OpenVINO™ 面向产品集成的性能最佳实践和优化指南
 openlab_4276841a
更新于 5年前
openlab_4276841a
更新于 5年前
引言
英特尔 OpenVINO™ 工具套件分发版附带的英特尔深度学习推理引擎支持开发人员创建与部署深度学习模型,以及实现快速集成。部署流程包括 3 个主要步骤:转换、模型推理以及集成至产品。本指南的第一部分介绍了该流程的前两个步骤(请参见《面向转换和模型推理/执行的性能最佳实践和优化指南》)。转换深度学习推理模型以及使用示例验证模型推理后,便可以将模型集成至包含实际应用的产品中。本文探讨了部署流程中集成至产品阶段所需的技巧和洞察,细化到每个步骤。
第 3 步:将推理引擎插入应用
在 CPU 上执行推理会用到多个线程绑定选项。更多信息请参见 CPU 配置选项。在 NUMA 系统上执行推理的技巧
• “YES”(默认)绑定选项将线程映射至核心,最适合性能指标评测等静态/综合场景。它仅使用可用的核心(通过进程掩码确定),并以轮询的方式绑定线程。• “NUMA”绑定在真实场景中性能更佳,为操作系统调度预留了更大的空间。主要的预期用途是争用场景,例如同时在单台机器上执行多个 (CPU) 推理密集型应用。
使用第三方组件(如 Gstreamer*)构建应用级管道的 NUMA 指南如下:
• 每 NUMA 节点至少使用一个管道实例:
o 将整个管道实例锁定至最外层的特定 NUMA 节点(例如,在运行 GStreamer 命令之前,使用已经设置得当的 Kubernetes* 和/或 numactl 命令)。
o 禁用管道组件的任何单个锁定
o 将每个实例限制为推理线程数量。使用CPU_THREADS_NUM 或其他方法(例如虚拟化、Kubernetes* 等)避免过度订阅。
• 如果锁定整个管道的实例化不现实或不可取,将推理线程锁定放宽至“NUMA”。
o 相比将线程锁定至核心的默认设置,该设置限制较少,也能避免 NUMA 惩罚
应用级线程化
• 所有 OpenVINO 内部线程化(包括 CPU 推理)均使用 TBB 提供的相同线程池。由于您的应用中还有其他线程,因此有可能产生过度订阅。• 保持应用中活跃线程的总数等于机器中的核心数量。GPU 插件下的 OpenCL 驱动程序可能需要备用的核心。
• 使用 CPU 配置选项限制推理引擎的线程数量。
• 为了避免过度订阅,在所有模块/库中使用应用所使用的线程模型。
• 如果您的代码(或第三方库)使用 GNU OpenMP,必须将英特尔® OpenMP(如果您使用英特尔® OpenMP 预编译推理引擎)与应用相连,从而对其进行初始化,而不是将 GNU OpenMP 与应用相连或者在 Linux* 操作系统上使用 LD_PRELOAD。
使用推理引擎加速图像预处理/转换
在许多情况下,网络需要经过预处理的图像,因此,请勿在代码中执行不必要的步骤:• 模型优化器可将平均值和归一化(缩放)值高效烘焙至模型(例如,第一个卷积的权重)。请参见与性能相关的模型优化器功能。
• 如果您的本地媒体(例如解码帧)是每通道 8 位图像,请不要擅自转换成 FP32,因为插件会对其进行加速。使用InferenceEngine::Precision::U8 作为输入格式:

与其他 API 的基本互操作性
如需在推理引擎和媒体/图形 API(例如英特尔® Media Server Studio(英特尔® MSS))之间共享数据,一般采用基于共享系统 内存的方法。首先,您应将数据从 API 映射或复制到 CPU 地址空间。
对于英特尔 MSS,首先执行一个可行的预处理,如裁剪/调整大 小,然后使用视频处理程序 (VPP) 将其再次转换为 RGB。接下来 锁定结果,并在结果之上创建一个推理引擎 blob。生成的指针可用于 SetBlob:
//Lock Intel MSS surface
mfxFrameSurface1 *frame_in; //Input MSS surface.
mfxFrameAllocator* pAlloc = &m_mfxCore.
FrameAllocator();
pAlloc->Lock(pAlloc->pthis, frame_in->Data.MemId,
&frame_in->Data);
//Inference Engine code警告:大多数 InferenceEngine 插件不提供InferenceEngine::NHWC 布局原生支持,将导致内部转换。
InferenceEngine::SizeVector dims_src = {
1 /* batch, N*/,
(size_t) frame_in->Info.Height /* Height */,
(size_t) frame_in->Info.Width /* Width */,
3 /*Channel*******r>};
TensorDesc desc(InferenceEngine::Precision::U8, dims_src,
InferenceEngine::NHWC);
/* wrapping the surface data, as RGB is interleaved, need to
pass only ptr to the R, notice that this wouldn’t work with
planar formats as these are 3 separate planes/pointer*****r>InferenceEngine::TBlob<uint8_t>::Ptr p =
InferenceEngine::make_shared_blob<uint8_t>( desc,
(uint8_t*) frame_in->Data.R);
inferRequest.SetBlob(“input”, p);
inferRequest.Infer();
//Make sure to unlock the surface upon inference
completion, to return the ownership back to the Intel MSS
pAlloc->Unlock(pAlloc->pthis, frame_in->Data.MemId,
&frame_in->Data);您也可以使用来自英特尔 MSS 的 RGBP(平面 RGB)输出,将(锁定)结果包装成常规 NCHW,后者通常更适合大多数插件(不同于NHWC)。然后您可以搭配使用 SetBlob:
InferenceEngine::SizeVector dims_src = {
1 /* batch, N*/,
3 /*Channel*******r>(size_t) frame_in->Info.Height /* Height */,
(size_t) frame_in->Info.Width /* Width */,
};
TensorDesc desc(InferenceEngine::Precision::U8, dims_src,
InferenceEngine::NCHW);
/* wrapping the RGBP surface data*/
InferenceEngine::TBlob<uint8_t>::Ptr p =
InferenceEngine::make_shared_blob<uint8_t>( desc,
(uint8_t*) frame_in->Data.R);
inferRequest.SetBlob("input", p); 问题:
• VPP 的 RGBP 转换未经过硬件加速(在 GPU EU 上执行)
• 仅在 Linux 上可用
OpenCV* 互操作示例
不同于使用专用地址空间和/或特殊数据布局(例如经过压缩的OpenGL* 纹理)的 API,cv::Mat 等常规 OpenCV 数据对象驻留在推理引擎可以共享的传统系统内存中。如果 OpenCV 和推理引擎布局相匹配,可以将数据包装成推理引擎(输入/输出)blob。默认情况下,推理引擎接受 NCHW 中的平面和非交错输入,因此应明确指定 NHWC:
警告:大多数 InferenceEngine 插件不提供InferenceEngine::NHWC 布局原生支持,因此可能发生内部转换。
cv::Mat frame = ...; // regular CV_8UC3 image, interleaved
// creating blob that wraps the OpenCV’s Mat
// (the data it points should persists until the blob i****r>released):
InferenceEngine::SizeVector dims_src = {
1 /* batch, N*/,
(size_t)frame.rows /* Height */,
(size_t)frame.cols /* Width */,
(size_t)frame.channels() /*Channel*******r>};
TensorDesc desc(InferenceEngine::Precision::U8, dims_src,
InferenceEngine::NHWC);
InferenceEngine::TBlob<uint8_t>::Ptr p =
InferenceEngine::make_shared_blob<uint8_t>( desc,
(uint8_t*)frame.data, frame.step[0] * frame.row*****r>inferRequest.SetBlob(“input”, p);
inferRequest.Infer();
…
// similarly, you can wrap the output tensor (let’s assume it
is FP32)
// notice that the output should be also explicitly stated a****r>NHWC with setLayout
const float* output_data = output_blob->buffer().
as<PrecisionTrait<Precision::FP32>::value_type*>();
cv::Mat res (rows, cols, CV_32FC3, output_data, CV_
AUTOSTEP);应用和推理引擎无法同时使用原始 cv::Mat/blob。但是,可通过复制指针的参考数据,从而解锁原始数据,并将所有权返回至原始 API。
基于请求的 API 和“GetBlob”用语
基于推理请求的 API 提供两种类型的请求:同步和异步。将在下文介绍同步。异步将(同步)推理划分为 StartAsync 和 Wait(请参见推理引擎异步 API)。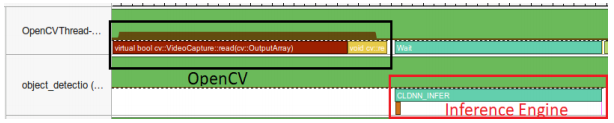
推理引擎包含“可执行”网络的参考和实际输入/输出。将网络加载至插件时,会得到一个可执行网络参考。推理请求由可执行网络创建:
Core ie;
auto network = ie.ReadNetwork("Model.xml", "Model.bin");
InferenceEngine::InputsDataMap input_info(network.
getInputsInfo());
auto executable_network = ie.LoadNetwork(network, "GPU");
auto infer_request = executable_network.
CreateInferRequest();
for (auto & item : inputInfo) {
std::string input_name = item->first;
auto input = infer_request.GetBlob(input_name);
/** Lock/Fill input tensor with data **/
unsigned char* data =
input->buffer().as<PrecisionTrait<Precision::U8>::value_
type*>();
...
}
infer_request->Infer();同时运行多个请求的性能考虑因素
如果您的应用同时执行多个推理请求:• 对于 CPU,请使用CPU“吞吐量”模式。
o 如果延迟有问题,可以尝试使用 EXCLUSIVE_ASYNC_REQUESTS 配置选项。更多信息请参见基于请求的 API 和“GetBlob”用语。
o 默认情况下,异构器件使用 EXCLUSIVE_ASYNC_REQUESTS。
o KEY_EXCLUSIVE_ASYNC_REQUESTS 选项仅影响单个应用的器件队列。
• 对于 FPGA 和 GPU,通过插件和/或驱动程序对实际工作进行序列化。
• 对于任何 VPU 类型,只有使用多个请求,才能实现较高的吞吐量。
推理引擎让用户端来决定请求优先级(例如,不对低优先级推理请求进行排序,除非另一个高优先级正在等待)。同步应用代码中的可执行网络(队列)需要额外的逻辑。
推理引擎异步 API
推理引擎异步 API 可提高应用的整体帧速率,因为在加速器忙于执行推理时,它可以继续在主机上执行操作。在本示例中,将推理应用于视频解码的结果。可同时处理两个并行推理请求。在处理一个请求的同时捕捉下一个请求的输入帧。这有助于隐藏捕捉的延迟,整体帧速率仅取决于网络中最慢的部
分(解码 IR 推理),而不是各个阶段的总和。
您可以比较常规方法和异步方法的伪代码
• 常规方法使用 OpenCV 捕捉帧,并立即对其进行处理:
while(…) {
capture frame
populate CURRENT InferRequest
Infer CURRENT InferRequest //this call is synchronou***r>display CURRENT result
}• 在异步模式中,将下一个请求部署在主(应用)线程,同时处理当前请求:
while(…) {
capture frame
populate NEXT InferRequest
start NEXT InferRequest //this call is async and return****r>immediately
wait for the CURRENT InferRequest //processed in a
dedicated thread
display CURRENT result
swap CURRENT and NEXT InferRequest***r>}性能警告:
• 并行运行的任务应尽量避免过度订阅共享计算资源
• 如果在 FPGA 上执行推理,而 CPU 基本上闲置,则有必要在 CPU 上并行执行多个任务。但是,多个推理请求可能过度订阅资源。
• 异构执行将隐式使用 CPU,请参阅异构性。
• 如果在显卡 (GPU) 上执行推理,那么在相同的 GPU 上对生成的视频进行并行编码可能进展缓慢,因为器件已经被占用。
使用工具
无论您是首次调整还是执行高级性能优化,都需要一款能提供准确洞察的工具。英特尔® VTune™ 放大器能够帮助您发掘洞察,理解分析数据英特尔® VTune™ 示例
测量与跟踪技术 API 支持在英特尔® Vtune™ 时间线上查看推理引擎调用和聚合,并将其与底层 API(例如 OpenCL)相关联,然后启用细致的逐层执行分解。
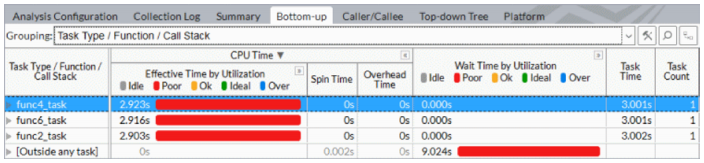
在英特尔® Vtune™ 放大器中选择分析类型时,请务必选择分析用户任务、事件和计数器选项。
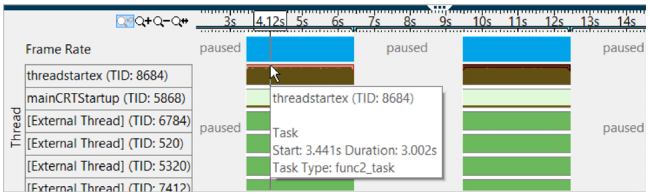
详情请参见《英特尔® Vtune™ 放大器用户指南》中的相关章节。
英特尔 vTune 放大器中的任何 GPU 分析均可用于建立与推理引擎 API 的一般关联,以及获取 OpenCL 内核的执行分解。
与常规原生应用类似,您也可以进一步探索计数器(主要用于优化自定义内核)。最后,英特尔 VTune 放大器不仅对用户级代码进行分析(请参见《英特尔® Vtune™ 放大器用户指南》中的相关章节)。
内部推理性能计数器
几乎每个示例 (-h) 均支持 -pc 命令,以输出内部执行分解。请参阅示例代码,了解背后的推理引擎 API。网络的 CPU 插件输出示例:
由于器件是一个 CPU,因此层挂钟 realTime 和 cpu 时间相同
conv1 EXECUTED layerType: Convolution realTime: 706 cpu: 706 execType: jit_avx2
conv2_1_x1 EXECUTED layerType: Convolution realTime: 137 cpu: 137 execType: jit_avx2_1x1
fc6 EXECUTED layerType: Convolution realTime: 233 cpu: 233 execType: jit_avx2_1x1
fc6_nChw8c_nchw EXECUTED layerType: Reorder realTime: 20 cpu: 20 execType: reorder
out_fc6 EXECUTED layerType: Output realTime: 3 cpu: 3 execType: unknown
relu5_9_x2 OPTIMIZED_OUT layerType: ReLU realTime: 0 cpu: 0 execType: undef包含层名称(以 IR 格式显示)、层类型和执行统计信息。OPTIMIZED_OUT 表示将特定激活融合到相邻的卷积中。不属于英特尔MKL-DNN 的特定推理引擎的 CPU (helper) 原语存在未知性。插件自动添加 CPU 执行分解中的 Helper 层(未在原始拓扑中显示)。例如,重排序将英特尔 MKL-DNN 内部(块)布局重新打包至常规平面 NCHW。