基于OpenVINO 2022.2和蝰蛇峡谷优化并部署YOLOv5模型
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
文章作者:
英特尔物联网行业创新大使 杨雪锋 博士
中国矿业大学机电工程学院副教授;
发表学术论文30余篇,获国家专利授权20多件(其中发明专利8件)
1.1OpenVINOTM 2022.2简介
openvino-dev(OpenVINO开发工具) 2022.2版于2022年9月21日正式发布,根据官宣《支持英特尔独立显卡的OpenVINO™ 2022.2新版本来啦》,OpenVINO™ 2022.2将是第一个支持英特尔独立显卡的版本。
图片来源:https://pypi.org/project/openvino-dev/
从开发者的角度来看,对于提升开发效率或运行效率有用的特性有:
· 支持英特尔独立显卡。开发者只需要编写一次OpenVINO程序,即可以将AI模型通过指定推理设备的方式,部署到英特尔的CPU、集成显卡、独立显卡、VPU或FPGA上,大大降低了学习投入,提高了开发效率,如下图所示。
· 为AUTO设备插件新增“Cumulative throughput”性能倾向选择。这意味着开发者无需手动新增推理计算请求,便可在多个AI推理计算设备(例如:多个GPU)上进行并发推理。
· AUTO和MULTI设备插件支持用“-CPU” 将CPU移除推理设备列表。举个例子:“AUTO:-CPU”意味着不使用CPU作为AI推理计算设备,从而将CPU从AI推理计算中释放出来,聚焦于任务调度和其它非AI推理计算(例如:从摄像头采集图像、运行传统图像处理算法...)。

1.2YOLOv5简介
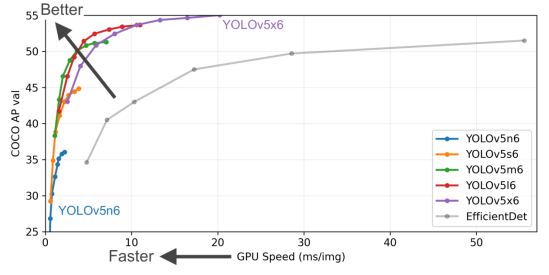
Ultralytics公司贡献的YOLOv5 PyTorch (https://github.com/ultralytics/yolov5)实现版,由于其工程化和文档做的特别好,深受广大AI开发者的喜爱,GitHub上的星标超过了31.1K,而且被PyTorch官方收录于PyTorch的官方模型仓。由于YOLOv5精度高速度快,且工程化做的非常好,使得产业实践中,即便YOLOv6和YOLOv7已发布,但大多数人仍然选用YOLOv5做目标检测——参考OpenCV学堂的测评文章《YOLOv5,YOLOv6,YOLOv7在TensorRT推理速度比较》。
图片来源:https://github.com/ultralytics/yolov5/blob/master/.github/README_cn.md
1.3蝰蛇峡谷简介
蝰蛇峡谷(Serpent Canyon) 是一款性能强劲,并且体积小巧的高性能迷你主机,搭载全新一代混合架构的第 12 代智能英特尔® 酷睿™ 处理器,并且内置了英特尔锐炫™ A770M 显卡。强悍内芯搭配全新独显的蝰蛇峡谷体积仅约2.5升,节省桌面空间的同时提供了丰富的接口,作为生产力工具,从内到外都是高标准要求,能够为用户带来优质的工作体验。英特尔锐炫™ A770M 显卡基于Xe-HPG 微架构,Xe HPG GPU 中的每个 Xe 内核都配置了一组 256 位矢量引擎,旨在加速传统图形和计算工作负载,以及新的 1024 位矩阵引擎或 Xe 矩阵扩展,旨在加速人工智能工作负载。

蝰蛇峡谷上有两块GPU:一块是英特尔®锐炬®集成显卡,一块是英特尔®锐炫® A770M独立显卡。本文在后面章节将使用OpenVINO 2022.2的“Cumulative throughput”性能倾向选择新特性,同时使用这两块显卡进行AI推理计算。
1.4准备YOLOv5的OpenVINO推理程序开发环境
要完成YOLOv5的OpenVINO 2022.2推理程序开发,需要安装:· YOLOv5
· OpenVINO 2022.2
由于YOLOv5的工程化做的实在太好,在Windows中安装上述环境,只需要两条命令:
git clone https://github.com/ultralytics/yolov5 # clonecd yolov5
cd yolov5
pip install -r requirements.txt && pip install openvino-dev[onnx] # install
1.5导出yolov5s.onnx模型
在yolov5文件夹下,使用命令:python export.py --weights yolov5s.pt --include onnx,完成yolov5s.onnx模型导出,如下图所示。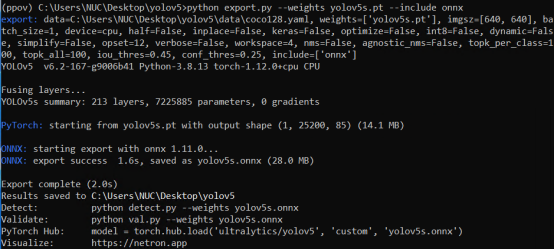
1.6用Netron工具查看yolov5s.onnx模型的输入和输出
使用Netron(https://netron.app/),查看yolov5s.onnx模型的输入和输出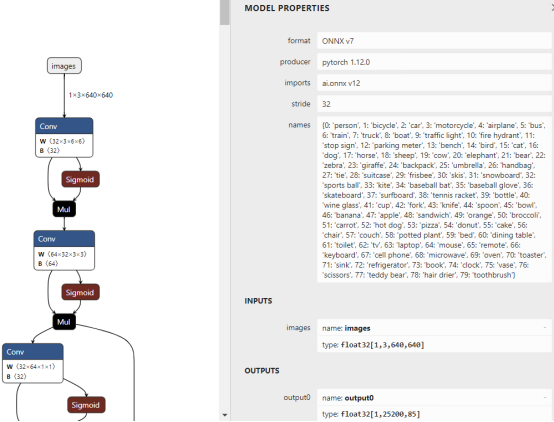
从图中可以看出:YOLOv5 模型的输出叫:“output0”,每张图片的推理结果有25200行,每行85个数值,前面5个数值分别是:
cx, cy, w, h, score, 后面80个参数是MSCOCO的分类得分。
1.7使用模型优化器将yolov5s.onnx转换为FP16精度的IR模型
模型优化器(Model Optimizer)是OpenVINO自带的跨平台的命令行模型优化工具,当执行完“pip install openvino-dev”安装命令后,模型优化器已经随同OpenVINO一并安装好了。参考链接:https://pypi.org/project/openvino-dev/
模型优化器主要通过进行静态模型分析,执行与硬件无关的网络优化(例如:网络层与算子融合、删除死节点等),更改模型精度,添加归一化参数(mean & scale)等等,最终输出IR(Intermediate Representation)模型,从而进一步提升AI推理计算速度。参考链接:https://docs.openvino.ai/latest/openvino_doc***odel_optimization_guide.html
使用模型优化器优化并转换模型时,模型精度通常选FP16,因为它是在GPU上性能最好,且所有推理设备都支持的模型精度,参考链接:https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html

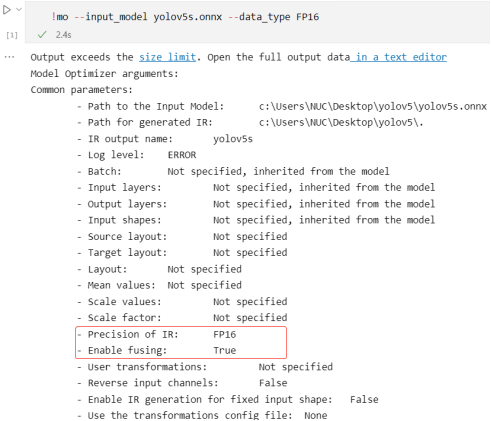
综上,使用命令:mo --input_model yolov5s.onnx --data_type FP16,进一步优化yolov5s模型,并将模型格式转换为IR格式,模型精度转换为FP16,运行结果如下图所示。

1.8使用benchmark_app获得yolov5s.xml模型的性能数据
benchmark_app也是OpenVINO自带的跨平台的命令行工具,通过该工具,可以快速获得模型的性能数据。如前所述,直接使用“AUTO:-CPU”设备插件,并指定“Cumulative throughput”性能倾向选择,即可同时使用蝰蛇峡谷上的两块显卡做AI推理计算。
使用命令获得yolov5s.xml模型在两块显卡上同时做AI推理计算的性能数据:
从任务管理器中可以看出,通过“AUTO:-CPU”设备插件释放了CPU;通过“Cumulative throughput”性能倾向选择,使得两块显卡都在做AI推理计算。
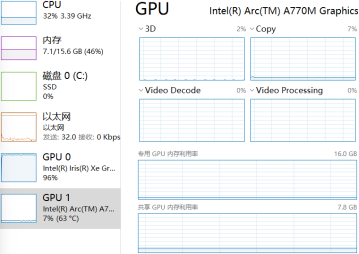
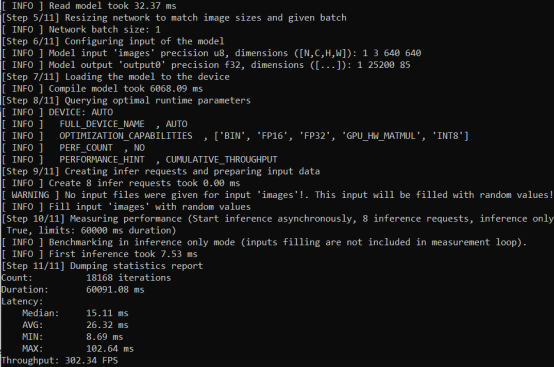
benchmark_app运行结果,如下图所示。
1.9使用OpenVINO Runtime API开发YOLOv5的同步推理程序
基于OpenVINO Runtime API实现同步推理计算程序的典型流程,主要有三步:1.创建Core对象;
2.载入并编译模型;
3.执行推理计算获得推理结果;

完整范例程序如下所示,总共不到50行。本范例程序使用了yolort(https://github.com/zhiqwang/yolov5-rt-stack)中的non_max_suppression实现后处理,运行范例程序前,请先安装yolort: pip install -U yolort
请将范例代码下载后放入yolov5文件夹下再运行:
https://gitee.com/ppov-nuc/yolov5_infer/blob/main/yolov5_ov2022_sync_dGPU.py
import cv2
import time
import yaml
import torch
from openvino.runtime import Core
# https://github.com/zhiqwang/yolov5-rt-stack
from yolort.v5 import non_max_suppression, scale_coords
# Load COCO Label from yolov5/data/coco.yaml
with open('./data/coco.yaml','r', encoding='utf-8') as f:
result = yaml.load(f.read(),Loader=yaml.FullLoader)
class_list = result['names']
# Step1: Create OpenVINO Runtime Core
core = Core()
# Step2: Compile the Model, using dGPU
net = core.compile_model("yolov5s.xml", "GPU.1")
output_node = net.outputs[0]
# color palette
colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
#import the letterbox for preprocess the frame
from utils.augmentations import letterbox
start = time.time() # total excution time = preprocess + infer + postprocess
frame = cv2.imread("./data/images/zidane.jpg")
# preprocess frame by letterbox
letterbox_img, _, _= letterbox(frame, auto=False)
# Normalization + Swap RB + Layout from HWC to NCHW
blob = cv2.dnn.blobFromImage(letterbox_img, 1/255.0, swapRB=True)
# Step 3: Do the inference
outs = torch.tensor(net([blob])[output_node])
# Postprocess of YOLOv5:NMS
dets = non_max_suppression(outs)[0].numpy()
bboxes, scores, class_ids= dets[:,:4], dets[:,4], dets[:,5]
# rescale the coordinates
bboxes = scale_coords(letterbox_img.shape[:-1], bboxes, frame.shape[:-1]).astype(int)
end = time.time()
#Show bbox
for bbox, score, class_id in zip(bboxes, scores, class_ids):
color = colors[int(class_id) % len(colors)]
cv2.rectangle(frame, (bbox[0],bbox[1]), (bbox[2], bbox[3]), color, 2)
cv2.rectangle(frame, (bbox[0], bbox[1] - 20), (bbox[2], bbox[1]), color, -1)
cv2.putText(frame, class_list[class_id], (bbox[0], bbox[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, .5, (255, 255, 255))
# show FPS
fps = (1 / (end - start))
fps_label = "FPS: %.2f" % fps
cv2.putText(frame, fps_label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
print(fps_label+ "; Detections: " + str(len(class_ids)))
cv2.imshow("output", frame)
cv2.waitKey()
cv2.destroyAllWindows() 1.10总结
第一:OpenVINO主要应用于AI模型的优化和部署。第二:OpenVINO易学易用:
√ 掌握两个命令行工具:mo和benchmark_app就可以优化并测试模型的性能;
√ 掌握三个Python API函数,就可以完成AI模型的同步推理计算程序;
√ 整个范例程序不超过80行,清晰易读。即便零基础,也能快速掌握并应用。
第三:通过“AUTO:-CPU”设备插件和“Cumulative throughput”性能倾向选择,可以非常容易的同时使用多个GPU进行推理计算,并释放出宝贵的CPU资源。
第四:蝰蛇峡谷是首款英特尔独显NUC迷你电脑,AI推理性能强大,请参见benchmark_app的性能测试结果。