基于POT工具API模式的模型量化方法
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
在前几期关于 OpenVINO POT 工具的示例中,Ethan 老师主要分享了如何利用命令行来运行 POT 量化任务。可能很多小伙伴们还不知道,POT 还支持基于 Python API 的代码调用模式哦。相比较传统命令行的模式,使用 API 接口的调用可以更便捷的实现一些自定义的方法,例如数据加载处理和精度评估等。
接下来我们就 Notebook 示例,一起来看下 POT 工具 API 模式的基本使用方法吧。

01 课程相关准备
首先,还是和往常一样,打开 Jupyter Notebook,导入相应的依赖库。由于是使用 API 的调用方式,所以我们会导入一些 POT 相关的依赖库。
其次,需要将模型转化。我们可以通过 Pytorch 预训练模型的函数接口去加载预训练模型,再基于 ONNX export函数,将其导出为 ONNX 格式模型,最后使用 OpenVINO 的 mo 工具将它转化成 OpenVINO 所支持的 IR 格式模型。
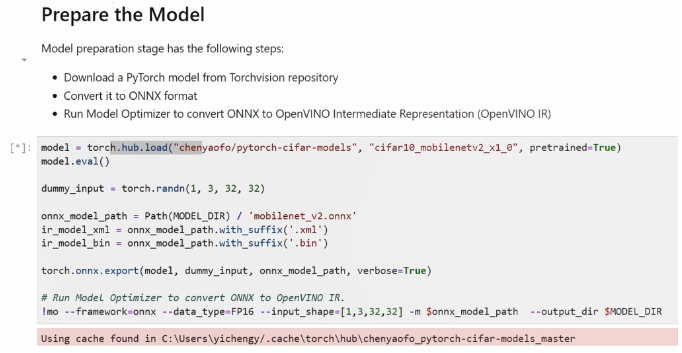
在构建量化任务之前,我们需要先定义两个接口类,并重写里边的一些关键方法和属性,才能构建量化任务。这两个接口类分别是是 data loader 和 metric,通常用它们来分别来定义数据的加载方法和模型评估的指标。由于我们需要在量化过程中去引入数据集,给量化过程中的参数做校验,所以可以参考 OpenVINO 的官方文档,了解 data loader和metric 这两个接口类如何被调用。
02 官方文档查找及说明
打开 OpenVINO 官方文档网站,来到documentation 目录下找到 model optimization guide,这里边就有关于 POT工具的使用方法说明。
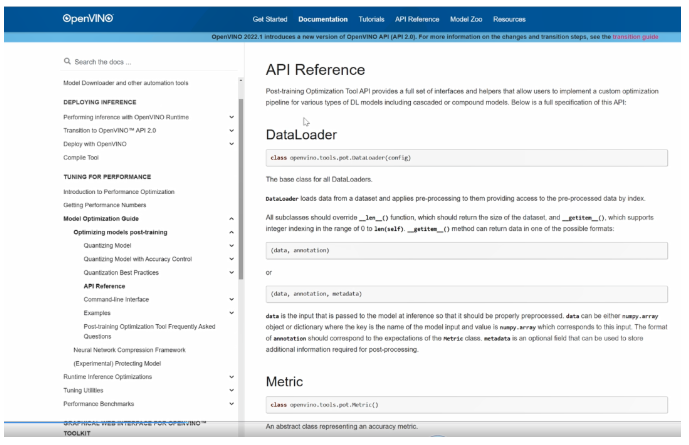
来到API相关接口的说明文档中,可以看到 data loader 的类是我们需要去重写它的一些方法,其中 len function 是用来返回数据集的长度, getitem 是用来返回数据集中的每一个元素和它相对应的标签。
返回的这两个元素,我们希望它是 numpy.array 格式的 data。此外,Annotation 需要和后面定义的 metric 里边的相应方法对应。
我们再来看下 metric 需要实现哪些关键方法和属性。
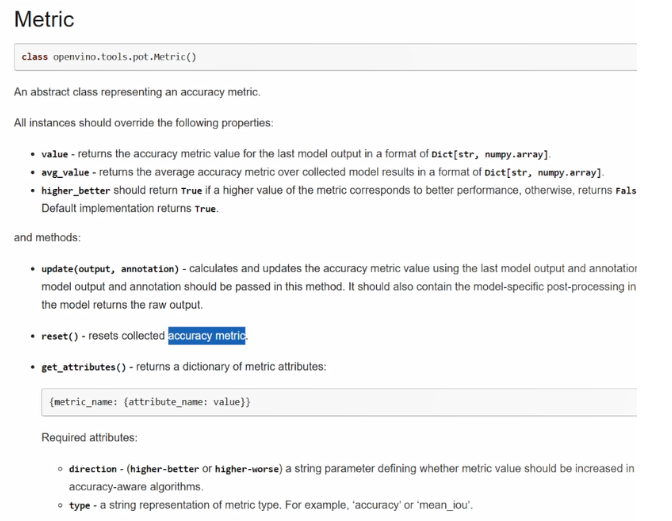
首先就是一些实例,属性需要被重写。
Value 是用来去遍历数据集对它进行一个推理测试的过程中,我们需要去获取最后一次推理输出任务的精度的结果。
avg_value 是在我们做推理任务去遍历数据集的过程中,平均的精度表现。
Higher_better 则定义了我们对于这两个 value 的评估方向是越高越好还是越低越好。
Update 是用来更新迭代每次遍历数据中模型的输出精度。
output 是指模型原始输出。
annotation 是对应之前在 data loader 中返回的原始数据及它的标签信息。
我们需要去重写这这几个方法。也就是说,我们会去通过这个方法,去迭代 value 和 avg_value 这两个值。
此外,我们还需要定义模型精度指标的重置方法,以及通过 get_attributes 来获取模型量化的一些信息,比如说量化方向是否越高越好,type 类型是通过 accuracy 方法还是通过 mean_iou 方法。
03 回到代码段
再回到代码段,我们需要下载一下 cifar 数据集,并且还要针对它做一些 transform,这里主要是用到了归一化的方法。
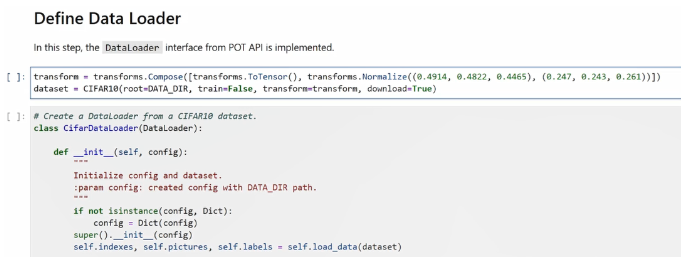
我们需要通过 CifarDataLoader 类来继承 DataLoader 类,然后重写里边的关键方法。
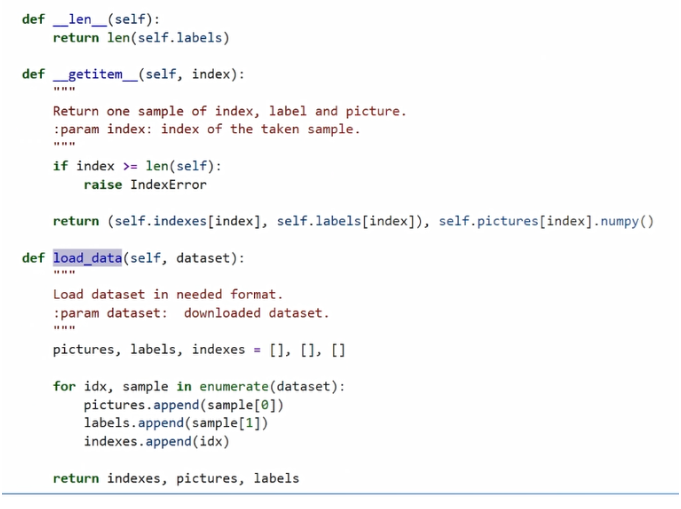
首先是 dataloader,通过 data load 这个函数,我们会完整的载入预先定义的数据集,并且返回它里边所有的标签和元素;通过 getitem 这个方法,我们会获取数据集中每一个元素和每一个标签,然后我们再通过继承 metric 的类来重写里面的方法,包括 update。
由于这次示例是一个图片的分类任务,所以我们会用到 top_k 这个评价指标。top_k 是指我们将分类任务输出,置信度最大、最高的 top_k 值做模型的输出结果。我们这次将 top_k 中的 k 定义为1,也就意味着我们会把模型输出,置信度最高第一位的结果作为我们一个评价的指标。
在 update 过程中,我们会将模型的输出进行排序,将置信度最高的作为它的输出结果,然后我们拿这个输出结果和我们的标签做匹配。如果它和标签是相等的话,我们会将 match 值置1;如果不相等的话,我们会置0。此时我们会同样去维护 matches 这样一个列表,去记录每一次模型输出的精度情况。

上方的 value 是获取 matches 列表中的最后一个元素, avg_value 是获取 matches 的平均值,也就是我们平均的进度情况。
除了需要定义重写这两个类以外,我们还需要定义一些相应的配置参数。比如说需要定义模型的输入模型的路径、pot 引擎它对底层硬件的调用方法、用到了什么硬件、资源是 CPU 还是 GPU,还有它的使用的线程数以及我们需要去定义加载数据集的路径,还有用到的量化的算法。我们目前是用到了一个默认量化的模式,此外同学们也可以定义一些例如精度感知量化模式等。

接下来,让我们构建完整的量化 pipeline。
首先,需要加载我们的模型文件,初始化 data loader,以及初始化 metric。这里引入 metric 主要有两个目的,一是稍后用 metric 输出模型在数据图上的实际精度表现;二是在某些特定的量化模式下,我们会通过 metric 这个类去加入额外的评价指标,从而实现混合精度量化的目的。由于此次我们选择默认量化模式,所以这部分原则上是可以被跳过的。
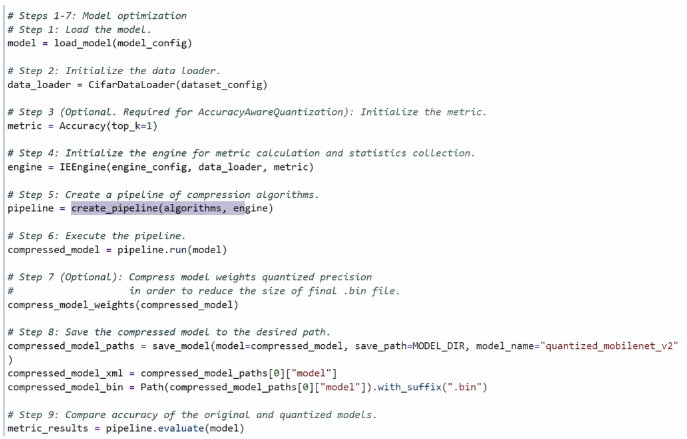
然后,需要初始化量化引擎,创建量化 pipeline,运行量化任务。完成量化任务运行以后,我们会获取量化以后的模型拓扑。我们还需要针对拓扑,同样的对权重值进行量化,将量化以后被压缩后的模型进行导出,再利用 pipeline 中的 evaluate 方法,对我们量化前和量化后的模型文件它的精度进行评估。
这里的 evaluate 方**引入刚才所定义的在 metric 类的 value 和 avg_value 这两个评价指标,输出最终的模型在实际数据集中的精度。
03代码运行验证
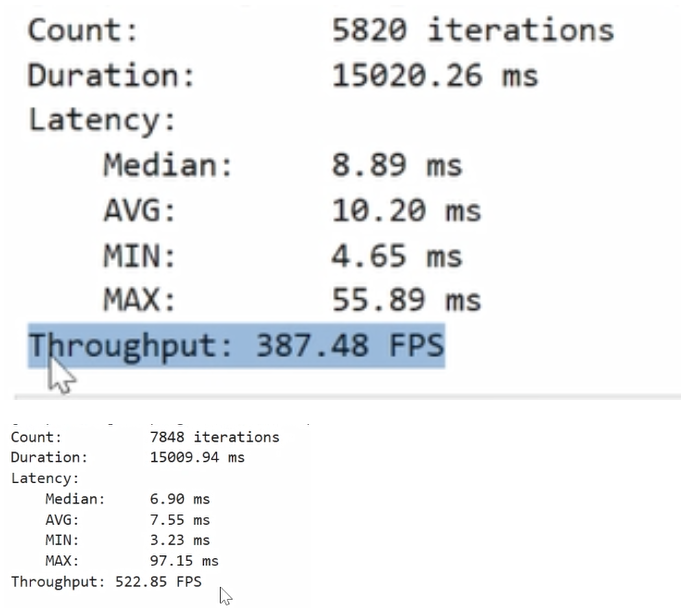
我们可以运行下代码,看下实际运行效果表现。此次也会通过 Benchmark APP来验证模型实际的性能表现。
由于,我们也想了解一下在实际数据集中精度的表现,所以此次我们挑了4张图片,让模型实际跑出来的效果,再对比原始模型和量化以后的模型对这4张图片的推理结果是否有任何的影响或改变。
最后运行结果为原始模型的在top 1上的精度是0.9347,压缩以后的模型在top 1评价指标下的精度也是0.9347。可以说,我们量化以后的的模型没有任何的精度受损。