英特尔® OpenVINO™ 工具套件|转换和模型推理优化指南
 openlab_4276841a
更新于 5年前
openlab_4276841a
更新于 5年前
引言
英特尔深度学习推理引擎是英特尔® 深度学习部署工具套件(英特尔® DL 部署工具套件)和 OpenVINO™ 工具套件的重要组成部分。该引擎通过提供独立于器件的统一 API,协助部署深度学习解决方案。本文档介绍了如何在网络部署流程的每个步骤优化性能。部署流程
推理引擎部署流程主要包含 3 个步骤*:1. 转换
将经过训练的模型从特定框架(例如 Caffe 或 TensorFlow)转换成独立于框架的中间表示 (IR) 格式。
2.模型推理/执行
经过转换后,推理引擎使用 IR 来执行推理。虽然推理引擎 API 本身不受目标限制,但是其内部有插件的概念。
3.集成至产品
模型推理通过示例验证后,推理引擎代码通常被集成至实际应用或管道中。
*本文介绍了部署流程的前两个步骤;第 3 步将在单独的文档中阐述。
收集性能数据
延迟等性能数据有多种形式,用于测量模型的有效性。后续章节提供了有关如何测量性能的重要建议。适当的操作
若要测量适当的操作:• 避免包含一次性成本,如模型加载。更多示例请参见推理引擎示例。
• 对视频解码等推理引擎之外的操作进行单独跟踪。
延迟与吞吐量
为了测量吞吐量,您通常需要异步执行多个请求,用处理的图像数量除以处理时间,从而得出每秒的图像数量。然而,对于延迟导向型任务,处理单个帧的时间更为重要。
比较原生/ 框架代码的性能
为此,请确保两个版本尽可能相似:
• 正确包装推理执行(更多示例请参见推理引擎示例)。
• 请勿包含模型加载时间。
• 确保推理引擎和框架的输入完全相同。例如,Caffe* 允许对输入自动填充随机值。请注意,这可能产生与真实图像不同的性能。
• 请确保访问模式(如输入布局)最适合推理引擎。
• 应单独跟踪任何用户端预处理。
• 请务必尝试使用框架开发人员推荐的环境设置,例如TensorFlow* 的环境设置。
• 若适用,使用推理引擎的批处理功能。
• 尽可能要求相同的准确度。例如,TensorFlow 提供 FP16 支持,那么在比较时,请确保使用 FP16 对推理引擎进行测试。
获得可信的性能数据
测量性能时,对相同例程进行大量调用。由于第一次迭代的速度
总是比后续迭代慢得多,因此,您可以在最终的预测中使用执行
时间的总和:
• 如果预热运行不起作用或者执行时间仍然变化,您可以尝试运行大量迭代,然后取结果的平均值。
• 对于大幅波动的时间值,请使用几何平均值。我们来具体了解一下部署流程的前两个步骤。
第 1 步:转换:与性能相关的模型优化器功能
人们通常使用 Caffe、TensorFlow 和 MXNet 等常见训练框架, 在高端数据中心进行网络训练。模型优化器将经过训练的模型从 原始的专有格式转换为用于描述拓扑的 IR 格式。IR 附带一个包 含权重的二进制文件。推理引擎进而使用这些文件进行评分 。
工具执行独立于器件的优化。例如,线性运算(BatchNorm 和 ScaleShift)等特定原语会自动融合到卷积中。通常,不应该在生 成的 IR 中显示这些层。下图展示了 Caffe* Resnet269* 拓扑以及 模型优化器生成的模型,我们将 BatchNorm 和 ScaleShift 层融 合到卷积权重中,而不是构成单独的层。
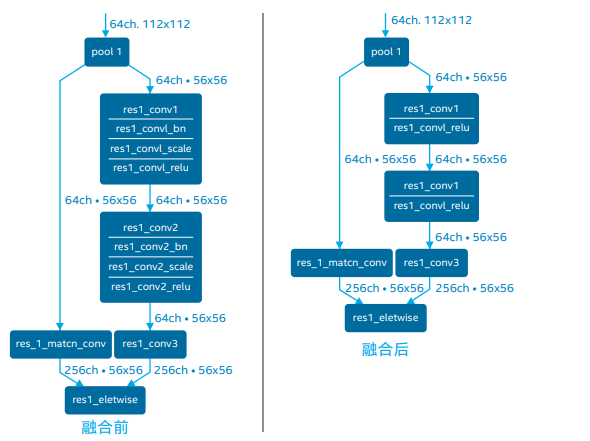
如果您仍能看到这些操作,请仔细检查模型优化器输出,同时搜索警告。
特定于器件的优化
推理引擎支持多个目标器件(CPU、GPU、英特尔® Movidius™ Myriad™ 2 VPU、英特尔® Movidius™ Myriad™ X VPU、采用英特 尔® Movidius™ 视觉处理单元 (VPU) 和 FPGA 的英特尔® 视觉加 速器设计),每个目标器件都有相应的插件。以下技巧可帮助您优 化特定器件。
推理引擎基于线程抽象级别,用于编译开源版本,以英特尔® 线程 构建模块(英特尔® TBB)或 OpenMP* 作为替代性的并行解决方 案。在 CPU 上使用推理时,使线程模型与其他应用(以及您使用的任何第三方库)保持一致,以避免过度订购。
自 R1 2019 版本以来,OpenVINO™ 工具套件使用英特尔 TBB 预编译,因此任何 OpenMP* API 或环境设置(例如 OMP_NUM_ THREADS)均无效。您可以通过 CPU 配置选项调整特定参数, 例如 CPU 推理使用的线程数。最后,OpenVINO CPU 推理是 NUMA 感知型推理。

CPU 清单
CPU 插件完全依靠面向深度神经网络的英特尔® 数学核心函
数库(英特尔® MKL-DNN)对主要原语进行加速,例如卷积或
FullyConnected。您从中得到的唯一提示是如何加速主要原语(
并且您无法改变加速方式)。如果您是高级用户,可以使用英特尔
® Vtune™ 进一步跟踪 CPU 执行。
CPU 的吞吐量模式
不同于大多数加速器,CPU 在本质上被视为一种延迟导向型器
件。OpenVINO 支持 CPU 的“吞吐量”模式,允许推理引擎在
CPU 上同时运行多个推理请求,从而提高整体吞吐量。
在内部,执行资源被分成/锁定至执行“流”。相比批处理,该模式
有助于提升网络性能,尤其是多核服务器的性能。
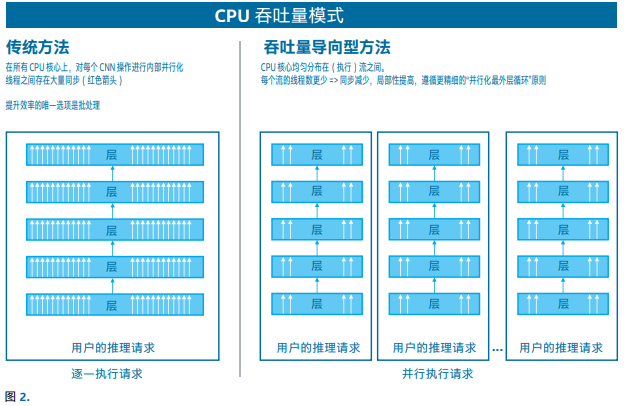
尝试使用性能指标评测应用示例,设置并行运行的流数量。一般
情况下连接设备上的诸多 CPU 核心。您也可以尝试不同的批次大
小,以寻找最佳吞吐量。
GPU 清单
推理引擎依靠深度神经网络计算库 (clDNN) 实现英特尔® GPU 上
的卷积神经网络加速。 在内部,clDNN 使用 OpenCL™ 实施内
核。以下是一些通用技巧:
• 优先使用 Fp16,而不是 FP32
• 尝试使用批处理对单个推理任务进行分组。
• 使用 GPU 将产生 OpenCL 内核编译的一次性开销。此开销发
生在将网络加载至 GPU 插件期间,不会影响推理时间。
• 如果您的应用同时在 CPU 上使用推理,或者主机负载繁重,请
确保 OpenCL 驱动程序线程不会闲置。您可以使用 CPU 配置
选项来限制 CPU 插件的推理线程数量。
• 在仅使用 GPU 场景中,一个 GPU 驱动程序可能占用一个 CPU
内核,使其完成自旋循环轮询。如果 CPU 利用率有问题,可以
考虑 KEY_CLDND_ PLUGIN_THROTTLE 配置选项。
英特尔® Movidius™ Myriad™ X 视觉处理单元和采用英特尔® Movidius™ VPU 的英特尔® 视觉加速器设计 FPGA 为了高效使用 FPGA,需要掌握以下重要技巧:
• 通过并行运行多个推理请求来隐藏通信开销。更多示例请参见 性能指标评测应用示例。
• 请确保运行多次迭代(除了基于 GUI 的演示外,所有示例都有 -ni 或 'niter’ 选项。)
• FPGA 性能高度依赖比特流。
• 每个可执行网络的推理请求数量被限制为 5 个,因此超过 5 个 输入将使“通道”并行性失效。将输入多路复用至队列,在队列 内部使用由 5 个请求组成的池。
• 根据特定技巧,通过异构执行利用 FPGA 加速。
• 有关多器件 FPGA 执行的更多信息,请参阅 FPGA 插件文档
第 2 步:模型推理/执行异构性
异构执行(由“Hetero”插件组成)支持将网络推理调度至多个器 件。在异构模式下执行网络的要点在于:
• 使用加速器计算网络中最繁重的部分,将加速器不支持的层回 退到 CPU。该方法适用于仅针对 CPU 实施特定自定义(用户) 内核的情况。
• 通过在不同器件上运行网络分支,更高效地使用所有可用的计 算器件。
异构流程
通过异构插件执行包含 3 个步骤:
1. 对层应用关联设置
• 使用回退优先级,或在每一层应用关联设置
• 在将网络加载至插件之前设置关联,因此相对于执行,这始终 是一个静态设置
2. 将网络加载至异构插件
• 在内部将网络划分为子图
• 您可以查看插件所做的决策
3. 执行推理请求
• 从用户的角度来看,这看起来与单器件实施完全相同,但是在 内部,由实际插件/器件执行子图。
异构执行的性能优势在很大程度上取决于器件间的通信粒度。使 用英特尔® Vtune™ 能够帮助您在时间线上实现执行流程的可视化 (参见英特尔® VTune™ 示例)。您可以手动定义(粗粒度)关联, 以避免在单个推理过程中来回多次发送数据。
考虑到粒度,一般将计算密集型内核放置在加速器上,将“glue” 或 helper 内核放置在 CPU 上。例如,由于数据类型和/或布局转 换过多,在 CPU 上运行自定义激活可能导致性能下降。在这种情 况下,您可以考虑为加速器实施内核(请参见优化自定义内核)。 转换通常表现为未完成的“重新排序”条目(请参见内部推理性能 计数器)。
FPGA 的异构场景
大多数 FPGA 性能问题与回退使 CPU 负载过重有关。
• 在大多数情况下,CPU 仅执行小型/轻量级的层,例如后处 理(大多数分类模型中的 SoftMax 或基于 SSD* 的拓扑中 的 DetectionOutput)。在这种情况下,使用 `KEY_CPU_ THREADS_NUM` 配置限制 CPU 线程的数量将进一步降低 CPU 利用率,不会影响整体性能。
• 如果您仍在使用旧版 OpenVINO(R1 2019 之前的版 本),或者使用 OpemMP 重新编译了推理引擎,需要将 KMP_BLOCKTIME 环境变量设置为低于默认的 200 毫秒 (我们建议 1 毫秒)。如果 CPU 子图比较小,请使用 KMP_ BLOCKTIME=0。
分析异构执行
可通过专用配置选项转储异构插件创建的子图可视化:
#include "ie_plugin_config.hpp"
#include "hetero/hetero_plugin_config.hpp"
using namespace InferenceEngine::PluginConfigParams;
using namespace InferenceEngine::HeteroConfigParams;
auto execNetwork = ie.LoadNetwork(network,
"HETERO:FPGA,CPU", { {KEY_HETERO_DUMP_GRAPH_
DOT, YES} });
• hetero_affinity.dot - per-layer affinities.仅在执行默认回退
策略时生成该文件。
• hetero_subgraphs.dot - affinities per sub-graph.在执行针
对异构流程的 Core::LoadNetwork 期间,将文件写入磁盘。
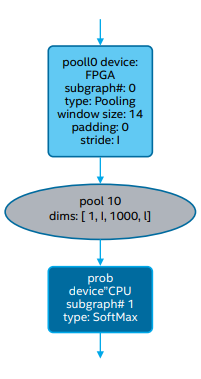
使用 Linux* OS 上提供的 GraphViz* 实用程序或 .dot 转换器(
例如转换为 .png 或 .pdf),包括 xdot*,并运行 sudo apt-get
install xdot。以下示例展示了被调整为两个最后一层(一个层在
FPGA 上执行,另一个层在 CPU 上执行)的输出:
优化自定义内核
初始性能考虑因素 推理引擎支持 CPU、GPU 和 VPU 自定义内核。通常,自定义内核 用于快速实施新拓扑丢失的层。
• 请勿覆盖标准层实施,尤其是关键路径上的层,例如卷积。此外,覆盖现有的层可能禁用融合等性能优化。
• 从 CPU 扩展着手,在调试 CPU 路径后切换到 GPU。当自定义层被放置在最后时,我们可以更轻松地将其实施为应用中的常 规后处理,无需将其包装为内核。
• 自定义内核的顺序可以被实施为“super”内核,以节省数据访问。
• 借助异构执行,您可以使用加速器执行绝大多数密集计算,将
自定义组件保存在 CPU 上,代价是牺牲不同器件间通信的粒
度/成本。
了解自定义内核对性能的贡献
在大多数情况下,在为内核实施成熟的代码之前,您可以使用简单的 stub 内核(不会执行任何操作)来端到端执行拓扑,从而预测最终性能。只有在内核输出不影响性能时(例如,输出不会驱动任何分支或循环),预测才有效。