从ChatGPT看AI模型服务化趋势
 小o
更新于 3年前
小o
更新于 3年前
作者:杨亦诚
1. 大模型是人工智能的发展趋势和未来
“从代码修复到智能问答,ChatGPT似乎已经变得无所不能“,”上线仅5天,就已经拥有超过100万用户“,从ChatGPT的实际表现,与带来的市场热度来看,大模型势必是人工智能的发展趋势和未来。
这里大模型是对结构复杂,且参数量巨大的深度学习模型的统称,参数量大也势必意味着这些模型对于底层算例也有着更高的要求。下面这张图罗列了市场上比较主流的一些AI大模型服务,以及他们各自所依赖的算力资源,可以看到承载这些大模型的基本都是大规模的GPU集群,其中ChatGPT的原型版本GPT3.5更是需要上万块V100 GPU才能满足其训练和推理任务需求。
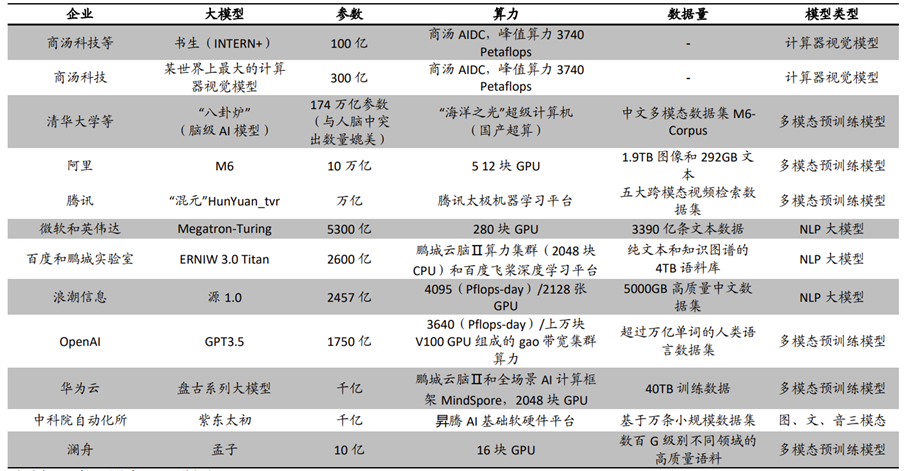
图:主流大模型AI服务的基础设施
除了对基础设施高度要求以外,大模型还意味着对于强算法的引入,这里的强算法是相对弱算法来说,但弱算法并不是说他准确性不高,而是由于项目对于功耗,延迟,数据安全性等要求,这些弱算法模型只能在限定领域解决特定的问题,例如工业场景下的产品缺陷检测就是一个典型的弱算法模型,受限于数据采集渠道,大部分算法只能针对某几类产品或者某几种缺陷实现产业化落地,不具备通用性,而强算**好相反,它通过大规模的数据采集,高复杂度的模型结构实现了在通用领域下可以替代人类的工作,此时评估一个强算法的好坏,已经不局限在它的算法精度上,更多是从商业模式维度:因为强算法的前期购入非常巨大,我们需判断其所涉及的应用领域,是否有足量的需求,是否具有投资价值。

图:不同领域的人工智能算法能力
基于这样一个趋势,AIGC类的大模型也给产业带来新的技术挑战,首先是对算力需求的高速增长,可以看到OpenAI在2018年所发布的GPT参数量为1.17亿,3年后的GPT-3参数量直接暴涨至1750亿。AI模型对算力的需求在过去短短几年内翻了大约100万倍,平均每年十几倍,这个增速甚至超过了对算法精度增长的需求。此外这类AI应用也为模型的迭代速度提出了更高的要求,大模型需要依赖于大量的训练数据,也需要更多真实场景下的反馈才可以帮助他们提升准确性,在GPT-3之后,OpenAI的所有模型都没有开源,但它提供了API调用,建立起了真实的用户调用和模型迭代之间的飞轮,他非常重视真实世界数据的调用,以及这些数据对模型的迭代。
2. MaaS 将成为人工智能公司的核心商业模式
面对以上这两点挑战,我们可以看到目前模型服务化已成成为一个必然的趋势(Mode******-Service),也将成为人工智能的核心商业模式。其实模型服务化并不是一个新的概念,它的本质是将算力和模型集中托管,并对外提供可以用模型能力的API接口,提供训练和推理服务,特别适合于有着高并发需求的推理应用场景。下面这张图展示的就是一个比较简化的模型服务架构,最左边是一个模型仓库,用来存储模型,并进行模型的版本管理,中间是模型服务器,用来托管算力资源,并开展推理任务,最右边则是用户侧的客户端,用来发起任务请求,通过通过API的调用,为模型服务器送入输出数据,并获从取推理结果数据。
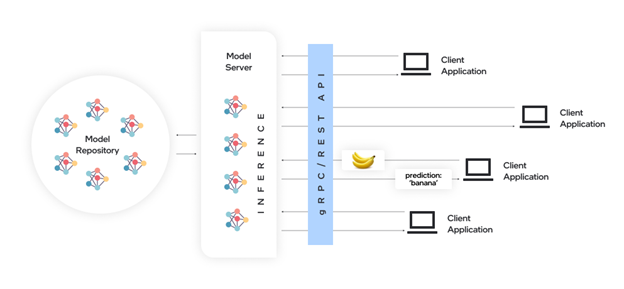
图:模型服务化架构
在这个架构中有一个非常重要的角色叫做模型服务器,那我们为什么要使用模型服务器呢,首先对于普通用户来说,他们无需在购买高昂的AI硬件设备,通过集成在手机或者终端上的客户端程序,就可以轻松体验大模型的服务,降低使用门槛,提升用户体验;对AI应用的开发人员来说,使用通用API获取模型的推理服务,可以更易于在不同的编程语言,不同的系统架构下进行产品集成;最后针对AI模型的开发人员和算法研究人员,这样的模型服务器的引入,也更方便他们对现有的算力进行有效管理,可根据实际业务量合理分配资源, 实现利用率最大化,同时根据API调用次数的收费模式,也更具有商业可落地性。
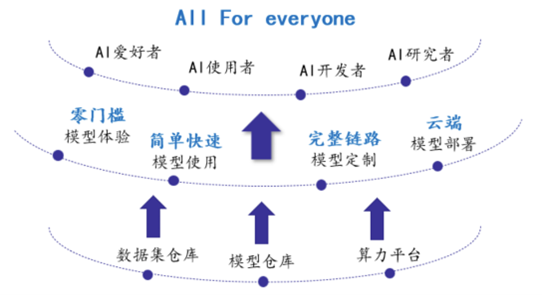
图:模型服务器的价值
3. OpenVINO™ 模型服务器降低AI服务部署门槛

图:使用OpenVINO™部署Stable Diffusion模型
说到这里就不得不提一下OpenVINO™的模型服务器,如果了解过OpenVINO™的小伙伴应该都知道,OpenVINO™可以通过引入runtime动态库或者静态库的方式来部署加速深度学习模型,除此之外OpenVINO™也提供了模型服务器这样的部署模式,OpenVINO™ 模型服务器(以下简称OVMS)是快速部署深度学习模型的高性能工具,灵活且高效,降低AI模型部署门槛。
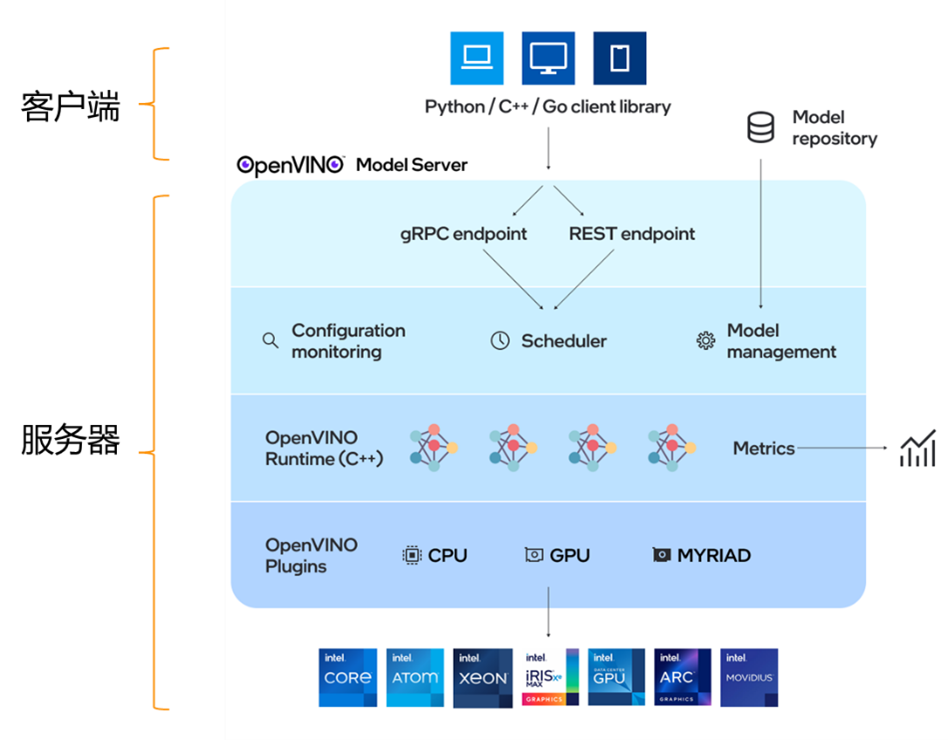
图:OpenVINO™ 模型服务器架构
OVMS的系统架构可以分为两个部分:客户端和服务器,客户端发起请求,服务端响应请求,他主要有以下几个特点:
·简单:标准化网络API接口(gRPC和RESTful),易于集成。
·快速: 通过docker方式部署,只需要若干命令行,便可以快速搭建一套完整的模型服务器
·高效: OVMS的底层继承了OpenVINO的推理引擎,因此它可以兼容各类Intel平台,榨干设备算力,降低延时,提高吞吐率。
·部署: OVMS基于云原生架构设计,可以通过K8s进行部署,具有很强的动态扩展能力,同时通过Scheduler组件可以是对前端推理请求的负载均衡,平衡后端算力资源。
·运维: OVMS可以通过配置文件动态进行模型的版本管理,支持模型热更新,这意味着我们可以在不暂定当前服务的情况下,实时更新模型。
此外OVMS还支持以下一些能力:
·兼容TensorFlow Serving API和KServe API
·支持C++版本gRPC, RESTful API
·支持模型增减,配置热更新
·支持动态尺寸
·支持多模型部署
·支持OpenVINO IR/ONNX/Paddle Paddle模型
·支持本地及远程模型文件存储(GCS/AWS S3/Azure Storage)
·支持Bare Metal/VM/Docker/K8s部署
·支持多种异构计算硬件CPU/GPU/VPU
·提供性能测试客户端,快速验证AI服务性能
4. OpenVINO™ 模型服务器部署示例
接下来我们通过一个简单的示例,来看下如何快速搭建一个文本检测任务的模型服务器。
·第一步,安装Docker Engine
我们可以参考docker官方的文档(https://docs.docker.com/engine/install/)来安装容器服务,并且可以使用以下命令来验证docker engine是否安装成功。
!docker run hello-world
如果出现以下打印输出就说明docker安装成功了。
图:验证docker engine是否安装成功
·第二步,准备模型仓库
OVMS对于模型文件在服务器端的存储路径有一定格式上要求:
1) 每一个模型都必须被存储在一个独立的根目录文件夹下,例如:model1,model2
2) 每一个模型目录必须包含一个子目录,子目录名称为该模型的版本号,例如1或2,每个根目录下可以有多个子目录,用来存储不同版本的模型
3) 一个版本目录下只能包含单个模型所有的模型文件
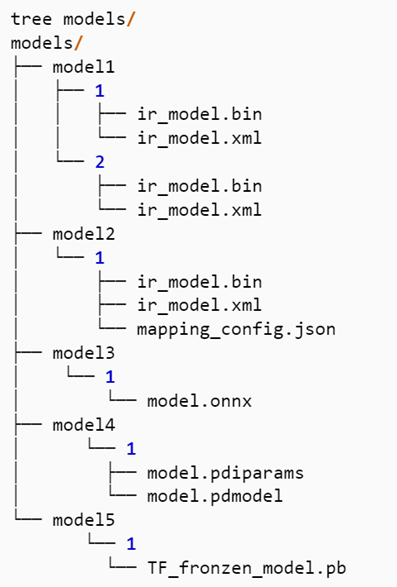
图:OVMS模型仓库文件夹结构示例
· 第三步,拉取并启动OVMS镜像
通过以下命令可以拉取OVMS镜像,并快速启动一个基于本地端口的OVMS服务器:
!docker run -d --rm --name="ovms" -v $(pwd)/models:/models -p 9000:9000 openvino/model_server:latest --model_path /models/detection/ --model_name detection --port 9000 这里有一些重要的参数,需要在服务启动是进行配置:

如果发现由于9000端口已经被占用,导致服务无法启动,在linux系统上我们可通过 netstat -tln 指令查看端口占用情况,将物理机端口更为空闲端口,例如:-p 9020:9000。
· 第四步,编写客户端应用
客户端应用主要用于发起推理请求,并接受模型服务器的结果数据,用于后续的处理或者展示。从通信接口维度,目前OVMS支持gRPC与REST api的数据传输接口,鉴于通常情况下gRPC的性能要优于REST,如果应用对时效性要求比较高,推荐使用gRPC编写客户端应用。其次从编程接口维度,OVMS的客户端是兼容TensorFlow Serving 和KServe API两种接口规范,并同时支持Python和C++编程语言,这也意味着如果用户原本的应用是部署在TensorFlow Serving或者Triton上,他们可以非常容易地将这些应用迁移到OVMS上。这里的以ovmsclient工具包作为示例,该工具包已经集成了TensorFlow Serving api, 这里展示了几个比较常用的接口:
1.安装并加载ovmsclient工具包
!pip install ovmsclientfrom ovmsclient import make_grpc_client
2. 创建客户端对象,并绑定服务端口
address = "localhost:9000"client = make_grpc_client(address)
打印后,我们可以观察到以下输出,证明模型目前是可以接受推理任务的
{1: {'state': 'AVAILABLE', 'error_code': 0, 'error_message': 'OK'}} 3. 获取模型服务状态,与模型元数据
model_status = client.get_model_statu***odel_name="detection")model_metadata = client.get_model_metadata(model_name="detection")
打印后,我们可以观察到以下输出,其中有关于模型输入输出的名称,以及他们的维度和形状信息等。
{'model_version': 1, 'inputs': {'image': {'shape': [1, 3, 704, 704], 'dtype': 'DT_FLOAT'}}, 'outputs': {'1204_1205.0': {'shape': [484], 'dtype': 'DT_FLOAT'}, '1141_1142.0': {'shape': [1000], 'dtype': 'DT_FLOAT'}, '1469_1470.0': {'shape': [100], 'dtype': 'DT_FLOAT'}, 'labels': {'shape': [100], 'dtype': 'DT_INT32'}, '1267_1268.0': {'shape': [121], 'dtype': 'DT_FLOAT'}, 'boxes': {'shape': [100, 5], 'dtype': 'DT_FLOAT'}, '1078_1079.0': {'shape': [1000], 'dtype': 'DT_FLOAT'}, '1330_1331.0': {'shape': [36], 'dtype': 'DT_FLOAT'}}}4. OVMS是支持将原始的结果数据以二进制格式或者Numpy Array进行输入的,这里我们将将原始图片转化为Numpy Array格式,推送至模型服务器,并发起推理请求
boxes = client.predict(inputs=input****odel_name="detection")['boxes']这里结果数据boxes所对应的key值['boxes'],可以通过之前查询到的模型元数据中获取。当客户端接收到模型服务返回的boxes结果数据后,我们可以在客户端实现对这部分数据的后处理工作,以获取最终可以被应用的结果数据。
该示例的具体流程和演示效果可以参考OpenVINO notebook:
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/117-model-server
5. 总结
从当下ChatGPT的火爆,我们看到大模型势必是人工智能的发展趋势和未来,同时模型服务化将成为人工智能公司的核心商业模式,以便更好地对大模型基础设施资源进行管理,并提升用户的使用体验,而OpenVINO™ 模型服务器则可以帮助模型开发人员实现简单、快速、高效地部署和运维AI推理服务,加快大模型商业化落地的进程。
转载自微信公众号“OpenVINO中文社区”