OpenVINO C# API 部署 RT-DETR 模型
 openlab_4276841a
更新于 2年前
openlab_4276841a
更新于 2年前
作者:颜国进 英特尔边缘计算创新大使
RT-DETR是在DETR模型基础上进行改进的,一种基于 DETR 架构的实时端到端检测器,它通过使用一系列新的技术和算法,实现了更高效的训练和推理,在前文我们发表了《基于 OpenVINO™ Python API 部署 RT-DETR 模型 | 开发者实战》(基于 OpenVINO™ Python API 部署 RT-DETR 模型 | 开发者实战)和《基于 OpenVINO™ C++ API 部署 RT-DETR 模型 | 开发者实战》(基于 OpenVINO™ C++ API 部署 RT-DETR 模型 | 开发者实战),在该文章中,我们基于OpenVINO™ Python 和 C++ API 向大家展示了的RT-DETR模型的部署流程,并分别展示了是否包含后处理的模型部署流程,为大家使用RT-DETR模型提供了很好的范例。在实际工业应用时,有时我们需要在C#环境下使用该模型应用到工业检测中,因此在本文中,我们将向大家展示使用OpenVINO Csharp API 部署RT-DETR模型,并对比不同编程平台下模型部署的速度。
该项目所使用的全部代码已经在GitHub上开源,并且收藏在OpenVINO-CSharp-API项目里,项目所在目录链接为:
https://github.com/guojin-yan/OpenVINO-CSharp-API/tree/csharp3.0/tutorial_example***r/>也可以直接访问该项目,项目链接为:
https://github.com/guojin-yan/RT-DETR-OpenVINO.git
1. RT-DETR
飞桨在去年 3 月份推出了高精度通用目标检测模型 PP-YOLOE ,同年在 PP-YOLOE 的基础上提出了 PP-YOLOE+。而继 PP-YOLOE 提出后,MT-YOLOv6、YOLOv7、DAMO-YOLO、RTMDet 等模型先后被提出,一直迭代到今年开年的 YOLOv8。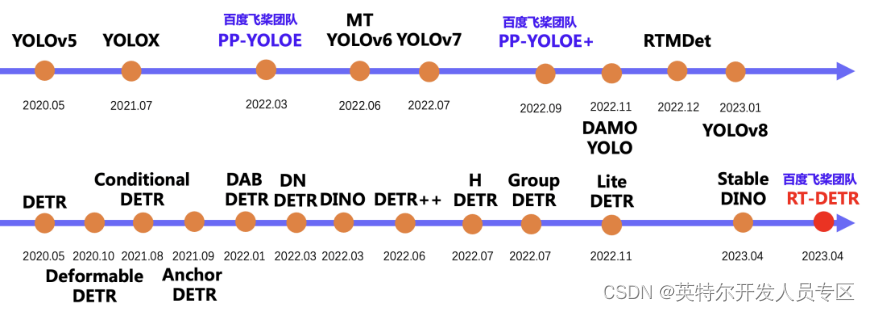
YOLO 检测器有个较大的待改进点是需要 NMS 后处理,其通常难以优化且不够鲁棒,因此检测器的速度存在延迟。DETR是一种不需要 NMS 后处理、基于 Transformer 的端到端目标检测器。百度飞桨正式推出了——RT-DETR (Real-Time DEtection TRansformer) ,一种基于 DETR 架构的实时端到端检测器,其在速度和精度上取得了 SOTA 性能。
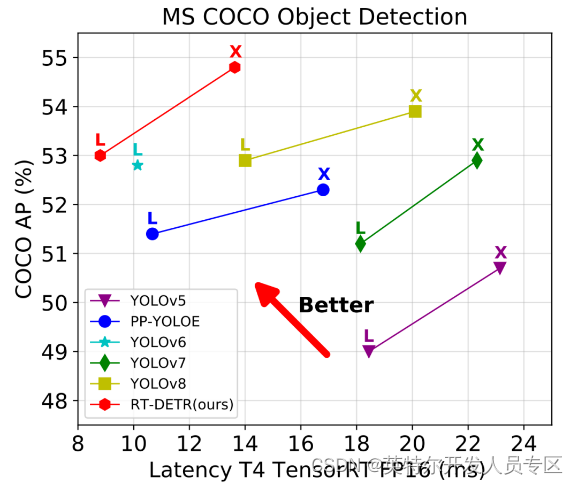
RT-DETR是在DETR模型基础上进行改进的,它通过使用一系列新的技术和算法,实现了更高效的训练和推理。具体来说,RT-DETR具有以下优势:
1、实时性能更佳:RT-DETR采用了一种新的注意力机制,能够更好地捕获物体之间的关系,并减少计算量。此外,RT-DETR还引入了一种基于时间的注意力机制,能够更好地处理视频数据。
2、精度更高:RT-DETR在保证实时性能的同时,还能够保持较高的检测精度。这主要得益于RT-DETR引入的一种新的多任务学习机制,能够更好地利用训练数据。
3、更易于训练和调参:RT-DETR采用了一种新的损失函数,能够更好地进行训练和调参。此外,RT-DETR还引入了一种新的数据增强技术,能够更好地利用训练数据。
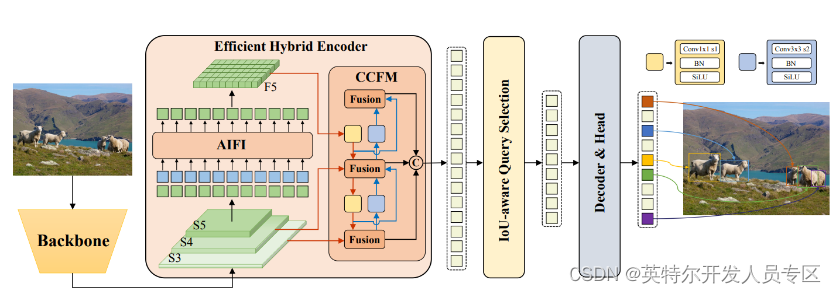
2. OpenVINO
英特尔发行版 OpenVINO™工具套件基于oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程, OpenVINO™可赋能开发者在现实世界中部署高性能应用程序和算法。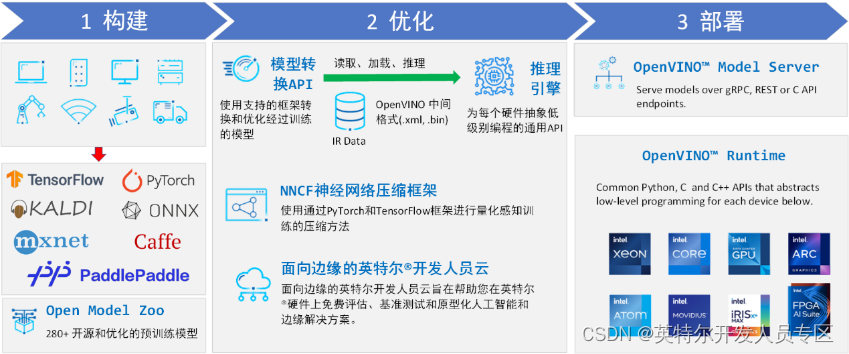
OpenVINO™ 2023.1于2023年9月18日发布,该工具包带来了挖掘生成人工智能全部潜力的新功能。生成人工智能的覆盖范围得到了扩展,通过PyTorch*等框架增强了体验,您可以在其中自动导入和转换模型。大型语言模型(LLM)在运行时性能和内存优化方面得到了提升。聊天机器人、代码生成等的模型已启用。OpenVINO更便携,性能更高,可以在任何需要的地方运行:在边缘、云中或本地。
3. 环境配置
本文中主要使用的项目环境可以通过NuGet Package包进行安装,Visual Studio 提供了NuGet Package包管理功能,可以通过其进行安装,主要使用下图两个程序包,C#平台安装程序包还是十分方便的,直接安装即可使用:
除了通过Visual Studio 安装,也可以通过 dotnet 指令进行安装,安装命令为:
dotnet add package OpenVINO.CSharp.Windows --version 2023.1.0.2
dotnet add package OpenCvSharp4.Windows --version 4.8.0.20230708 4. 模型下载与转换
在之前的文章中我们已经讲解了模型的到处方式,大家可以参考下面两篇文章实现模型导出:《基于 OpenVINO™ Python API 部署 RT-DETR 模型 | 开发者实战》(基于 OpenVINO™ Python API 部署 RT-DETR 模型 | 开发者实战)和《基于 OpenVINO™ C++ API 部署 RT-DETR 模型 | 开发者实战》(基于 OpenVINO™ C++ API 部署 RT-DETR 模型 | 开发者实战)。
5. C#代码实现
为了更系统地实现RT-DETR模型的推理流程,我们采用C#特性,封装了RTDETRPredictor模型推理类以及RTDETRProcess模型数据处理类,下面我们将对这两个类中的关键代码进行讲解。5.1 模型推理类实现
C# 代码中我们定义的RTDETRPredictor模型推理类如下所示:
public class RTDETRPredictor
{
public RTDETRPredictor(string model_path, string label_path,
string device_name = "CPU", bool postprcoess = true)
{}
public Mat predict(Mat image)
{}
private void pritf_model_info(Model model)
{}
private void fill_tensor_data_image(Tensor input_tensor, Mat input_image)
{}
private void fill_tensor_data_float(Tensor input_tensor, float[] input_data, int data_size)
{}
RTDETRProcess rtdetr_process;
bool post_flag;
Core core;
Model model;
CompiledModel compiled_model;
InferRequest infer_request;
}
1). 模型推理类初始化
首先我们需要初始化模型推理类,初始化相关信息:
public RTDETRPredictor(string model_path, string label_path, string device_name = "CPU", bool postprcoess = true)
{
INFO("Model path: " + model_path);
INFO("Device name: " + device_name);
core = new Core();
model = core.read_model(model_path);
pritf_model_info(model);
compiled_model = core.compile_model(model, device_name);
infer_request = compiled_model.create_infer_request();
rtdetr_process = new RTDETRProcess(new Size(640, 640), label_path, 0.5f);
this.post_flag = postprcoess;
}
在该方法中主要包含以下几个输入:
model_path:推理模型地址;
label_path:模型预测类别文件;
device_name:推理设备名称;
post_flag:模型是否包含后处理,当post_flag = true时,包含后处理,当post_flag = false时,不包含后处理。
2). 图片预测API
这一步中主要是对输入图片进行预测,并将模型预测结果会知道输入图片上,下面是这阶段的主要代码:
public Mat predict(Mat image)
{
Mat blob_image = rtdetr_process.preprocess(image.Clone());
if (post_flag)
{
Tensor image_tensor = infer_request.get_tensor("image");
Tensor shape_tensor = infer_request.get_tensor("im_shape");
Tensor scale_tensor = infer_request.get_tensor("scale_factor");
image_tensor.set_shape(new Shape(new List<long> { 1, 3, 640, 640 }));
shape_tensor.set_shape(new Shape(new List<long> { 1, 2 }));
scale_tensor.set_shape(new Shape(new List<long> { 1, 2 }));
fill_tensor_data_image(image_tensor, blob_image);
fill_tensor_data_float(shape_tensor, rtdetr_process.get_input_shape().ToArray(), 2);
fill_tensor_data_float(scale_tensor, rtdetr_process.get_scale_factor().ToArray(), 2);
} else {
Tensor image_tensor = infer_request.get_input_tensor();
image_tensor.set_shape(new Shape(new List<long> { 1, 3, 640, 640 }));
fill_tensor_data_image(image_tensor, blob_image);
}
infer_request.infer();
ResultData results;
if (post_flag)
{
Tensor output_tensor = infer_request.get_tensor("reshape2_95.tmp_0");
float[] result = output_tensor.get_data<float>(300 * 6);
results = rtdetr_process.postprocess(result, null, true);
} else {
Tensor score_tensor = infer_request.get_tensor(model.outputs()[1].get_any_name());
Tensor bbox_tensor = infer_request.get_tensor(model.outputs()[0].get_any_name());
float[] score = score_tensor.get_data<float>(300 * 80);
float[] bbox = bbox_tensor.get_data<float>(300 * 4);
results = rtdetr_process.postprocess(score, bbox, false);
}
return rtdetr_process.draw_box(image, results);
}
上述代码的主要逻辑如下:首先是处理输入图片,调用定义的数据处理类,将输入图片处理成指定的数据类型;然后根据模型的输入节点情况配置模型输入数据,如果使用的是动态模型输入,需要设置输入形状;接下来就是进行模型推理;最后就是对推理结果进行处理,并将结果绘制到输入图片上。
在模型数据加载时,此处重新设置了输入节点形状,因此此处支持动态模型输入;并且根据模型是否包含后处理分别封装了不同的处理方式,所以此处代码支持所有导出的预测模型。
5.2 模型数据处理类 RTDETRProces****>
1). 定义RTDETRProces***r/>
C# 代码中我们定义的RTDETRProcess模型推理类如下所示:
public class RTDETRProcess
{
public RTDETRProcess(Size target_size, string label_path = null, float threshold = 0.5f, InterpolationFlags interpf = InterpolationFlags.Linear)
{}
public Mat preprocess(Mat image)
{}
public ResultData postprocess(float[] score, float[] bbox, bool post_flag)
{}
public List<float> get_input_shape()
{}
public List<float> get_scale_factor() { }
public Mat draw_box(Mat image, ResultData results)
{}
private void read_labels(string label_path)
{}
private float sigmoid(float data)
{}
private int argmax(float[] data, int length)
{}
private Size target_size; // The model input size.
private List<string> labels; // The model classification label.
private float threshold; // The threshold parameter.
private InterpolationFlags interpf; // The image scaling method.
private List<float> im_shape;
private List<float> scale_factor;
}
2). 输入数据处理方法
输入数据处理这一块需要获取图片形状大小以及图片缩放比例系数,最后直接调用OpenCV提供的数据处理方法,对输入数据进行处理。
public Mat preprocess(Mat image)
{
im_shape = new List<float> { (float)image.Rows, (float)image.Cols };
scale_factor = new List<float> { 640.0f / (float)image.Rows, 640.0f / (float)image.Cols };
Mat input_mat = CvDnn.BlobFromImage(image, 1.0 / 255.0, target_size, 0, true, false);
return input_mat;
} 3). 预测结果数据处理方法
public ResultData postprocess(float[] score, float[] bbox, bool post_flag)
{
ResultData result = new ResultData();
if (post_flag)
{
for (int i = 0; i < 300; ++i)
{
if (score[6 * i + 1] > threshold)
{
result.clsids.Add((int)score[6 * i]);
result.labels.Add(labels[(int)score[6 * i]]);
result.bboxs.Add(new Rect((int)score[6 * i + 2], (int)score[6 * i + 3],
(int)(score[6 * i + 4] - score[6 * i + 2]),
(int)(score[6 * i + 5] - score[6 * i + 3])));
result.scores.Add(score[6 * i + 1]);
}
}
}
else
{
for (int i = 0; i < 300; ++i)
{
float[] s = new float[80];
for (int j = 0; j < 80; ++j)
{
s[j] = score[80 * i + j];
}
int clsid = argmax(s, 80);
float max_score = sigmoid(s[clsid]);
if (max_score > threshold)
{
result.clsids.Add(clsid);
result.labels.Add(labels[clsid]);
float cx = (float)(bbox[4 * i] * 640.0 / scale_factor[1]);
float cy = (float)(bbox[4 * i + 1] * 640.0 / scale_factor[0]);
float w = (float)(bbox[4 * i + 2] * 640.0 / scale_factor[1]);
float h = (float)(bbox[4 * i + 3] * 640.0 / scale_factor[0]);
result.bboxs.Add(new Rect((int)(cx - w / 2), (int)(cy - h / 2), (int)w, (int)h));
result.scores.Add(max_score);
}
}
}
return result;
}
此处对输出结果做一个解释,由于我们提供了两种模型的输出,此处提供了两种模型的输出数据处理方式,主要区别在于是否对预测框进行还原以及对预测类别进行提取,具体区别大家可以查看上述代码。
6. 预测结果展示
最后通过上述代码,我们最终可以直接实现RT-DETR模型的推理部署,RT-DETR与训练模型采用的是COCO数据集,最终我们可以获取预测后的图像结果,如图所示:
上图中展示了RT-DETR模型预测结果,同时,我们对模型图里过程中的关键信息以及推理结果进行了打印:
[INFO] Hello, World!
[INFO] Model path: E:\Model\RT-DETR\RTDETR\rtdetr_r50vd_6x_coco.xml
[INFO] Device name: CPU
[INFO] Inference Model
[INFO] Model name: Model from PaddlePaddle.
[INFO] Input:
[INFO] name: im_shape
[INFO] type: float
[INFO] shape: Shape : {1,2}
[INFO] name: image
[INFO] type: float
[INFO] shape: Shape : {1,3,640,640}
[INFO] name: scale_factor
[INFO] type: float
[INFO] shape: Shape : {1,2}
[INFO] Output:
[INFO] name: reshape2_95.tmp_0
[INFO] type: float
[INFO] shape: Shape : {300,6}
[INFO] name: tile_3.tmp_0
[INFO] type: int32_t
[INFO] shape: Shape : {1}
[INFO] Infer result:
[INFO] class_id : 0, label : person, confidence : 0.9437, left_top : [504.0, 504.0], right_bottom: [596.0, 429.0]
[INFO] class_id : 0, label : person, confidence : 0.9396, left_top : [414.0, 414.0], right_bottom: [506.0, 450.0]
[INFO] class_id : 0, label : person, confidence : 0.8740, left_top : [162.0, 162.0], right_bottom: [197.0, 265.0]
[INFO] class_id : 0, label : person, confidence : 0.8715, left_top : [267.0, 267.0], right_bottom: [298.0, 267.0]
[INFO] class_id : 0, label : person, confidence : 0.8663, left_top : [327.0, 327.0], right_bottom: [346.0, 127.0]
[INFO] class_id : 0, label : person, confidence : 0.8593, left_top : [576.0, 576.0], right_bottom: [611.0, 315.0]
[INFO] class_id : 0, label : person, confidence : 0.8578, left_top : [104.0, 104.0], right_bottom: [126.0, 148.0]
[INFO] class_id : 0, label : person, confidence : 0.8272, left_top : [363.0, 363.0], right_bottom: [381.0, 180.0]
[INFO] class_id : 0, label : person, confidence : 0.8183, left_top : [349.0, 349.0], right_bottom: [365.0, 155.0]
[INFO] class_id : 0, label : person, confidence : 0.8167, left_top : [378.0, 378.0], right_bottom: [394.0, 132.0]
[INFO] class_id : 56, label : chair, confidence : 0.6448, left_top : [98.0, 98.0], right_bottom: [118.0, 250.0]
[INFO] class_id : 56, label : chair, confidence : 0.6271, left_top : [75.0, 75.0], right_bottom: [102.0, 245.0]
[INFO] class_id : 24, label : backpack, confidence : 0.6196, left_top : [64.0, 64.0], right_bottom: [84.0, 243.0]
[INFO] class_id : 0, label : person, confidence : 0.6016, left_top : [186.0, 186.0], right_bottom: [199.0, 97.0]
[INFO] class_id : 0, label : person, confidence : 0.5715, left_top : [169.0, 169.0], right_bottom: [178.0, 95.0]
[INFO] class_id : 33, label : kite, confidence : 0.5623, left_top : [162.0, 162.0], right_bottom: [614.0, 539.0] 7. 平台推理时间测试
为了评价不同平台的模型推理性能,在C++、C#平台分别部署了RT-DETR不同Backbone结构的模型,如下表所示: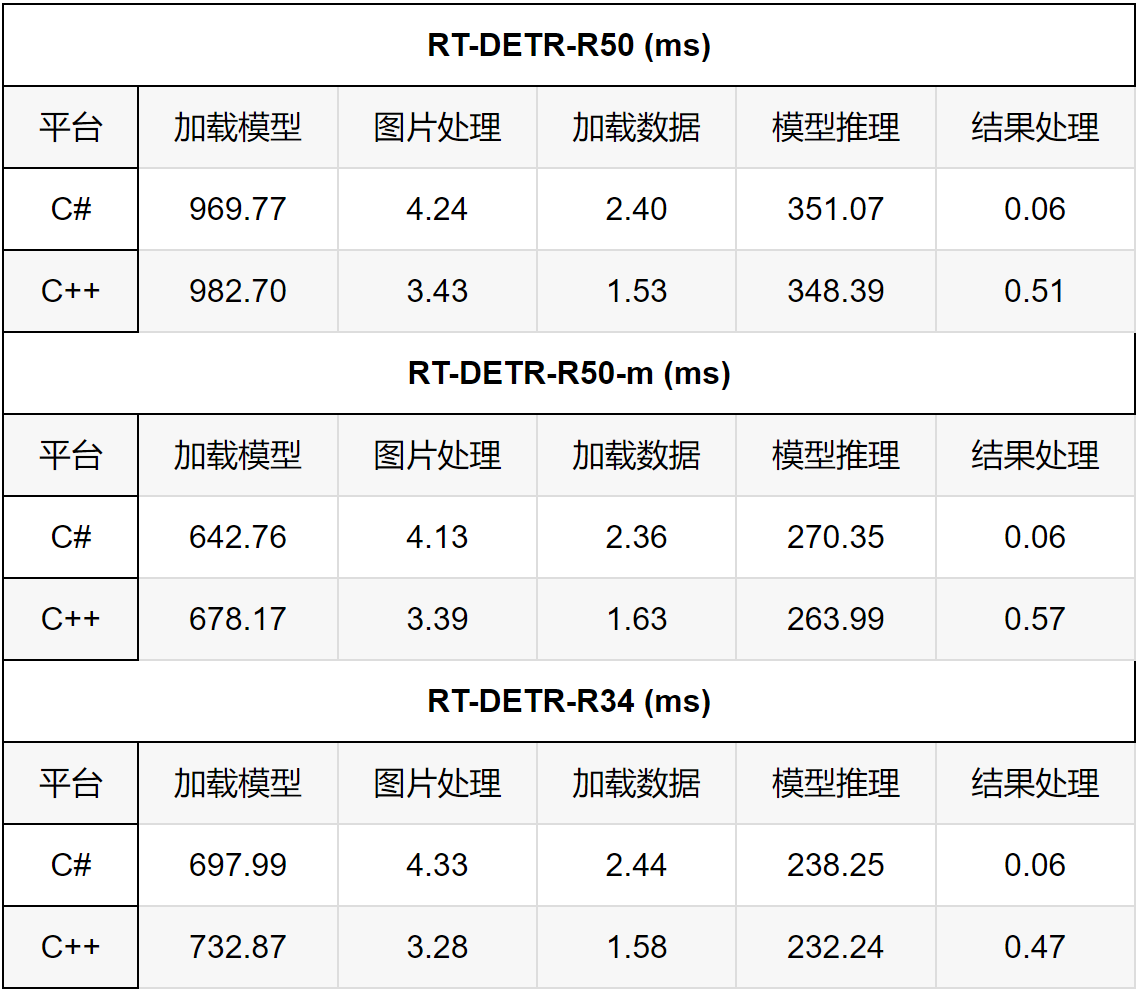
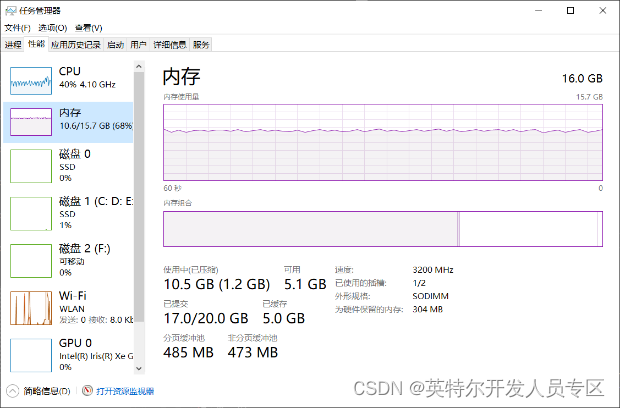
通过该表可以看出,不同Backbone结构的RT-DETR模型在C++、C#不同平台上所表现出来的模型推理性能基本一致,说明我们所推出的OpenVINO C# API 对模型推理性能并没有产生较大的影响。下图为模型推理时CPU使用以及内存占用情况,可以看出在本机设备上,模型部署时CPU占用在40%~45%左右,内存稳定在10G左右,所测试结果CPU以及内存占用未减去其他软件开销。
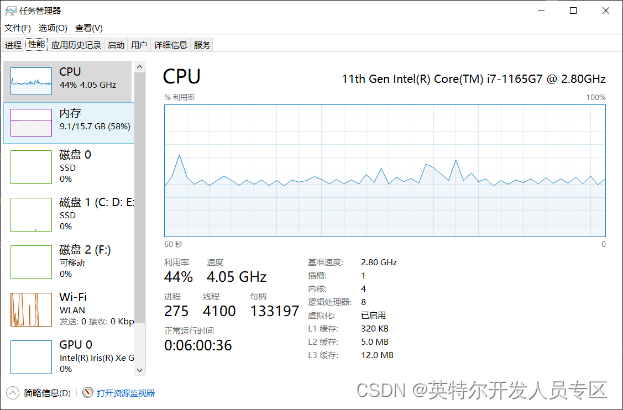
8. 总结
在本项目中,我们介绍了OpenVINO C# API 部署RT-DETR模型的案例,并结合该模型的处理方式封装完整的代码案例,实现了在 Intel 平台使用OpenVINO C# API加速深度学习模型,有助于大家以后落地RT-DETR模型在工业上的应用。最后我们对比了不同Backbone结构的RT-DETR模型在C++、C#不同平台上所表现出来的模型推理性能,在C++与C#平台上,OpenVINO所表现出的性能基本一致。但在CPU平台下,RT-DETR模型推理时间依旧达不到理想效果,后续我们会继续研究该模型的量化技术,通过量化技术提升模型的推理速度。