YOLOv5模型部署TensorRT之 FP32、FP16、INT8推理
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
原创 gloomyfish 文章来源:OpenCV学堂
引言
YOLOv5最新版本的6.x已经支持直接导出engine文件并部署到TensorRT上了。
FP32推理TensorRT演示
python export.py --weights yolov5s.pt --include onnx engine --device 0其中onnx表示导出onnx格式的模型文件,支持部署到:
- OpenCV DNN- OpenVINO- TensorRT- ONNXRUNTIME
使用tensorRT推理
python detect.py --weights yolov5s.engine --view-img --source data/images/zidane.jpg
FP16推理TensorRT演示
在上面的导出命令行中修改为如下
python export.py --weights yolov5s.onnx --include engine --half --device 0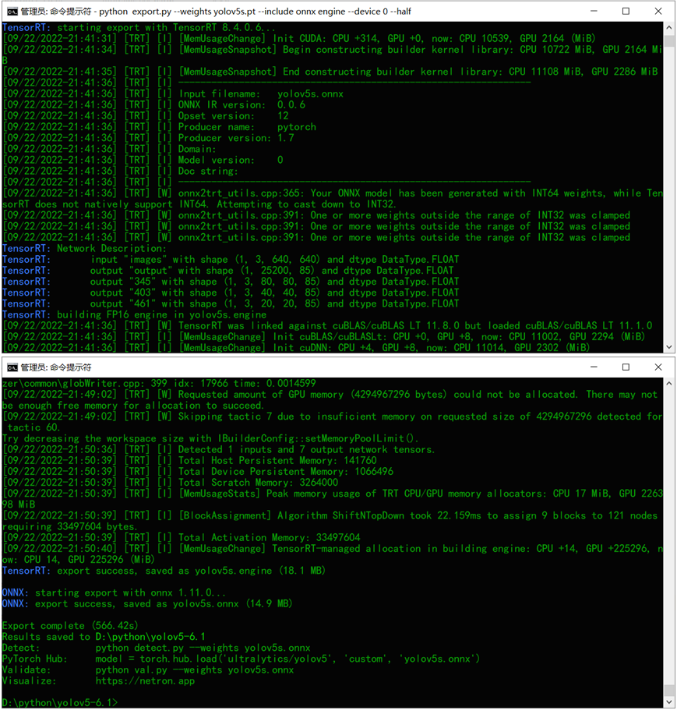
推理执行的命令跟FP32的相同,直接运行,显示结果如下:

INT8量化与推理TensorRT演示
#使用calibrator验证时候每次张数,跟显存有关系,最少1张get_batch_size#获取每个批次的图像数据,组装成CUDA内存数据get_batch#如果以前运行过保存过,可以直接读取量化,低碳给国家省电read_calibration_cache#保存calibration文件,量化时候会用到write_calibration_cache
TensorRT-8.4.0.6\samples\python\int8_caffe_mnist# build trt enginebuilder.max_batch_size = 1config.max_workspace_size = 1 << 30config.set_flag(trt.BuilderFlag.INT8)config.int8_calibrator = calibratorprint('Int8 mode enabled')plan = builder.build_serialized_network(network, config)
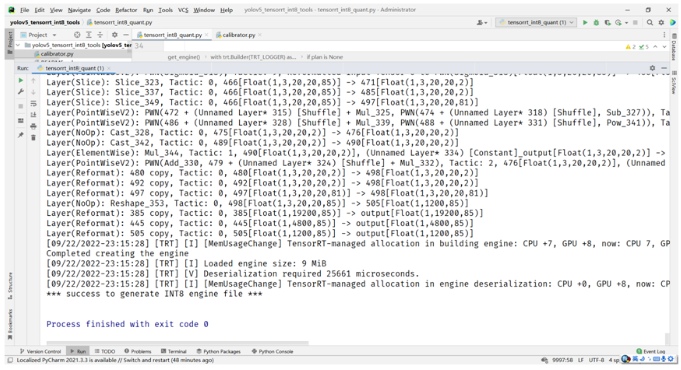
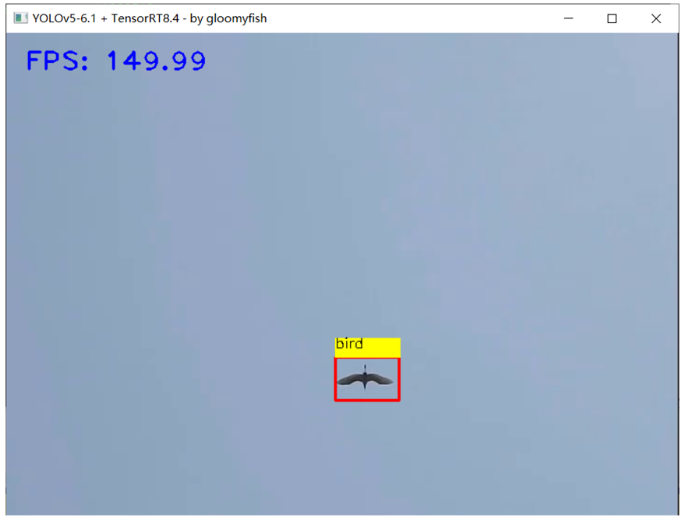
量化效果非常好,精度只有一点下降,但是速度比FP32的提升了1.5倍左右(3050Ti)。
已知问题与解决
量化过程遇到这个错误
[09/22/2022-23:01:13] [TRT] [I] Calibrated batch 127 in 0.30856 seconds.[09/22/2022-23:01:16] [TRT] [E] 2: [quantization.cpp::nvinfer1::DynamicRange::DynamicRange::70] Error Code 2: Internal Error (Assertion min_ <= max_ failed. )[09/22/2022-23:01:16] [TRT] [E] 2: [builder.cpp::nvinfer1::builder::Builder::buildSerializedNetwork::619] Error Code 2: Internal Error (Assertion engine != nullptr failed. )Failed to create the engineTraceback (most recent call last):
解决方法,把Calibrator中getBtach方法里面的代码:
img = np.ascontiguousarray(img, dtype=np.float32)to
img = np.ascontiguousarray(img, dtype=np.float16)这样就可以避免量化失败。
具体解释可以查看这个帖子!
https://github.com/NVIDIA/TensorRT/issues/1634
0个评论