如何基于OpenVINO POT工具简单实现对模型的量化压缩
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
原创 杨亦诚 OpenVINO 中文社区
俩周一次的Notebook系列
又和小伙伴们见面啦!
每次课程我们都会推出不同的主题
供大家学习讨论~
希望大家能发现深度学习应用开发的乐趣
用OpenVINO完成更多有成就感的瞬间。
本期课程主题是
如何基于OpenVINO POT工具简单实现对模型的量化压缩
希望小伙伴们在课程学习的思维碰撞中
能与Nono中找到共鸣~
一、课程准备
看到本次课程内容,可能大家会有Nono一样,脑海里不自觉的冒出一个问题,什么是int8 量化?

一般而言提升模型的推理性能,一般有两种途径。第一种方式是在模型的运行过程中,利用多线程等技术去实现并行加速提升推理性能。另外一种就是对我们的模型文件进行压缩,通过量化、剪枝、蒸馏等技术去压缩模型空间体积,实现更少的计算资源的消耗。OpenVINO的Post-training Optimization Tool正是这样一种量化工具,它可以将模型的参数,从fp42的高精度浮点映射到int8的低精度定点,从而压缩模型的体积,获得更好的性能表现。
今天的课程分享主题则是,基于在如何使用POT工具的simplify模式,来实现对模型的量化操作。
二、前期操作示例
首先,导入一些常规的库,设定相关环境变量。这里的环境变量主要是我们用到的数据集以及模型的文件路径,并以其命名。
接下来需要去准备用来校验的数据集。由于量化以后的模型,精度势必有所下降,所以我们需要通过引入校验数据集的方式,将模型精度重新拉回到原始精度的水平线上,去实现我们在精度不丢失或者是没有太多丢失情况下的模型压缩能力。在这一步,我们会用到pytorch自带的接口去下载CIFAR这样一个数据集,这个数据基本是用来做一些分类任务,是非常出名的数据集模板。
下载完成以后,它会被保存在cifar路径下,但是我们的原始数据集是已经被batch以后的数据集,所以为了更进一步的去使用或者去占用它,我们需要将其还原到原始的图片形态。这边我们会用到另外一个pytorch自带的接口——Python ToPILTImage,将它还原成一张张rgb格式图片,我们来运行一下。
可以看到,在另外一个路径下,已经生成了这个图片数据,也就是这一张张PNG格式的图片。
然后,我们需要去准备原始的模型文件,并对其进行压缩。这里使用到的是另外一个pytorch常用的接口,也就是通过pytorch预训练模型,并将它导出成 onnx格式的模型来实现我们对模型文件的下载。这边我们用到的是基于resnet20这样一个分类的网络,可以看到这个模型已经下载好了。

紧接着,我们需要调用mo工具。也就是说,通过model optimizer工具将它转化成OpenVINO所支持的IR中间表达式。完成之后可以看到模型model路径下已经成功生成了xml和.bin的文件,也就是OpenVINO的模型格式。
三、对模型进行压缩和量化
接下来就是本期最关键的步骤,对模型进行压缩和量化。
由于pot工具支持api接口调用以及 cmd命令行调用两种方式,为了方便演示,所以我们这边展示如何通过cmd命令行的方式对它进行调用。
第一步,我们需要指定输入模型的路径。在本次采用的量化压缩方式选择中,由于simplified模式相较于其他量化模式,配置简单,考虑到方便初学者快速的上手pot工具,我们这边采用了simplified模式对它进行演示。

第二步,去定义用来做校验的数据集路径,以及最终生成的模型的路径。
第三步,我们来跑一下这个pot工具。由于需要遍历300多数据,所以运行时间会稍微有点久。在等待过程中,我们不妨看一下原始fp32模型体积大小,可以看到它的xml也就是模型拓谷结构的文件是70KB,它的.bin也就是权重的文件,是1mb左右。
等到模型被成功的完成了量化,大家可以发现,在、新的目录下,已经生成了compressed路径。compressed路径里边有一个新的文件夹叫做optimized,也就是我们存储量化以后模型路径。
最后,我们看一下这个.bin文件的体积。可以看到int8模型的权重文件已经被缩小到274k,xml文件没有很明显的变化。整体的模型体积被压缩了将近3/4,这也是 pot工具能力的呈现。
四、性能验证
接下来就是本期最关键的步骤,对模型进行压缩和量
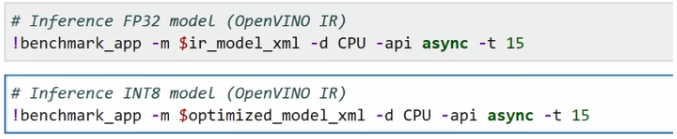
模型文件被压缩了以后,它的性能会不会有什么变化?接下来就让我们通过 benchmark app这个性能测试工具,对模型性能进行进一步的比较。
我们指定一下它的循环的时间,将其设置成15秒,我们用benchmark app测下它15秒的运行性能。第一个命令是将这个原始的fp32模型去运行它的性能指标,第二个是我们通过压缩以后的int8模型去跑一下它的性能指标。
可以看到 fp32模型最终获得的吞吐量大概是在1000fps左右,int8模型的吞吐量提升了将近两倍左右,达到了1630fps,不得不说性能提升还是非常直观的。

那性能提升以后,精度会不会有影响呢?接下来我们做个简单的实验,把 int8的模型跑一下推理任务,看一下它的最终输出的结果是否正确。
第一步也是常规的,去定义core的对象,准备一些环境变量以及标签数据,再准备一些图片可视化方法。我们需要将标签放在原始的label标签,画在我们的图像上做一个对比。
接下来,就是定义每张图片做inference的任务了。我们会逐个遍历300张图片,然后分别对其进行inference,接着会把inference最终结果的标签也就是分类的输出给它全部append到一个list里去, 这个list我们会对它进行一个比较。
好,我们首先来看一下,我们获取了最终的推理结果以后,我们去查询前三章的推理的结果和我们前三章的原始label的一个比较。
显然,能看到我们前三章的推理结果是cat,ship和ship。

由于我们是随机排序,所以看到原始 label也是cat,ship,ship,可以说最终得到的结果和原始的带标签图像的结果是一致的,这也进一步证明量化以后模型精度其实没有太多的损失,或者说它的精度是恒等于原始的模型量化之前的模型精度。