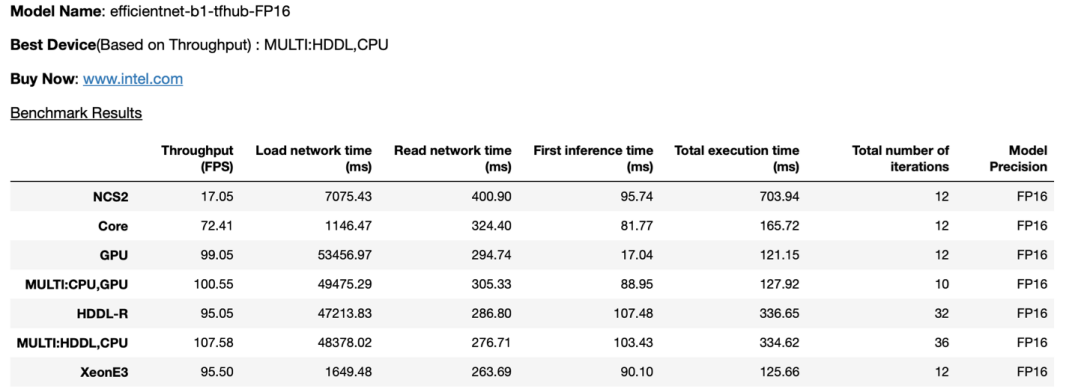
下一步:
在下一节中,我们将讨论如何使用英特尔®边缘软件中心部署部署推理应用和 OpenVINO™ 模型
使用英特尔®边缘软件中心部署推理应用和 OpenVINO™ 模型
现在,您已经在多个英特尔®硬件上对模型进行了性能指标评测,接下来,您需要在边缘端部署模型,这正是英特尔®边缘软件中心的用武之地。英特尔® 边缘软件中心能够帮助开发人员更快速、更放心地配置、验证和部署针对特定用例的解决方案。
英特尔的边缘软件中心提供丰富的参考实现与用例,能够为您带来便捷简易的开发体验。Amazon Web Services(AWS)*云端到边缘管道就是这样的一个用例。该用例可帮助您一键部署及使用从云端到边缘端的推理管道。该管道在边缘测使用 AWS IoT Greengrass 和 OpenVINO™ 工具套件,在云端使用 AWS IoT服务。通过使用 AWS Greengrass 中包含的功能,您可以将应用部署到多个边缘设备。该用例还包括用于图像分类和对象检测的AWS IoT Greengrass Lambda示例。
工作原理
该用例使用了英特尔® OpenVINO™ 工具套件分发版中包含的推理引擎,能够帮助云开发人员在英特尔边缘设备上部署AI推理应用并获得优化性能。 同时,利用AWS Greengrass,可以将视觉分析负载从云端安全无缝地迁移到边缘。
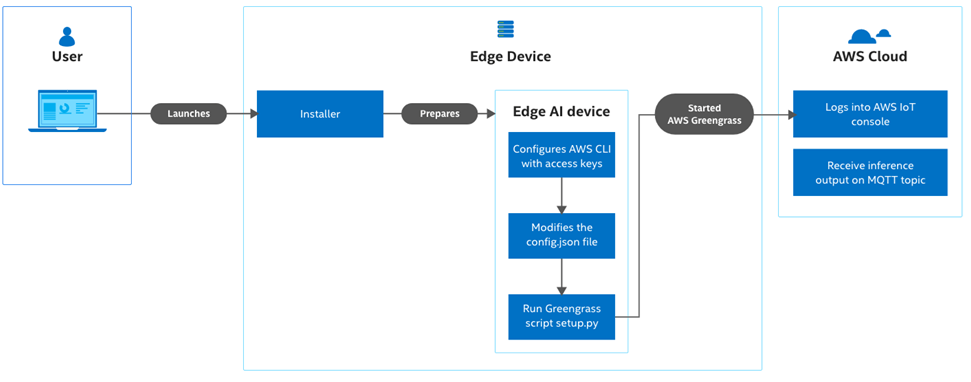
立即开始
准备好在边缘测部署AI推理?从英特尔®边缘软件中心下载 Amazon Web Services(AWS)*云端到边缘管道。下载此用例后,请遵循文档建立云端到边缘的管道并进行边缘推理。