累计吞吐量——用集成显卡+独立显卡助力全速AI推理
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
作者:武卓,沈王磊
OpenVINO™工具套件2022.1版本中的自动设备插件(AUTO)支持自动选择最适合AI推理的目标设备,并支持以适当的配置、获得推理性能吞吐量优先或者延迟优先、从而满足目标应用的需求,并且能够降低首次推理的延迟。关于此功能的详细介绍可以在我们的博客“(使用 OpenVINO™ AUTO设备插件提高 AI 应用的性能&可移植性)”中找到。
然而,假如你同时拥有集成显卡和独立显卡、CPU、VPU等多个设备可以运行AI推理,例如具备英特尔集成显卡和独立显卡的算力魔方,如何通过多个设备获得全速AI推理呢?这个问题的答案就是使用OpenVINO™ 2022.2新版本中的新功能“累计吞吐量(CUMULATIVE_THROUGHPUT)”。
如果说,在OpenVINO™ 2022.1版本中,自动设备插件的两个性能优先配置,吞吐量优先和延迟优先,可以根据需要在推理时选择所有可选设备中最适合的一个目标设备来运行AI推理(如图1所示)。那么,累计吞吐量(CUMULATIVE_THROUGHPUT)选项就可以在多个设备上同时运行AI推理以获得更高的吞吐量。使用CUMULATIVE_THROUGHPUT,自动设备插件将网络模型加载到候选设备列表中的所有可用设备,然后根据默认或指定的优先级在这些设备上运行推理,如图2所示。
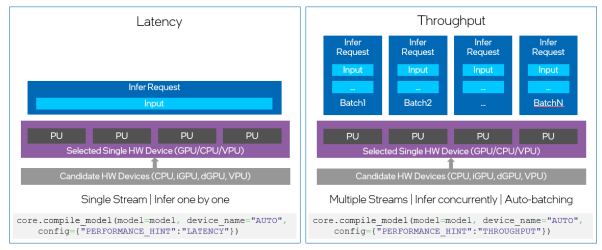
Fig.1. “吞吐量优先”及“延迟优先”模式下的硬件选择及推理请求
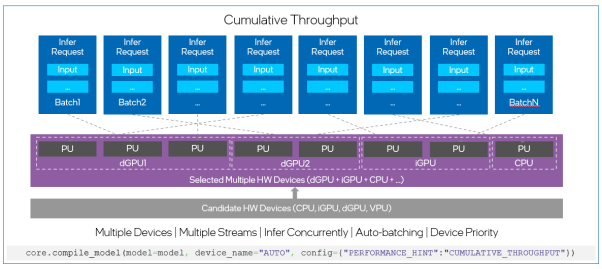
Fig.2. “累计吞吐量”模式下的硬件选择及推理请求
如何配置CUMULATIVE_THROUGHPUT?
下面所示的代码示例分别展示了如何使用C++语言以及Python语言配置CUMULATIVE_THROUGHPUT。
C++ example:
// Compile a model on AUTO with Performance Hint enabled:
// To use the “CUMULATIVE_THROUGHPUT” option:
ov::CompiledModel compiled_mode3 = core.compile_model(model, "AUTO", ov::hint::performance_mode(ov::hint::PerformanceMode::CUMULATIVE_THROUGHPUT)); Python Example:
# Compile a model on AUTO with Performance Hints enabled:
# To use the “CUMULATIVE_THROUGHPUT” mode:
compiled_model = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"CUMULATIVE_THROUGHPUT"}) 你还可以使用以下命令,特别指定用来运行推理的设备:
compiled_model = core.compile_model(model=model, device_name="AUTO:GPU,CPU", config={"PERFORMANCE_HINT":"CUMULATIVE_THROUGHPUT"}) CUMULATIVE_THROUGHPUT高级控件及配置
有时使用自动设备插件时,您对推断的设备选择有进一步的要求。例如,您希望为应用程序的业务逻辑保留CPU,那么可以使用以下代码示例在CUMULATIVE_THROUGHPUT中删除CPU作为推理的候选设备:
compiled_mode_1 = core.compile_model(model, "AUTO:-CPU", ov::hint::performance_mode(ov::hint::PerformanceMode:: CUMULATIVE_THROUGHPUT)); 同样地,如果您的应用程序需要在“吞吐量优先”模式中禁用CPU进行推理,您可以使用以下命令来实现:
compiled_mode_2 = core.compile_model(model, "AUTO:-CPU", ov::hint::performance_mode(ov::hint::PerformanceMode:: THROUGHPUT)); CUMULATIVE_THROUGHPUT如何选择设备?
当你在OpenVINO 2022.2版本中使用CUMULATIVE_THROUGHPUT时,内部调度器和根据推断请求数设置的ie_core blob队列可以将任何推理请求加载到所选多个设备中的任意设备。
自动调度器首先将推断请求加载到具有更高优先级的设备。例如,如果你使用以下命令指定了用于推断的设备的优先级:
compiled_model = core.compile_model(model=model, device_name="AUTO:GPU.1,GPU.0,CPU", config={"PERFORMANCE_HINT":"CUMULATIVE_THROUGHPUT"}) 这就意味着GPU.1是运行推理的最高优先级设备。因此,当运行推理时,自动设备插件的调度器将首先将推理请求加载到GPU.1。如果GPU.1中的所有处理单元都已完全加载,那么自动设备插件的调度器将把推理请求加载到GPU.0。请注意,在OpenVINO 2022.2版本中,CPU到GPU的推理请求之间存在额外的内存拷贝。在未来的版本中,将对此进行改进,删除此内存副本。
图3显示了自动设备插件调度器如何将推理请求组成的推理批(batch)加载到不同的设备。
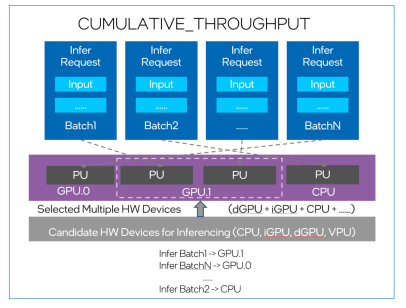
Fig.3 AUTO充当应用程序和设备之间的代理
总结
总之,“CUMULATIVE_THROUGHPUT”是OpenVINOTM 2022.2版本中引入的新的性能优先特性。使用“CUMULATIVE_THROUGHPUT”,kaifaz 可以享受由多个设备同时推理提供的吞吐量性能的显著提升。
想要了解各位相信的信息,请查看AUTO documentation.