基于OpenVINO的命名实体识别(NER)应用
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
原创 杨亦诚 OpenVINO 中文社区
连日来,高温不断,翻涌的热浪令人生畏,但看到杨老师的Notebook系列又更新了,40°的天气,也抵不过技术向往带来的热忱与希望,阻挡不了Nono飞奔前来学习的步伐。
那就快来和Nono一起看下,本次课程又带来哪些惊喜吧!

01 课程准备
本次课程重点是如何使用OpenVINO来完成一个简单的实体命名提取的任务。
首先打开Jupyter Notebook来到第204个任务中,不同于以往使用 CV图像作为模型输入数据,本次我们的输入数据就是我们的文本数据。

这次用到的模型是来自Open Model Zoo中的BERT模型。模型的输入是由4个token所构成,输出主要是两个输出,分别是start position和end position,也就是文本的开始位置和文本的结束位置。
同学们可以参考这张图,对本次课程任务有更直观的了解。

图片解释:
我们会给出一个实例的类别,比如是location还是time;其次会给到一段文本。我们任务的目标就是根据给出的实例类别到文本中找出相对应的这个词。例如我的任务是要找到 location这样作为分类的词,我们可以找到这个London;如果任务是 time,就需要找June这样词,依此类推。
02 课程开始
回到notebook,开始运行代码,第一步就是加载相应的依赖库。
第二步则是从Open Model Zoo中去下载指定的BERT模型。
接下来,我们需要加载模型,并指定在CPU上进行编译。特别值得关注的是,由于LP相关任务的输入语句的长短不固定,所以这也要求模型的import layer需要能够去匹配这种不同长短的语句。

这时需要将某些input layer中的某些dimension去设置成一个dynamic shape,让它的区间变为动态的。比如说我们有一个shape操作,会把该模型的第二个import layer设置成一个动态的区间,1~384。这个时候如果句子是在384的向量范围内的,就可以自动对它进行动态冗余的识别和输入了。
然后我们清空输出,运行代码,接下来通过一些预处理模块对输入数据进行准备和构建。
2.1前处理任务准备
第一步,我们需要去找到自带的vocab。它是一个列表,列出了所有在文本中可能出现的单词,通过这个列表,我们需要把它构建成一个dictionary,也就是字典形态,让这个列表中的每一个单词都有相对应的匹配序列号,我们会通过这个序列号把它封装成一个token,来送入到模型中。
比如我们会定义一些特别类的token,比如分割符,这个CLS就代表我们可能开始,SEP代表文本和任务之间的分割,我们会找到它在dictionary中所对应的序列号,以及我们需要设定最后任务置信度的阈值,将一些置信度比较低的输出结果给它过滤掉。
第二步,我们需要去准备输入数据。可以看到输入数据是由两组构成的,一组是我们命名类别的token,也就是question;还有一组是context,是我们给出那段文本的token。

首先我们需要将它封装成一个input ID,通过在Open Model Zoo中的相关input的文档里可以看到,我们需要将它拼接成一个由entity_tokens加上 context_tokens所构成的向量。其次我们还有一个attention mask,它是全部由1所构成的,还有一个token_type_id用来划分entity_tokens和我们context_tokens的位置,可以看到entity_tokens相对应的元素会以0进行表示,context_tokens相对应的元素会以1进行表示。

同样,我们模型中还需要有一组 position_ids,给每一个向量的元素对它进行编号,编号从0开始,直到我们的整个向量的结束为止。
我们会把所有输入数据包装成一个import dictionary,也就是字典的形态,返回到我们的模型中间,进行输入。
2.2定义后处理模块
当完成了前处理任务的准备以后,我们还要去定义后处理模块。

可以看到模型的输出其实是两组向量,分别是有output_start和output_end这个过程,也就是起始位置的置信度和结束位置置信度。大家可以参考下图去理解这部分代码用意和构建原理。
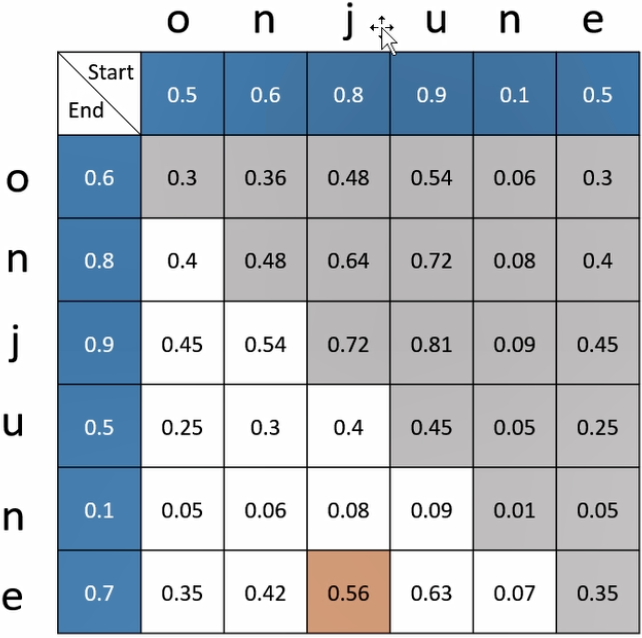
举个例子,比如说我们的文本中需要找到time词向量,所以假设输入文本是on june,所以我们得到的结果肯定是只有这样的一个词向量,它作为我们的输入的信息。此时模型的输出会有两组向量所构成,一组向量是star置信度,另外一组向量是end置信度,它代表着原始文本中每一个单词或每一个字母作为star起始位置的可能性以及每一个字母作为结束位置的可能性。
这时候我们需要将两组向量进行矩阵乘的运算,来找到作为开始可能性的字母最大的置信度,以及作为结束字母置信度最大的数,使他们的乘积最大,也就意味着这两组是一个我们匹配到的最优的起始点和最优的结束点。
可以看到,同时我们也可以发现,一般情况下我们的结束位置,肯定是要比在我们的开始位置之后的,所以我们会过滤掉一些无效的结果,因为这些成绩都意味着我们的结束点的位置其实是要更近于我们的开始点的位置的,所以我们会过滤掉图中的灰色部分。
可以看到,在有效的这些职责范围区间内,红色的点是0.56,它的置信度的相乘是最大的,也就是j作为开始点和我们e作为结束点,它所对应匹配的这个windows区间是有最大的置信度,就是最可能成为答案的这样一个结果。我们将最终把它转化为j的位置和一个e的位置,输入到我们原始的文本中去提起这一段这样的一个信息。
以上就是刚才我们这一段代码的大概含义,我们可以再简单的看一下代码部分它具体怎么做的。
2.3具体代码实现

首先会进行soft max操作,将原始输出的置信度转化成百分比的形式,然后把两个向量做一个矩阵乘的操作,就会得到我们上文看到的map,这个map就是两两单词之间的置信度的一个乘积。

接下来,我们就会进行过滤,将一些我们结束点是在开始点之前的那些位置无效值过滤掉,然后最终返回我们相乘以后结果最大的置信度的score,还有起始点的位置和结束点的位置。
完成了前处理与后处理function的封装以后,我们接下来需要把这两个function合并起来去解决问题,我需要去构建一个get_best_entity这样的function。

首先,我们会把输入文本和entity question文本全部封装成一个token的形式,然后输入到模型中进行inference推理,分别得到output_start_key和output_end_key。

然后,将这两个结果数据送到刚才的后处理任务中,得到第一组值是我们在文本中的一个位置信息,它的起始点信息和我们的接入点信息。通过这两组信息的连接,我们分别可以到文本去找到我们所要找的那段词向量,比如June。最后我们返回刚才得到的最大的置信度,因为我们最后会通过前面设定的阈值去过滤掉较低的置信度。

给到我们的任务是要找到 building、company,a person,a city等等这样的分类。我们需要去遍历所有的分类任务,然后将这些分类任务分别以entity形态送到get_best_entity形象中作为它的一个参数进行输入,而分别得到我们每一个文本中,我们所对应的任务中所要去找到的文字,接下来以json的格式去对它进行输出。

例如,我们第一段文字就是一个intel corporation is an American multinational and techniques,我们把它输入进去以后,会得到它在文本中所对应每一个词向量的单词。比如我们找到 type company的单词就是intel cooperation,找到city对应的单词是Santa Clara,找到state就是California依次类推。我们有不同的sample都会得到相应的结果。
小伙伴们有兴趣的话,也可以自己找一些相应的词向量任务,将它送到我们的模型中进行识别,看看效果是不是如此便捷?