开发者实战 | 如何在 Windows 上调用 NPU 部署深度学习模型
 openlab_96bf3613
更新于 2年前
openlab_96bf3613
更新于 2年前
作者:杨亦诚
相信很多小伙伴都已经知道,在最新一代的Intel Core Ultra移动端处理中已经集成了被称为 NPU 的神经网络加速处理器,以提供低功耗的AI算力,特别适合于PC端需要长时间稳定运行的AI辅助功能,例如会议聊天软件中的自动抠像,或是画面超分辨率等应用。而 OpenVINO™ 工具套件也在第一时间对 NPU 进行了适配,接下来就让我们一起看一下如何在 Intel Core Ultra 处理器上搭建基础环境,并调用 NPU 进行模型推理任务。
· NPU 驱动安****>
首先我们需要确保是否安装了最新版的 NPU 驱动,可以通过 Windows 任务管理调出当前 NPU 驱动版本信息。
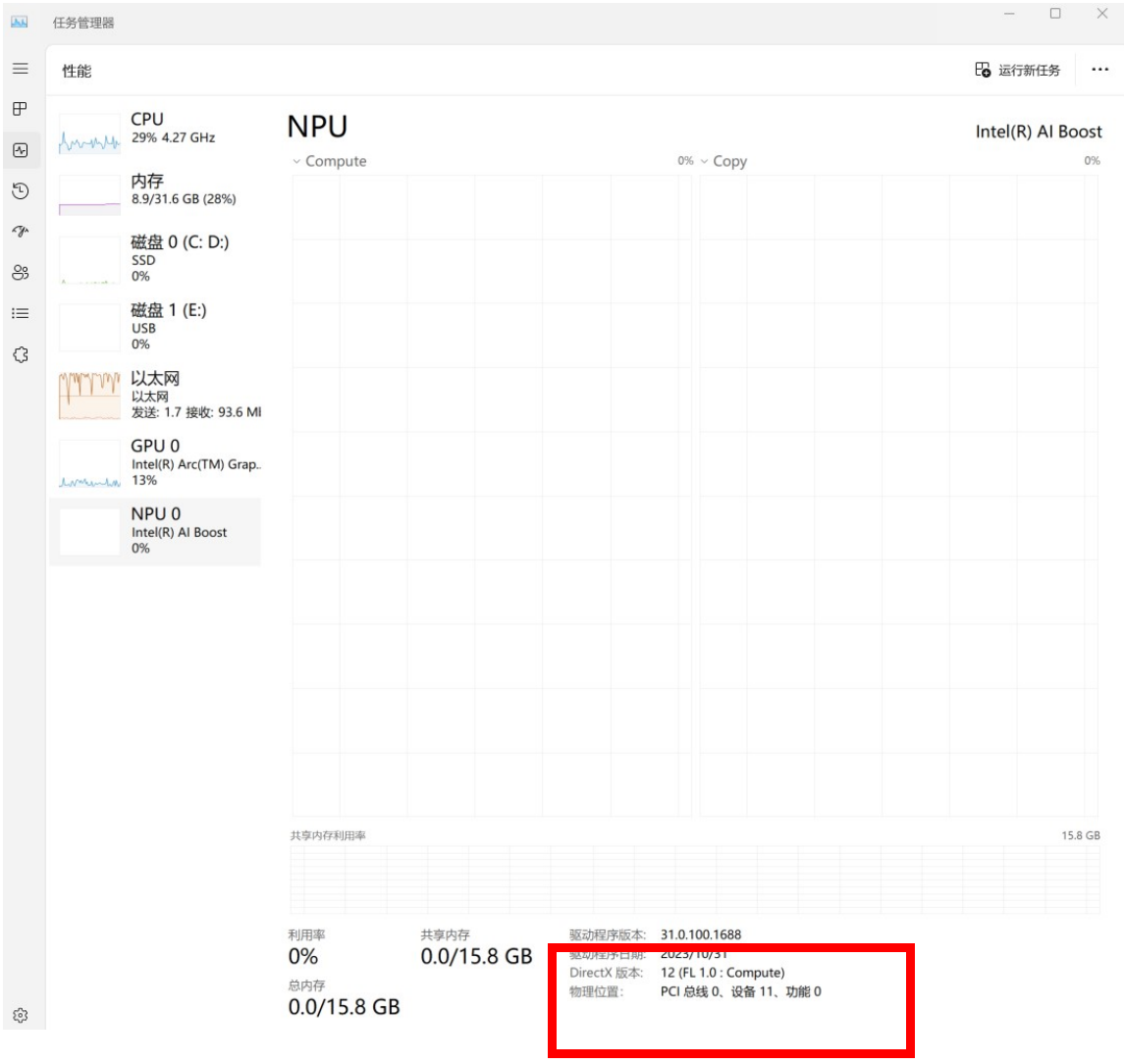
图:NPU在Windows任务管理器中显示驱动版本
查询当前最新的NPU驱动版本::
https://www.intel.com/content/www/us/en/download/794734/intel-npu-driver-windows.html
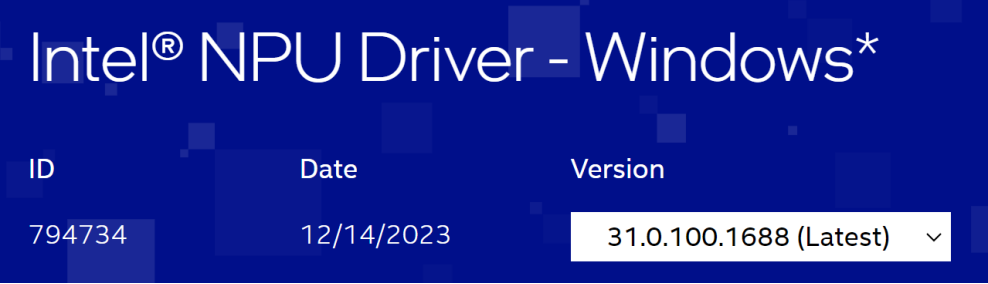
图:NPU驱动下载页面
如果想更新或是重装NPU驱动,可以参考以下指引下载并安装驱动:
https://docs.openvino.ai/2023.3/openvino_docs_install_guides_configurations_for_intel_npu.html
· OpenVINO™ 的下载和安****>
由于目前NPU Plugin还没有被集成在 OpenVINO™ 的 PyPI 安装包中,因此我们需要通过下载OpenVINO™ runtime压缩包的方式进行安装。
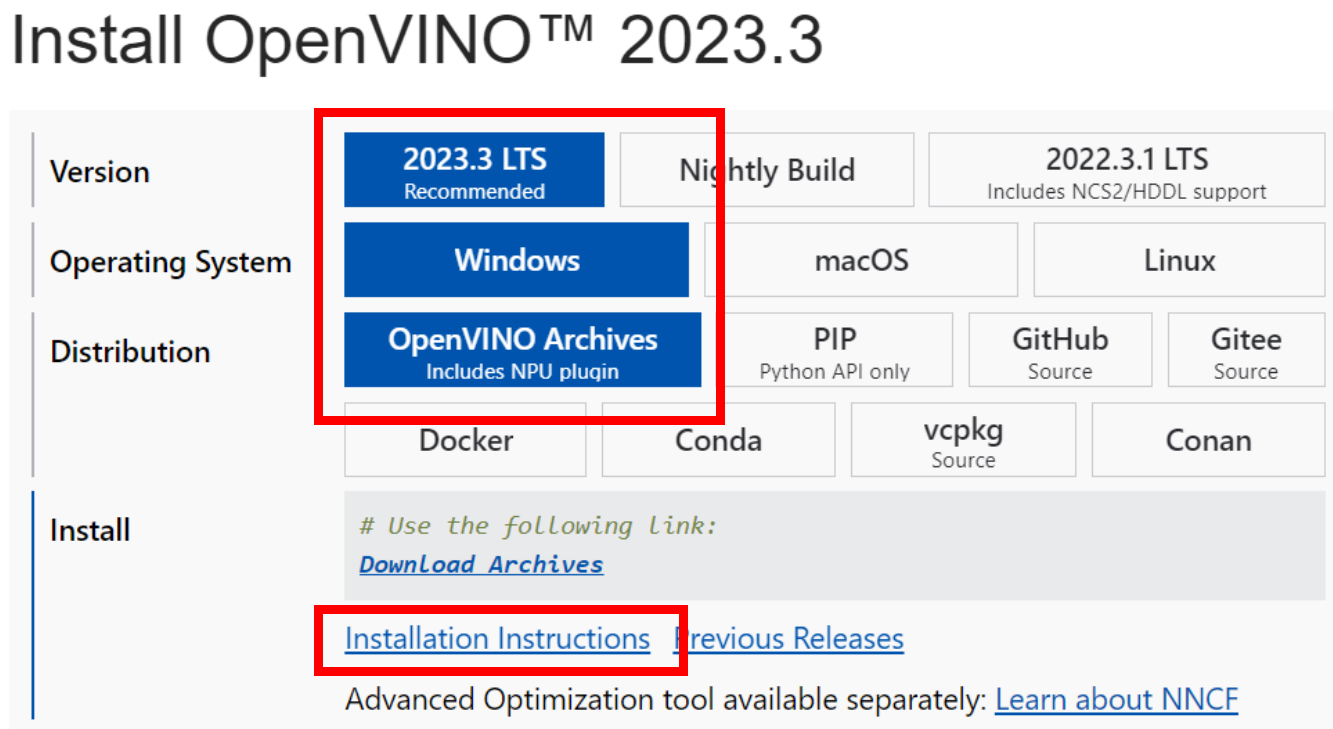
图:OpenVINO下载页面
整个安装过程非常简单,只需将压缩包解压到在本地路径下既可。具体方法可以参考上图标红处的安装说明。
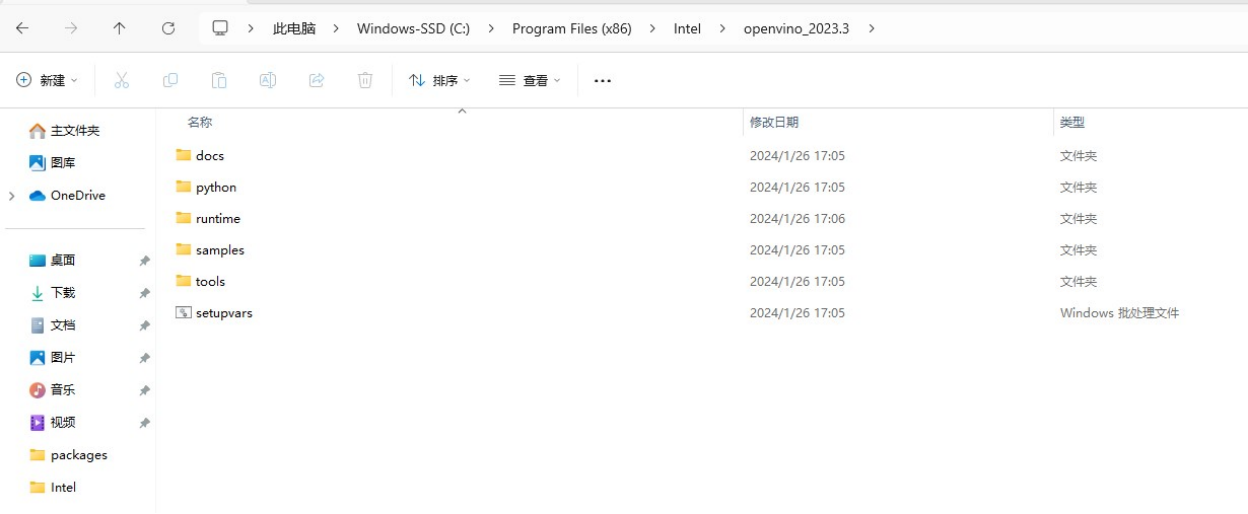
图:将压缩包解压至本地路径
· Python环境配置
通过执行压缩包中的setupvar***at环境配置脚本,我们便可以直接在Python环境下加载OpenVINO™ runtime和NPU Plugin环境。同时利用OpenVINO™ 的Python API指令,我们可以快速验证NPU是否可以被正常调用。
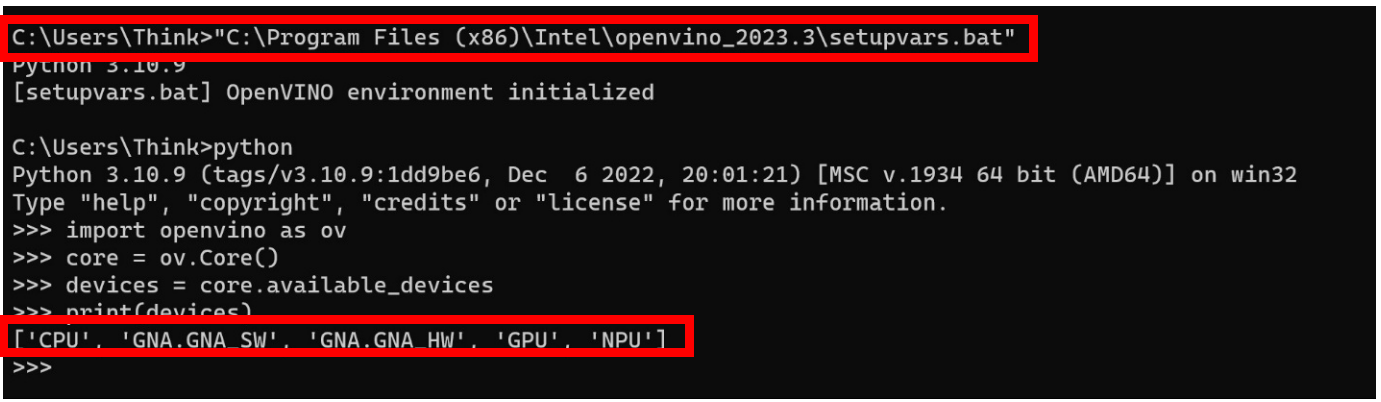
图:Python环境中验证NPU调用
· C++ 环境配置
不同于Python,Windows上的C++应用需要依赖于CMake或者是Visual Studio的环境下调试,因此这里我们需要简单配置下OpenVINO™ 库的路径。下面以Visual Studio中新建项目的属性配置页面为例。
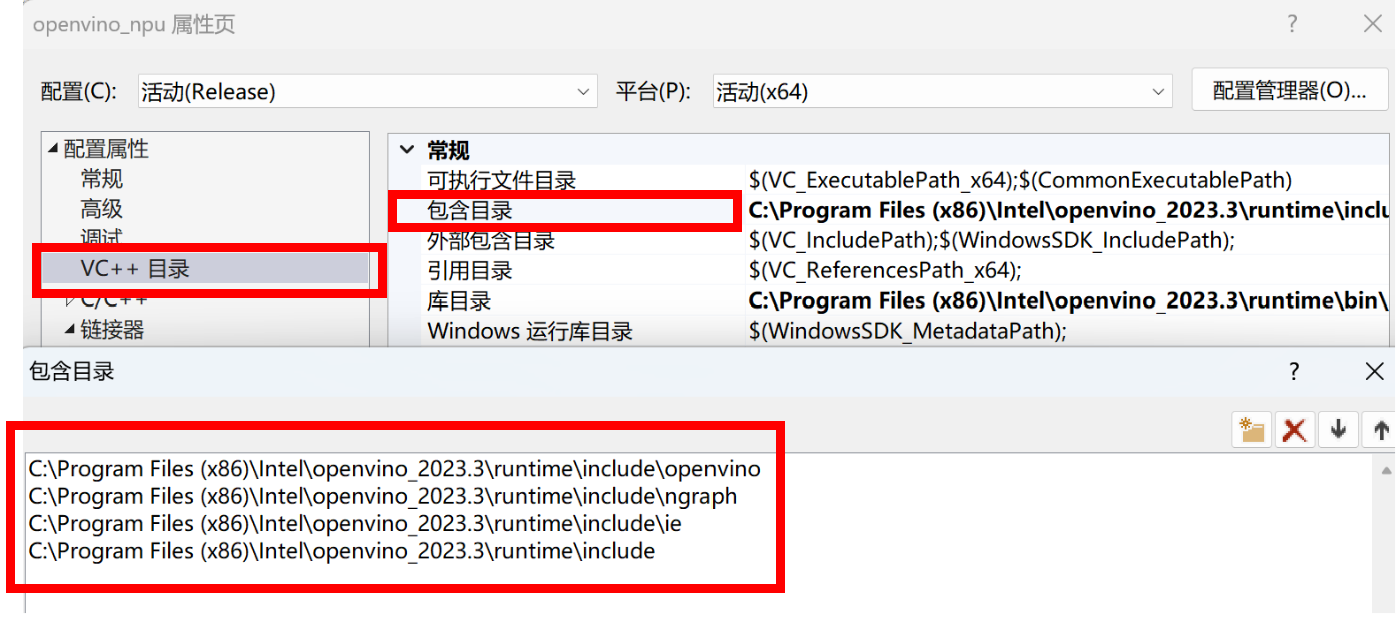
图:配置OpenVINO™ runtime头文件路径
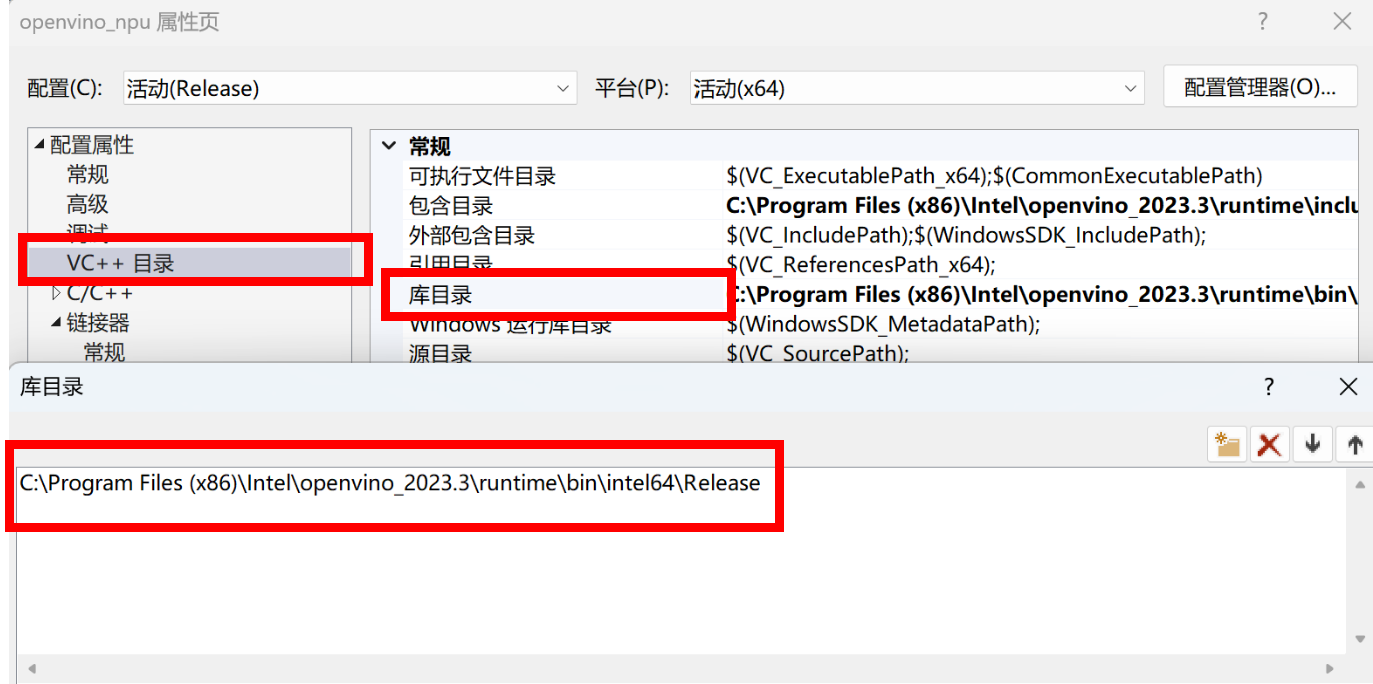
图:配置OpenVINO™ runtime动态库路径
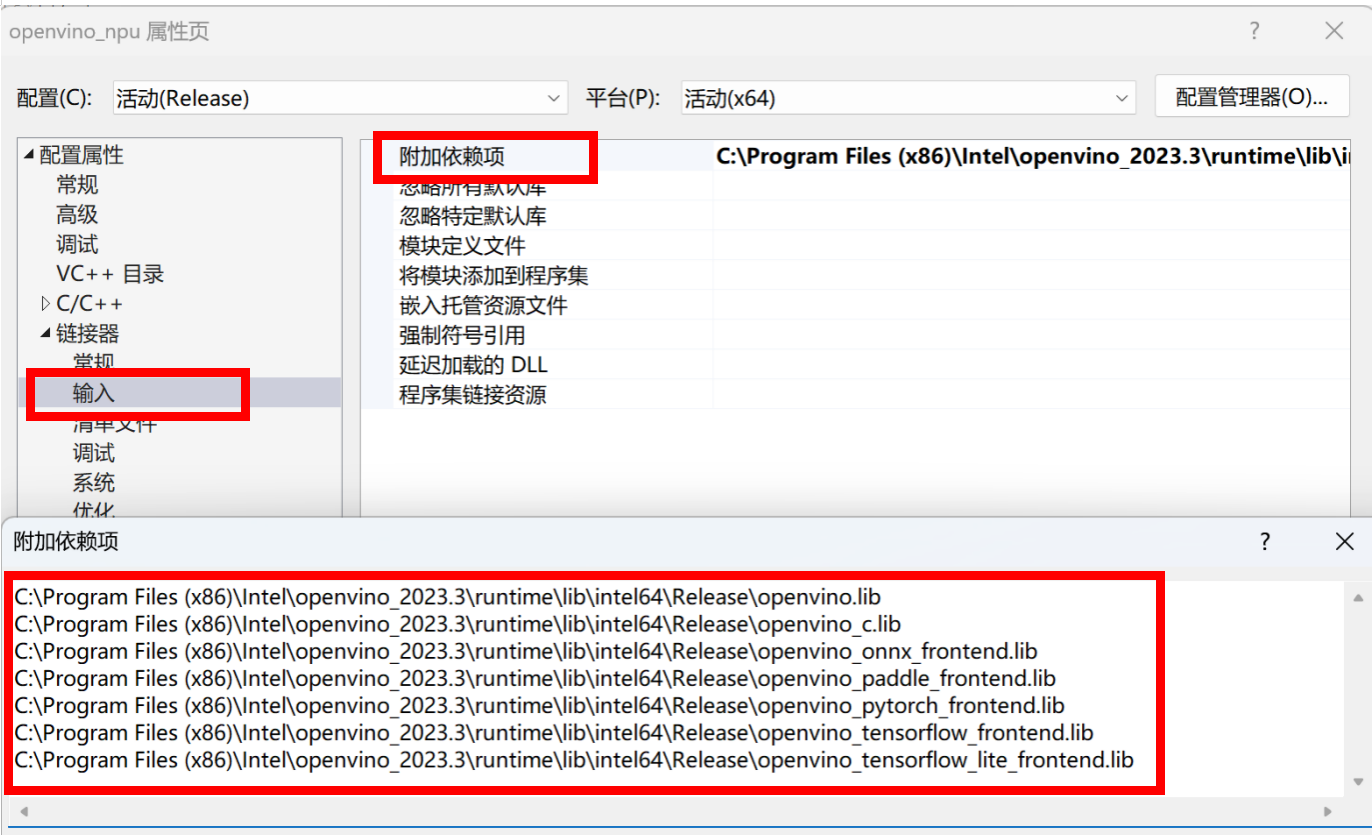
图:配置OpenVINO™ runtime及frontednd静态库路径
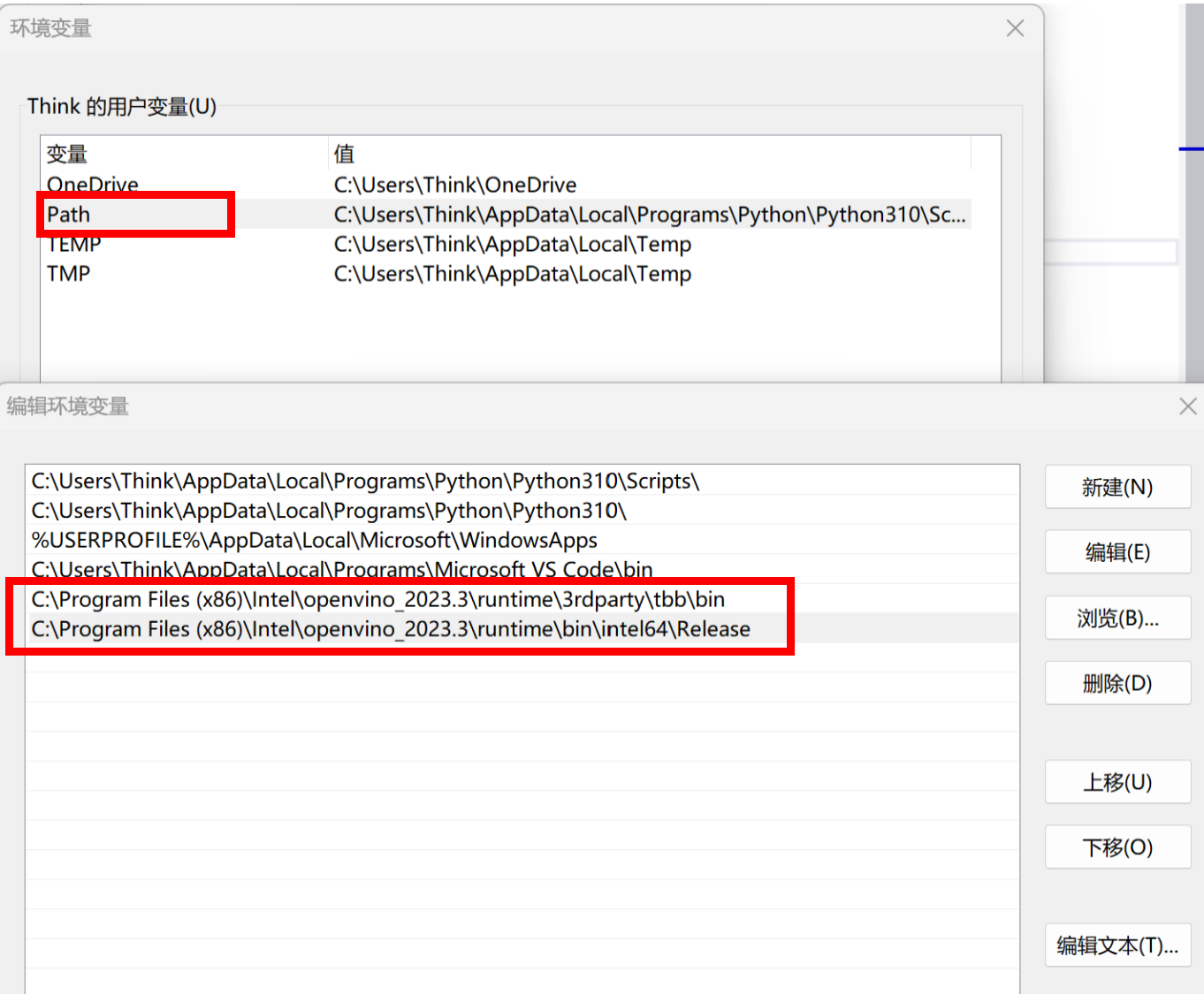
当完成Visual Studio项目属性配置后,我们可以通过调试以下示例代码,测试NPU是否可以被检测及调用。
#include <iostream>
#include <openvino/openvino.hpp>
int main(int argc, char* argv[]) {
// -------- Get OpenVINO runtime version --------
std::cout << ov::get_openvino_version() << std::endl;
// -------- Step 1. Initialize OpenVINO Runtime Core --------
ov::Core core;
// -------- Step 2. Get list of available devices --------
std::vector<std::string> availableDevices = core.get_available_devices();
// -------- Step 3. Query and print supported metrics and config keys --------
std::cout << "available devices: " << std::endl;
for (auto&& device : availableDevices) {
std::cout << device << std::endl;
}
} 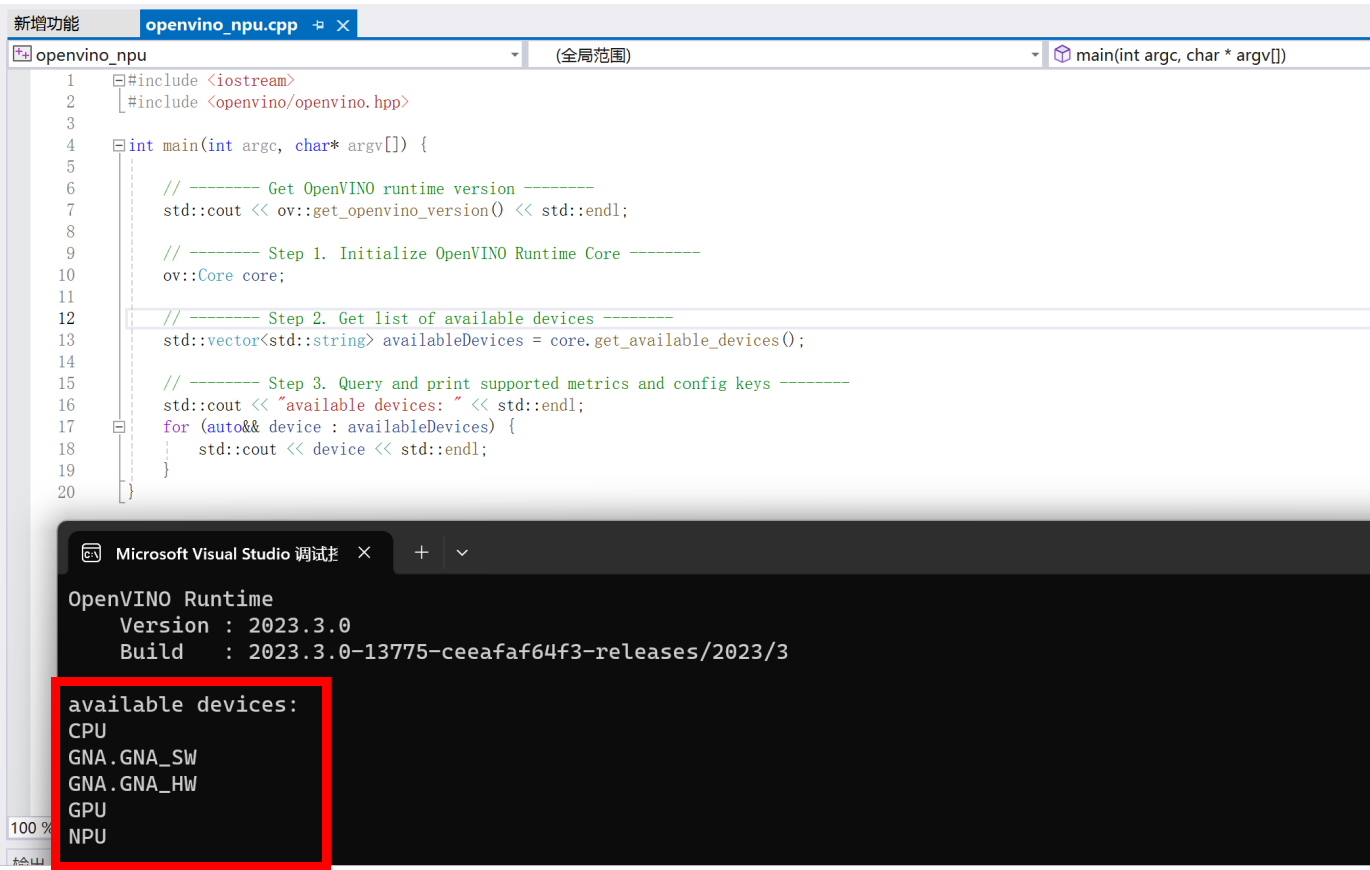
图:VS环境中验证NPU调用
· 测试效果
当完成NPU安装后,我们可以通过 OpenVINO™ notebooks 中提供的示例,简单测试下NPU的性能。这个示例会通过以下 Python 代码来将模型部署在 NPU 上。
compiled_model = core.compile_model("model.xml", "NPU") 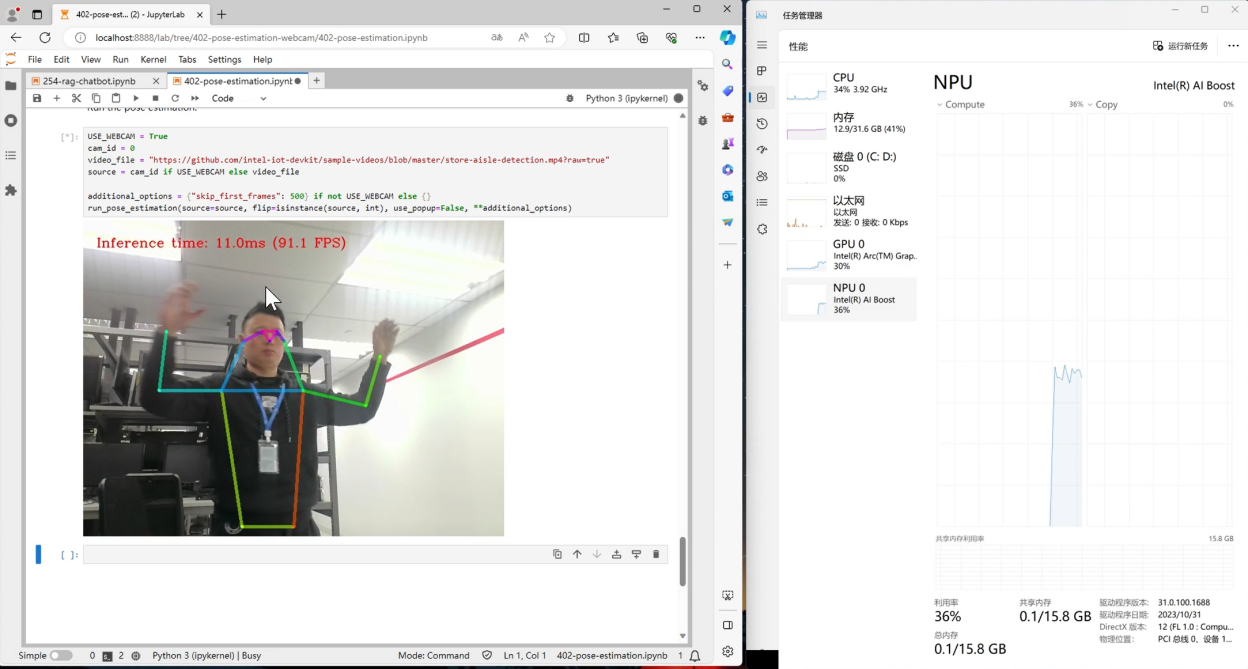
图:实时人体关键点演示效果
可以看到 NPU 在运行实时人体关键点检测模型时的效果和速度还是非常不错的,达到了90FPS的吞吐量,同时推理任务几乎也没有占用CPU额外的资源,真正做到了在提供高算力的同时,减轻CPU和GPU的任务负载。
· 参考资料:
1. OpenVINO™下载与安装方式:
2. NPU 环境配置:
https://docs.openvino.ai/2023.3/openvino_docs_install_guides_configurations_for_intel_npu.html
3. OpenVINO™ notebooks示例:
https://github.com/openvinotoolkit/openvino_notebooks