Deci 和英特尔如何在 MLPerf 上实现高达 16.8 倍的吞吐量提升和 +1.74% 的准确性提升
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
作者: Amos Gropp — Deci AI 和 Guy Boudoukh — 英特尔实验室
翻译:李翊玮
MLPerf 提交概述
MLPerf是由来自学术界,工业界和研究实验室的AI领导者建立的非营利组织。MLPerf的目标是为机器学习硬件,软件和服务的训练和推理性能提供标准化和无偏见的基准测试。MLPerf会进行测试以不断改进和发展这些基准测试,每个基准测试都由模型、数据集、质量目标和延迟约束定义。
今年,Deci和英特尔®合作提交了计算机视觉和NLP类别的联合提案。对于计算机视觉,我们向ResNet50类别提交了三个模型。我们的提交是在开放部门的离线场景下提交的。
Deci 和英特尔的提交结果
我们在两个不同的硬件平台上提交了意见书:一个是 12 核 Intel Cascade Lake CPU,另一个是具有不同 4 核和 32 核的 Intel Ice Lake CPU。模型在 32 的批量大小上进行了优化,并使用英特尔® OpenVINO™工具包量化为 INT8。 与基准 ResNet50 型号(32 位)相比,Deci的精度提高了1.74%,吞吐量提高了10到16.8倍,具体取决于硬件类型,如表1所示。
为了进一步区分由于使用AutoNAC生成的DeciNets而进行的改进,我们将编译的8位ResNet-50与我们提交的模型进行了比较。这表明Deci的AutoNAC技术提高了2.8倍至4倍 。
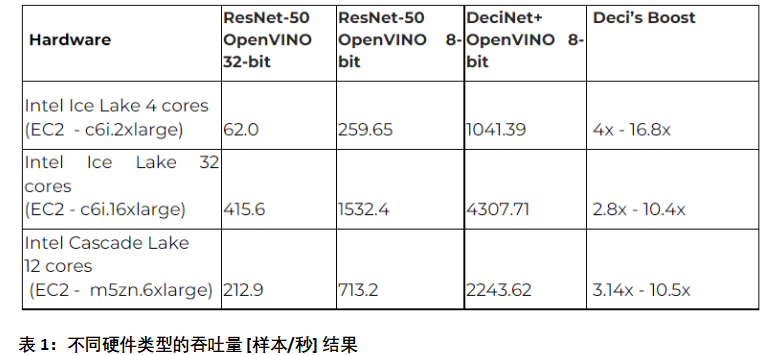
表 1:脱机方案 — 吞吐量为image/s。测试了两种硬件类型。第二列介绍了使用OpenVINO编译的ResNet-50 到32位。第三列显示 ResNet-50,编译为 8 位,标记为 DeciNet 的列显示 AutoNAC 生成的 8 位编译的 DeciNet 模型。
我们如何取得这些成果:
提交的起点是ResNet-50,在ImageNet上的准确性为76.1%。最初的目标是最大限度地提高吞吐量,同时保持相同的准确性。为了实现更好的性能,我们应用了Deci专有的自动神经架构构建(AutoNAC)技术。Deci的AutoNAC是一种依赖于数据和硬件的架构优化算法。 AutoNAC 可为深度学习任务、数据集和推理硬件的任何给定组合自动生成一流的深度学习模型。应用 AutoNAC 是一个无缝的过程,在该过程中,用户提供经过训练的模型、训练和测试数据集,并访问应在其上部署模型的硬件平台。 然后,AutoNAC 会自动计算新的低延迟、高吞吐量或低功耗模型,以保持原始模型的准确性。AutoNAC 优化过程如图 1 所示。
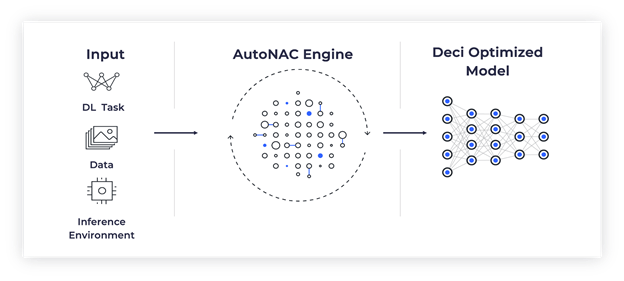
图1:Deci的 AutoNAC 流程
与标准NAS技术不同, AutoNAC 通过大量使用基线模型从相对良好的初始点开始搜索过程 。 包括几个已经训练好的层。
AutoNAC 应用于根据目标硬件中支持的允许的神经运算设置的架构离散空间。(专有)搜索算法本身依赖于预测模型来确定有效的优化步骤。此算法导致收敛时间非常快,通常比已知的 NAS技术低几个数量级。此外,AutoNAC 的主要优点之一是它能够考虑推理堆栈的所有级别并优化基线体系结构,同时保持准确性并考虑目标硬件、(硬件相关)编译和量化。
去年 ,AutoNAC 发现了一个新的图像分类模型系列,称为DeciNets,它在准确性和运行时性能方面都优于众所周知的最先进的模型。
我们提交给 MLPerf 的 DeciNets 由 AutoNAC 生成,专门设计用于在英特尔®的 Cascade Lake 和 Ice Lake CPU 上运行时提供最佳性能。
逐年改进
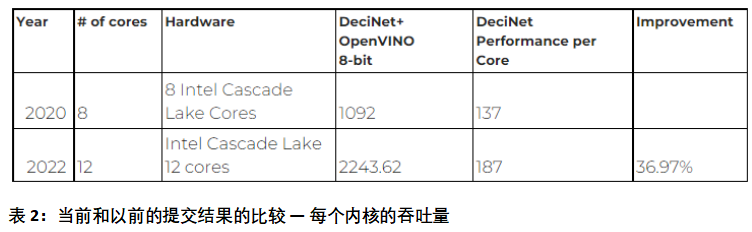
两年前,即2020年,Deci.ai 和英特尔将模型提交到同一 MLPerf 类别。在评估每个内核时,我们可以看到,与之前提交相比,吞吐量性能提高了约 37%。
深度学习推理中 CPU 的下一步是什么
我们提交的模型将 ResNet-50 的吞吐量性能提高了 16.8 倍,并且准确性提高了 1.74%。这是通过英特尔的OpenVINO ™编译器和Deci的AutoNAC生成的DeciNets模型之间的协同作用来实现的。
这标志着 Deci 与英特尔在 CPU 上实现深度学习出色推理的持续合作中的又一个重要里程碑。准确性和吞吐量的这种重大提高具有许多直接影响。
使用 DeciNets,以前由于资源太密集而无法在 CPU 上执行的任务现在成为可能。此外,这些任务将看到明显的性能改进:通过利用DeciNets,模型在GPU和CPU上的推理性能之间的差距将减少一半,而不会牺牲模型的准确性。
Deci的 AutoNAC 技术及其 自动生成的 DeciNets 已准备好进行部署和商业用途,并且可以轻松集成以支持各种硬件类型上的任何计算机视觉任务。
配置详细信息:
c6i.2xlarge
8 vcpu (英特尔®至强®铂金 8375C 处理器), 16 GB 总内存, bios: SMBIOS 2.7, ucode: 0xd000331, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 编译器.基线:Resnet50,精度=76.4; DeciNet,精度=78.14
c6i.16xlarge
64 vcpu (英特尔®至强®铂金 8375C 处理器), 128 GB 总内存, bios: SMBIOS 2.7, ucode: 0xd000331, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 编译器.基线:Resnet50,精度=76.4; DeciNet,精度=78.14
m5zn.6xlarge
24 vcpu (英特尔®至强®铂金 8252C 处理器), 96 GB 总内存, bios: SMBIOS 2.7, ucode: 0x500320a, Ubuntu 18.04.5 LTS, 5.4.0–1069-aws, gcc 9.3.0 编译器.基线:Resnet50,精度=76.4; DeciNet,精度=78.14
通知和免责声明
性能因使用情况、 配置和其他因素而异。在www.Intel.com/PerformanceIndex 了解更多信息。
性能结果基于截至配置中显示的日期的测试,可能无法反映所有公开可用的更新。有关 配置详细信息,请参阅备份。没有任何产品或组件是 绝对安全的。
您的费用和结果可能会有所不同。
英特尔技术可能需要支持的硬件、 软件 或服务激活。
© 英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。文中涉及的其他名称和品牌可能是其他方的财产。