基于OpenVINO 2022.1 POT API实现YOLOv5模型INT8量化
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
作者:孙霞克 英特尔AI框架软件工程师
概述
Ultralytics YOLOv5作为最流行的目标检测网络之一,因为其良好的工程化和文档支持,深受广大AI开发者的喜爱,也广泛地应用于工业界实践中。我们在之前的文章《基于OpenVINOTM 2022.1实现YOLOv5推理程序》及 《使用OpenVINOTM预处理API进一步提升YOLOv5推理性能》中详细介绍了:
· YOLOv5框架的安装以及如何导出YOLOv5 ONNX模型
· OpenVINOTM 2022.1的安装以及如何编写YOLOv5模型的推理程序
· 使用OpenVINOTM 2022.1的预处理API提升YOLOv5模型的推理计算性能。
在此基础上,本文将重点介绍如何使用OpenVINOTM 2022.1 Post-training Optimization Tool(POT)API对YOLOv5 OpenVINO FP32模型进行INT8量化,实现模型文件压缩,从而进一步提高模型推理性能。此外,我们提供了FP32和INT8模型精度计算方法,介绍了OpenVINO 性能测试工具Benchmark App的使用方法,并展示了基于OpenVINO backend的YOLOv5 INT8模型目标检测demo。
本文完整代码请参考OpenVINO notebook: 220-yolov5-accuracy-check-and-quantization。
1.什么是POT工具
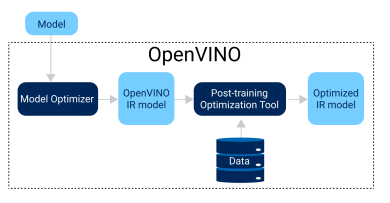
POT通过在已训练好的模型上应用量化算法,将模型的权重和激活函数从FP32/FP16的值域映射到INT8的值域中,从而实现模型压缩,以降低模型推理所需的计算资源和内存带宽,进一步提高模型的推理性能。不同于Quantization-aware Training (QAT)方法, POT在不需要对原模型进行fine tuning的情况下进行量化,也能得到精度较好的INT8模型,因此广泛地被应用于工业界的量化实践中。Fig.1展示了OpenVINO POT优化的主要流程, 我们可以看到使用POT工具需要以下几个要素:
· 一个能在CPU上运行推理程序的OpenVINO FP32/FP16 IR (Intermediate Representation)模型
· 有代表性场景的数据作为标定数据集(比如300张带标注的图片)
· 精度校验所需的验证数据集及评价精度的Metric
Fig.1 OpenVINO POT优化的主要流程
2.1. POT两种量化算法
POT提供了两种量化算法: Default Quantization和Accuracy-aware Quantization,其中Default Quantization (DQ)提供了一种快速的量化方法,量化后的模型在大多数情况下能够提供较好的精度,适合作为模型INT8量化的baseline。
Accuracy-aware Quantization (AAQ)是一种基于Default Quantization上的迭代量化算法,以DQ量化后的模型作为baseline,若INT8模型精度达到预期精度范围,则停止迭代,反之,量化算**分析模型各层对精度的影响,并将对精度影响最大的层回退到FP32精度,然后重新评估模型精度,重复以上流程,直至模型达到预期精度范围。
2.2. POT两种调用方式
POT提供了以下两种调用方式:POT命令行方式和POT API方式,其中POT命令行方式:通过命令行运行相应配置文件来调用OpenVINO Accuracy Checker Tool预定义的DataLoader, Metric, Adapter, Pre/Postprocessing等模块,这种方式适用于OpenVINO Open Model Zoo支持模型或类似模型的INT8量化。
POT API方式:提供了POT 量化流水线通用化的接口,包括DataLoader和Metric等基类,用户可以通过继承DataLoader来定义客制化的数据集加载及预处理模块,通过继承Metric来定义客制化的后处理和精度计算的模块。这种方式更加灵活,可以适用不同客制化模型的量化需求。Fig.2展示了基于POT API进行INT8量化的通用流程。
Fig.2 基于POT API进行INT8量化的通用流程
因为YOLOv5模型的前后处理模块包括letterbox,Non-maximum Suppression(NMS)与OpenVINO Accuracy Checker Tool预定义的前后处理模块不完全一致,因此我们采用基于POT API调用方式,通过集成客制化DataLoader和Metric到量化流水线,来实现YOLOv5的模型INT8量化。
2.基于POT API对YOLOv5模型进行量化
3.1. 配置YOLOv5和OpenVINO开发环境
首先,下载YOLOv5源码,安装YOLOv5和OpenVINO的python依赖。git clone https://github.com/ultralytics/yolov5.git -b v6.1
cd yolov5 && pip install -r requirements.txt && pip install \ openvino==2022.1.0 openvino-dev==2022.1.0 然后,通过YOLOv5提供的export.py将预训练的Pytorch模型转换为OpenVINO FP32 IR模型,Fig.3展示了模型转换的输出结果。
python export.py --weights yolov5m/yolov5m.pt --imgsz 640 \
--batch-size 1 --include openvino 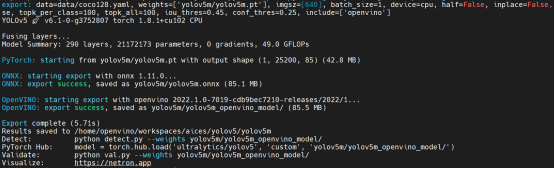
Fig.3 YOLOv5 Pytorch模型转换为OpenVINO FP32 IR模型输出结果
接下来,我们按以下步骤来实现基于POT API的量化流水线:
· 创建YOLOv5 DataLoader Class:定义数据和annotation加载和预处理
· 创建COCOMetric Class:定义模型后处理及精度计算方法
· 设置量化算法及相关参数,定义并运行量化流水线
3.2. 创建YOLOv5DataLoader Class
首先,我们通过继承POT DataLoader基类来定义客制化的YOLOv5Dataloader子类。我们节选了部分代码如下,其中_init_dataloader(self)函数调用YOLOv5自定义的create_dataloader()函数读取数据集并通过letterbox改变输入图片尺寸。此外,每次调用函数__getitem__(self, item)会读取index为item的输入图片和对应的annotation,并对图片做归一化处理,最后返回item,annotation和预处理后的图片。class YOLOv5DataLoader(DataLoader):
""" Inherit from DataLoader function and implement for YOLOv5.
"""
def _init_dataloader(self):
dataloader = create_dataloader(self._data_source['val'],
imgsz=self._imgsz, batch_size=self._batch_size,
stride=self._stride, single_cls=self._single_cls,
pad=self._pad, rect=self._rect, workers=self._workers)[0]
return dataloader
def __getitem__(self, item):
try:
batch_data = next(self._data_iter)
except StopIteration:
self._data_iter = iter(self._data_loader)
batch_data = next(self._data_iter)
im, target, path, shape = batch_data
im = im.float()
im /= 255
nb, _, height, width = im.shape
img = im.cpu().detach().numpy()
target = target.cpu().detach().numpy()
annotation = dict()
annotation['image_path'] = path
annotation['target'] = target
annotation['batch_size'] = nb
annotation['shape'] = shape
annotation['width'] = width
annotation['height'] = height
annotation['img'] = img
return (item, annotation), img 3.3.创建COCOMetric Class
接下来我们通过继承POT Metric基类创建COCOMetric子类, 该类集成了YOLOv5原生的后处理NMS函数和计算精度的方法,可以用来计算基于COCO数据集Mean Average Precision(mAP)精度,包括AP@0.5和AP@0.5:0.95。其中update(self, output, target)函数有output和target两个输入,分别是模型推理结果的原始输出和输入图片对应的annotation。模型原始输出经过YOLOv5 NMS后处理后,会与annotation一起计算得到该输入图片的目标检测精度统计数据。最后,_process_stats(self, stats)以所有图片的精度统计数据stats为输入,计算得到包括AP@0.5和AP@0.5:0.95的模型精度。class COCOMetric(Metric):
""" Inherit from DataLoader function and implement for YOLOv5.
"""
def _process_stats(self, stats):
mp, mr, map50, map = 0.0, 0.0, 0.0, 0.0
stats = [np.concatenate(x, 0) for x in zip(*stats)]
if len(stats) and stats[0].any():
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=False, save_dir=None, names=self._class_names)
ap50, ap = ap[:, 0], ap.mean(1)
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
np.bincount(stats[3].astype(np.int64), minlength=self._nc)
else:
torch.zeros(1)
return mp, mr, map50, map
def update(self, output, target):
""" Calculates and update***etric value
Contains postprocessing part from Ultralytics YOLOv5 project
:param output: model output
:param target: annotations
"""
annotation = target[0]["target"]
width = target[0]["width"]
height = target[0]["height"]
shapes = target[0]["shape"]
paths = target[0]["image_path"]
im = target[0]["img"]
iouv = torch.linspace(0.5, 0.95, 10).to(self._device) # iou vector for mAP@0.5:0.95
niou = iouv.numel()
seen = 0
stats = []
# NMS
annotation = torch.Tensor(annotation)
annotation[:, 2:] *= torch.Tensor([width, height, width, height]).to(self._device) # to pixels
lb = []
out = output[0]
out = torch.Tensor(out).to(self._device)
out = non_max_suppression(out, self._conf_thres, self._iou_thres, labels=lb,
multi_label=True, agnostic=self._single_cls)
# Metrics
for si, pred in enumerate(out):
labels = annotation[annotation[:, 0] == si, 1:]
nl = len(labels)
tcls = labels[:, 0].tolist() if nl else [] # target class
_, shape = Path(paths[si]), shapes[si][0]
seen += 1
if len(pred) == 0:
if nl:
stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
continue
# Predictions
if self._single_cls:
pred[:, 5] = 0
predn = pred.clone()
scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
# Evaluate
if nl:
tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
correct = proces***atch(predn, labelsn, iouv)
else:
correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool)
stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls))
self._stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls))
self._last_stats = stats 3.4.设置POT的量化参数
创建好YOLOv5DataLoader和COCOMetric类之后,我们可以用get_config()设置POT量化流水线中model,engine,dataset,metric和algorithms的参数。以下我们节选了algorithms部分的config,这里我们选择“DefaultQuantization”量化算法来快速获得最佳性能的模型。此外,针对采用non-ReLU activation的YOLOv5模型,我们通过设置"preset": "mixed"来对模型weights进行对称量化,并对模型activation进行非对称量化,从而更好地保证量化后模型的精度。def get_config():
""" Set the configuration of the model, engine,
dataset, metric and quantization algorithm.
"""
algorithms = [
{
"name": "DefaultQuantization", # or AccuracyAwareQuantization
"params": {
"target_device": "CPU",
"preset": "mixed",
"stat_subset_size": 300
}
}
]
config["algorithms"] = algorithms
return config 3.5.定义并运行量化流水线
接下来,我们以下面的代码逐步演示如何定义和运行量化流水线,其中包括模型加载、量化所需的DataLoader,Metric,Engine和Pipeline初始化、FP32模型精度校验、INT8模型量化、INT8模型精度校验等步骤。最终,量化生成的OpenVINO INT8 IR模型会被保存在本地。""" Download dataset and set config
"""
config = get_config()
init_logger(level='INFO')
logger = get_logger(__name__)
save_dir = increment_path(Path("./yolov5/yolov5m/yolov5m_openvino_model/"), exist_ok=True) # increment run
save_dir.mkdir(parents=True, exist_ok=True) # make dir
# Step 1: Load the model.
model = load_model(config["model"])
# Step 2: Initialize the data loader.
data_loader = YOLOv5DataLoader(config["dataset"])
# Step 3 (Optional. Required for AccuracyAwareQuantization): Initialize the metric.
metric = COCOMetric(config["metric"])
# Step 4: Initialize the engine for metric calculation and statistics collection.
engine = IEEngine(config=config["engine"], data_loader=data_loader, metric=metric)
# Step 5: Create a pipeline of compression algorithms.
pipeline = create_pipeline(config["algorithms"], engine)
metric_results = None
# Check the FP32 model accuracy.
metric_results_fp32 = pipeline.evaluate(model)
logger.info("FP32 model metric_results: {}".format(metric_results_fp32))
# Step 6: Execute the pipeline to calculate Min-Max value
compressed_model = pipeline.run(model)
# Step 7 (Optional): Compres***odel weights to quantized precision
# in order to reduce the size of final .bin file.
compres***odel_weights(compressed_model)
# Step 8: Save the compressed model to the desired path.
optimized_save_dir = Path(save_dir).joinpath("optimized")
save_model(compressed_model, Path(Path.cwd()).joinpath(optimized_save_dir), config["model"]["model_name"])
# Step 9 (Optional): Evaluate the compressed model. Print the results.
metric_results_i8 = pipeline.evaluate(compressed_model)
logger.info("Save quantized model in {}".format(optimized_save_dir))
logger.info("Quantized INT8 model metric_results: {}".format(metric_results_i8)) 3.6.YOLOv5m FP32和INT8模型精度比较
Fig.4展示了YOLOv5m FP32及INT8模型精度的比较,我们可以从图中看到,相对FP32模型,通过“DefaultQuantization”算法量化后的INT8模型的精度下降控制在1%以内,对于目标识别的网络,这种程度的精度下降一般是可以接受的,如果用户对INT8模型有更高的精度要求,建议可以尝试采用“AccuracyAwareQuantization”的算法对INT8模型做进一步迭代优化。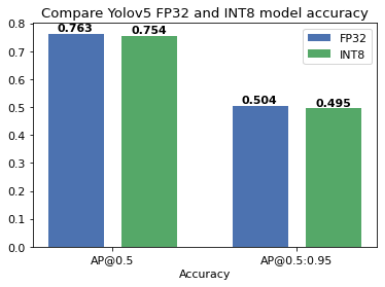
Fig.4 YOLOv5m FP32及INT8模型精度AP@0.5, AP@0.5:0.95比较
3.7.OpenVINO性能测试工具Benchmark App介绍
OpenVINO提供了性能测试工具Benchmark App,方便开发者快速测试OpenVINO模型在不同的硬件平台上的性能。我们以下面的例子,简单介绍benchmark app的使用方法和相关参数,更多内容请参考Benchmark App官方文档。benchmark_app -m \
./yolov5/yolov5m/yolov5m_openvino_model/optimized/yolov5m.xml \
-i ./yolov5/data/image***us.jpg -d CPU -hint throughput benchmark_app提供了Python和C++的两种版本,我们使用通过openvino-dev安装的Python版本的benchmark_app来进行性能测试,涉及到的参数包括:
· -m: 指定OpenVINO模型文件.xml的路径。这里我们设置为量化后的YOLOv5 INT8模型路径。
· -i: 指定性能测试使用的输入数据文件/文件夹路径。这里我们选择bus.jpg图片作为输入,若-i缺省,benchmark_app会自动生成与模型输入尺寸相应的随机数据作为输入。
· -d: 指定性能测试的目标硬件。这里我们选择CPU作为测试硬件进行推理,用户可以选择其他OpenVINO支持的目标硬件。若-d缺省, CPU会被默认选择为目标硬件。
· -hint: 指定性能测试的优先策略,以自动选择底层性能优化相关参数。这里我们选择throughput模式来提升系统整体吞吐量。如果应用对延迟比较敏感,推荐使用latency模式来减少推理延迟。
开发者可以参考上述例子,针对自己的硬件平台和使用场景,选择合适的性能测试参数来对YOLOv5 FP32及INT8模型进行性能测试。
3.8.YOLOv5 INT8模型推理demo
最后,我们用以下命令行,运行基于OpenVINO backend的YOLOv5m INT8模型推理demo。cd yolov5 && python detect.py \
--weights ./yolov5m/yolov5m_openvino_model/optimized/yolov5m.xml Fig.5展示了推理的输入图片及INT8模型的推理结果,我们可以看到,INT8模型以较高置信度检测到了图片中的所有车和行人bounding box和label。
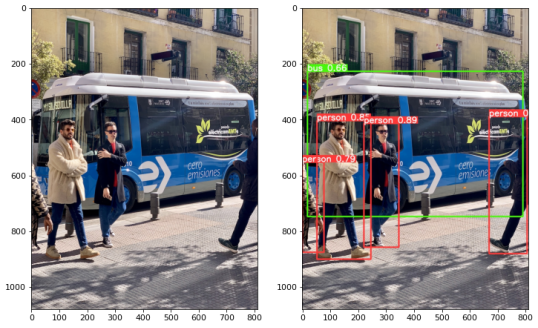
Fig.5 基于OpenVINO backend的推理demo的输入图片(左图)及目标检测结果(右图)
3.小结
本文基于Ultralytics YOLOv5源码,将预训练的YOLOv5m Pytorch模型转换为OpenVINO FP32 Intermediate Representation (IR)模型。下一步,通过OpenVINO Post-Training Optimization Tool (POT) API来定义客制化DataLoader和Metric,从而复用YOLOv5客制化的前后处理(letterbox,Non-maximum Suppression)及精度计算等模块。采用“DefaultQuantization”的量化算法,定义和运行量化流水线对FP32模型进行INT8量化。此外,通过与FP32模型精度比较,我们发现采用“DefaultQuantization”算法量化的INT8模型已经具有较好的精度(AP@0.5, AP@0.5:0.95精度下降都小于1%)。然后,我们介绍了OpenVINO性能测试工具Benchmark App的使用方法。最后,我们通过基于OpenVINO backend的demo演示了YOLOv5m INT8模型推理的效果。4.参考文献
· Ultralytics YOLOv5· OpenVINO Post-training Optimization Tool
· Open Model Zoo
· Accuracy Checker
· Benchmark App