如何利用低比特量化技术进一步提升大模型推理性能
 openlab_4276841a
更新于 2年前
openlab_4276841a
更新于 2年前
作者:杨亦诚
针对大语言模型(LLM)在部署过程中的性能需求,低比特量化技术一直是优化效果最佳的方案之一,本文将探讨低比特量化技术如何帮助LLM提升性能,以及新版OpenVINO™ 对于低比特量化技术的支持。
· 大模型性能瓶颈
相比计算量的增加,大模型推理速度更容易受到内存带宽的影响(memory bound),也就是内存读写效率问题,这是因为大模型由于参数量巨大、访存量远超内存带宽容量,意味着模型的权重的读写速度跟不上硬件对于算子的计算强度,导致算力资源无法得到充分发挥,进而影响性能。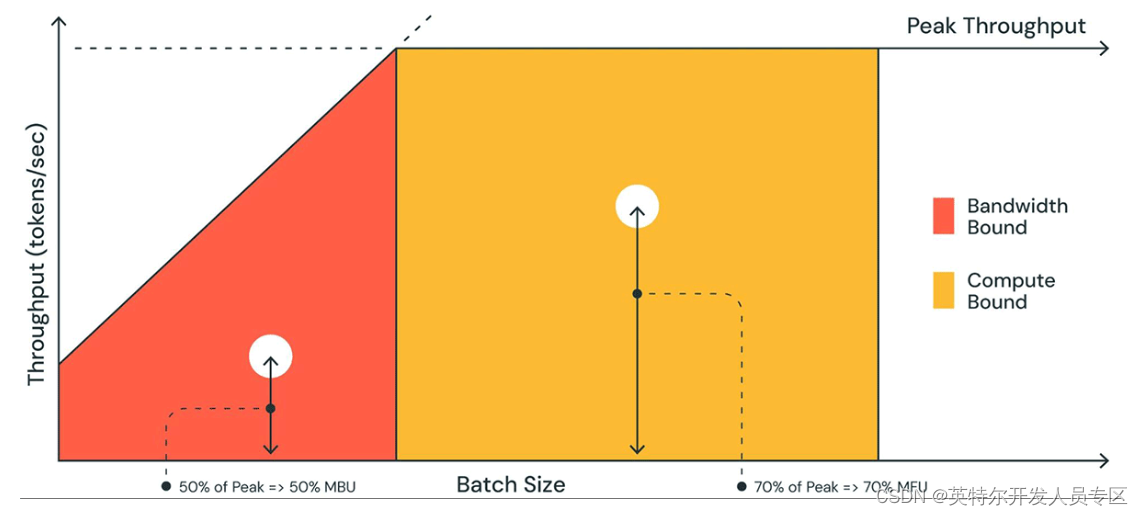
图:memory bound与compute bound比较
· 低比特量化技术
低比特量化技术是指将模型参数从fp32/fp16压缩到更低的比特位宽表达,在不影响模型输出准确性和参数量的情况下,降低模型体积,从而减少缓存对于数据读写的压力,提升推理性能。由于大模型中单个layer上的权重体积往往要远大于该layer的输入数据(activation),因此针对大模型的量化技术往往只会针对关键的权重参数进行量化 (WeightOnly),而不对输入数据进行量化,在到达理想的压缩比的同时,尽可能保证输出结果,实现最高的量化“性价比”。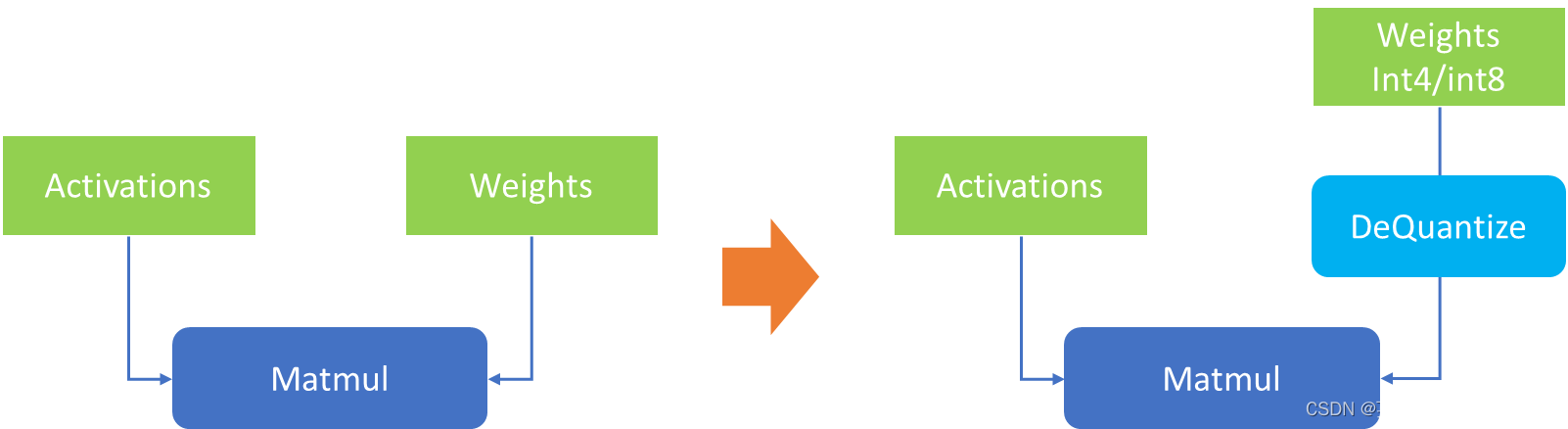
图:权重压缩示意
经验证常规的int8权重量化,对大模型准确性的影响极低,而为了引入像int4,nf4这样的更极致的压缩精度,目前在权重量化算法上也经过了一些探索,其中比较典型的就是GPTQ算法,简单来说,GPTQ 对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。GPTQ 量化需要准备校准数据集,因此他也是一种PTQ (Post Training Quantization)量化技术。
· OpenVINO™ 2023.2对于int4模型的支持
OpenVINO™ 2023.2相较2023.1版本,全面引入对int4模型以及量化技术的支持。主要有以下2个方面:1. CPU及iGPU支持原生int4模型推理

图:经NNCF权重压缩后的模型结构
2. NNCF工具支持int4的混合精度量化策略(Weights Compression)
刚提到的GPTQ是一种data-based的量化方案,需要提前准备校验数据集,借助HuggingFace的Transformers和AutoGPTQ库可以完成这一操作。而为了帮助开发者缩短LLM模型的压缩时间,降低量化门槛,NNCF工具在2.7.0版本中引入了针对int4以及nf4精度的权重压缩模式,这是一种data-free的混合精度量化算法,无需准备校验数据集,仅对LLM中的Linear 和Embedding layers展开权重压缩。整个过程仅用一行代码就可以完成:
compressed_model = compress_weight***odel, mode=CompressWeightsMode.NF4, group_size=64, ratio=0.9) 其中model为PyTorch或OpenVINO™的模型对象;mode代表量化模式,这里可以选择CompressWeightsMode.NF4,或是CompressWeightsMode.INT4_ASYM/INT4_SYM等不同模式;为了提升量化效率,Weights Compression使用的是分组量化的策略(grouped quantization),因此需要通过group_size配置组大小,例如group_size=64意味64个channel的参数将共享同一组量化参数(zero point, scale value);此外鉴于data-free的int4量化策略是比带来一定的准确度损失,为了平衡模型体积和准确度,Weights Compression还支持混合精度的策略,通过定义ratio值,我们可以将一部分对准确度敏感的权重用int8表示,例如在ratio=0.9的情况下,90%的权重用int4表示,10%用int8表示,开发者可以根据量化后模型的输出结果调整这个参数。
在量化过程中,NNCF会通过搜索的方式,逐层比较伪量化后的权重和原始浮点权重的差异(https://github.com/openvinotoolkit/nncf/blob/5eee3bc293da2e94b30cb8dd19da9f20fce95f02/nncf/quantization/algorithms/weight_compression/openvino_backend.py#L409C5-L409C5),衡量量化操作对每个layer可能带来的误差损失,并根据排序结果以及用户定义的ratio值,将损失相对较低的权重压缩到int4位宽。
· 中文大语言模型实践
随着OpenVINO™ 2023.2的发布,大语言模型的int4压缩示例也被添加到了openvino_notebooks仓库中(https://github.com/OpenVINO-dev-contest/openvino_notebooks/tree/main/notebooks/254-llm-chatbot),这次特别新增了针对中文LLM的示例,包括目前热门模型ChatGLM2和Qwen。在这个notebook中,开发者可以体验如何从HuggingFace的仓库中导出一个OpenVINO™ IR格式的模型,并通过NNCF工具进行低比特量化,最终完成一个聊天机器人的构建。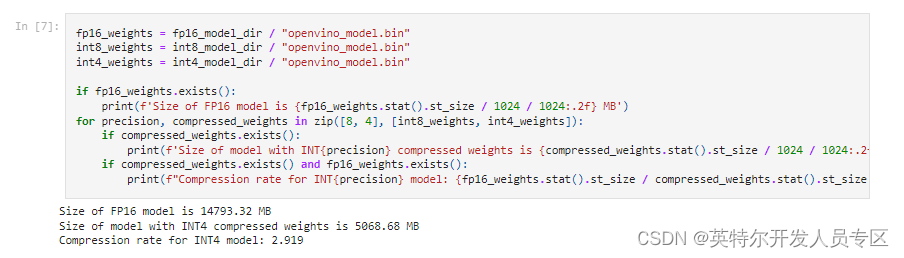
图:fp16与int4模型空间占用比较
通过以上这个截图可以看到,qwen-7b-chat经过NNCF的int4量化后,可以将体积压缩到原本fp16模型的1/3,这样使得一台16GB内存的笔记本,就可以流畅运行压缩以后的ChatGLM2模型。此外我们还可以通过将LLM模型部署在酷睿CPU中的集成显卡上,在提升性能的同时,减轻CPU侧的任务负载。
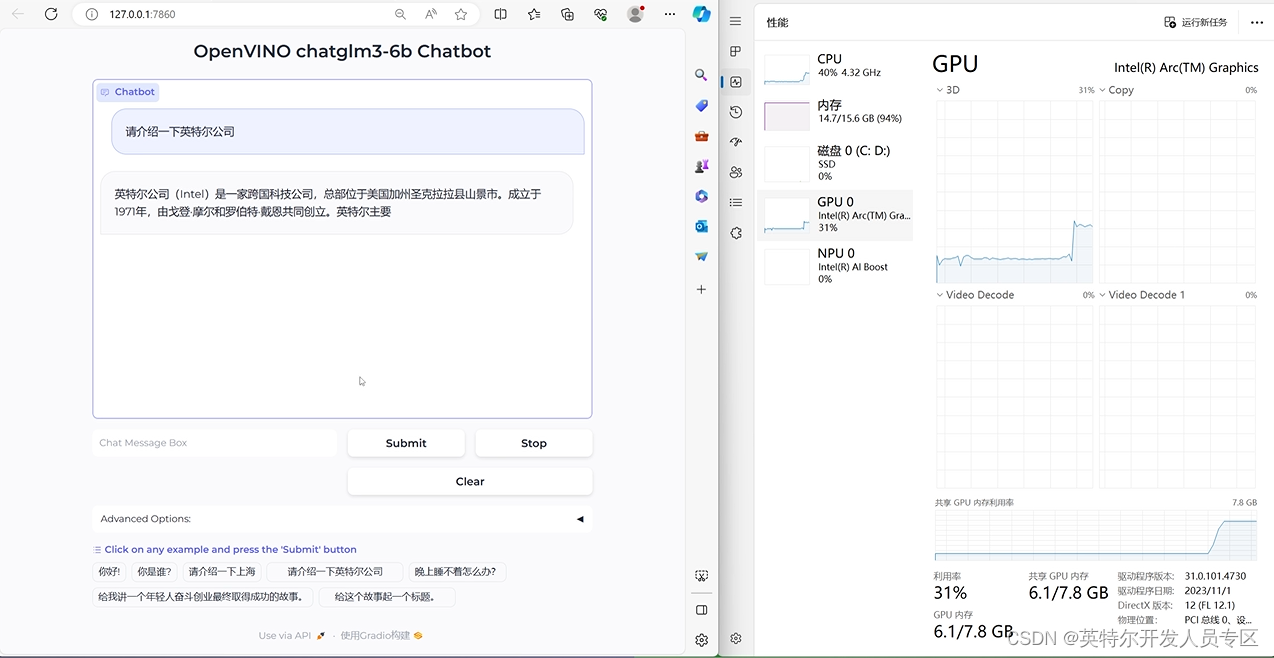
图:Notebook运行效果