在英特尔®硬件上部署深度学习模型的无代码方法 关于 OpenVINO™ 深度学习工作台的三部分系列 第三部
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
第三部分:重新校准精度并打包您的TensorFlow模型,以便使用OpenVINO™深度学习工作台进行部署
在第二部分中,我们向您展示了如何使用 OpenVINO™ 深度学习工作台导入 TensorFlow 模型,将其转换为英特尔® IR,对其进行基准测试,并为优化的推理模型设置性能级别。
在第三部分中,我们将深入探讨一些在工作台中进行分析和优化的高级工具。然后,我们将向您展示如何打包生产就绪推理模型。
注意:如果您尚未注册,请注册DevCloud for the Edge。它是免费的,只需要几分钟。如果您想在注册之前进行探索,请查看我们的第一篇文章。
第一步:将TensorFlow模型校准为INT8
我们在第二部分中选择的处理器,英特尔®至强® 6258R(又名Cascade Lake),具有英特尔®深度学习加速,可加速INT8精度的性能。让我们看看当我们将模型从FP32校准到INT8时性能如何变化。
我们的第一个英特尔®至强 6258R 基准测试的吞吐量为每秒 383.83 帧,延迟为 2.58 毫秒, 大部分 处理(占 99.58%)以 FP32 运行。
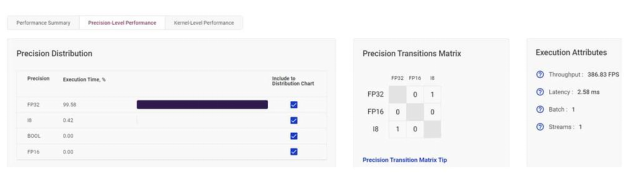
在FP32上,我们的第一个基准测试以每秒386.83帧的速度运行,延迟为2.58毫秒。
当我们将同一实验校准为INT8时,我们看到了显着的性能提升。吞吐量几乎翻了一番,达到每秒 765.84 帧,延迟缩短了一半,达到 1.29 毫秒。
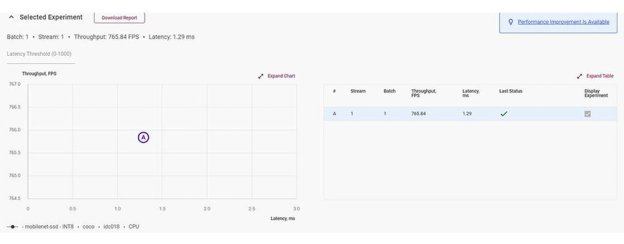
在INT8,性能大约翻了一番。
校准不会将每个操作都切换到 INT8。FP32精度仍然在混合中。在校准期间,工作台运行FP32和INT8的多种组合,然后测试和检查吞吐量和速度。这个过程可能需要一段时间,但完成后,您将拥有一个达到最佳平衡的混合模型。
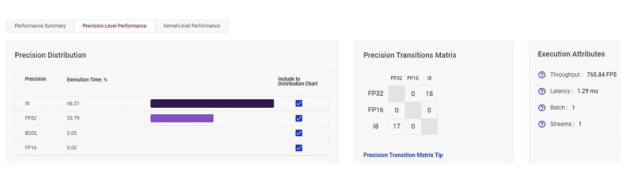
校准混合精度级别,以创造最佳性能。
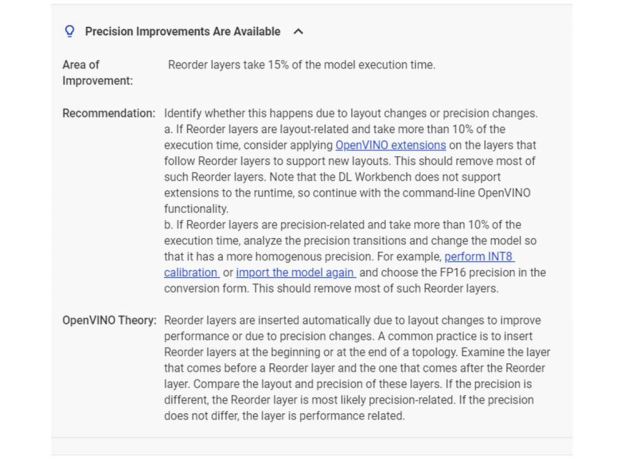
深度学习工作台可识别推理效率低下的问题,并提出改进建议。
第二步:打包 TensorFlow 模型以进行部署
一旦我们达到了吞吐量和延迟的正确平衡,我们就可以打包模型进行部署。我们所要做的就是转到“包”选项卡,然后选择我们的目标硬件以及我们要包含在包中的内容。就这么简单。
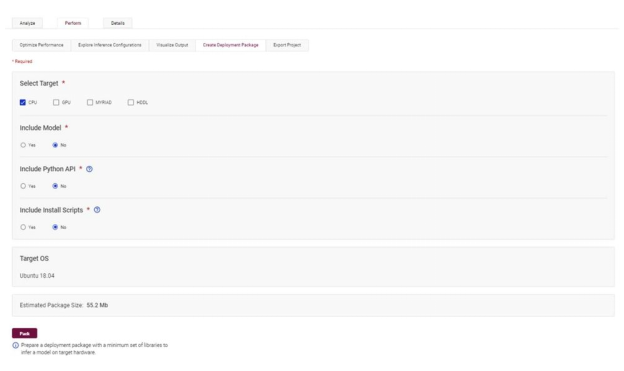
工作台会自动打包优化和校准的模型。
结论
这是我们关于使用 OpenVINO™ 深度学习工作台和面向边缘的英特尔® DevCloud 创建部署就绪推理模型的三部分系列文章的结尾 。现在,您知道了如何优化 TensorFlow 模型并在任何英特尔®架构上运行它,而您所需要的只是一个 Web 浏览器!