超大规模云网络数据中心创新(上)
 小o
更新于 5年前
小o
更新于 5年前
作者简介:马绍文,邮箱:mashaowen@gmail.com
1.云网络趋势和流量变化
随着云计算的发展,Internet 从最早承载海量文本/图片/视频,演变到高清直播占据 Internet 主要流量(Netfliex/AWS, Youtube/Google, Facebook Live/TickTok)。随着 AR 相机 和社交VR(Social VR)的等新应用的到来,互联网的流量还会持续高速增长。Google的一篇论文讲,每9个月Google数据中心流量翻倍,每5年数据中心流量增长100倍。大部分的流量增长并没有体现在运营商SP的网络中,而是主要集中在OTT网络中。
Google/Facebook/AWS/Microsoft/Apple 为代表五大OTT都构建了全球规模的骨干网,很多人也称之为『Private Internet』。OTT的数据中心/WAN/PoP流量快速增长,带来OTT网络架构的快速迭代和升级。传统的设备形态和网管工具 无法适应流量和业务的快速发展。OTT纷纷采用自研设备,引入SDN 来管理全球骨干网。
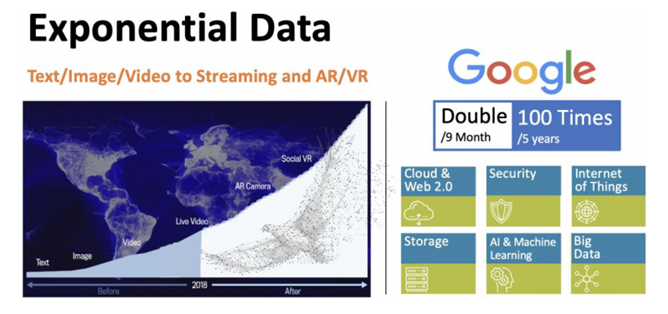
伴随云网络流量的极速增长,云网络的负载也发生了天翻地覆的变化。30年前发明的传统TCP/IP,已经不能适应大规模视频和AI发展的需求。
南北向流量:从超大规模数据中心,边缘POP点到终端用户的App/Browser,很多云公司已经大规模部署QUIC。引入QUIC能带来更优的拥塞流控,Multi-Streaming 控制,更安全的报文全加密,并且接入SDN(Google Espresso)进行每用户全局调控。Google发表的***提到自从2014年开始大规模部署,到2018年底,35%的 Google南北向流量(大概 10%的 Internet 流量)已经承载在QUIC协议上。其他主流云公司例如微软,Facebook,Apple 和 Akamai 等也纷纷采用QUIC。
东西向流量:AI/ML计算需要Tensor flow运行在成百上千个GPU节点,需要分布在多个机柜之 间的服务器传送大量数据和中间计算结果。多个GPU和高端存储之间缺省采用新型的 RoCEv2 来提供更高的网络性能和避免拥塞。
数据中心之间的大规模备份和都越来越多的采用TCP-BBR(Bottleneck Bandwidth and Round-trip propagation)拥塞控制算法来应对 Internet 丢包,提供 DC 之间高达几个Tbps的吞吐。在部署了TCP BRR之后,B4(Google DCI)网络性能提高了 2~20 倍。云公司,不光把TCP-BBR 用在自家数据中心互联,同时还提供给所有的云客户。比如客户在 Google GCP上创建VM,服务器侧自动采用最新的支持TCP BRR内核。著名的Amazon CloudFront,CloudFlare等公司也纷纷采用TCP BRR。
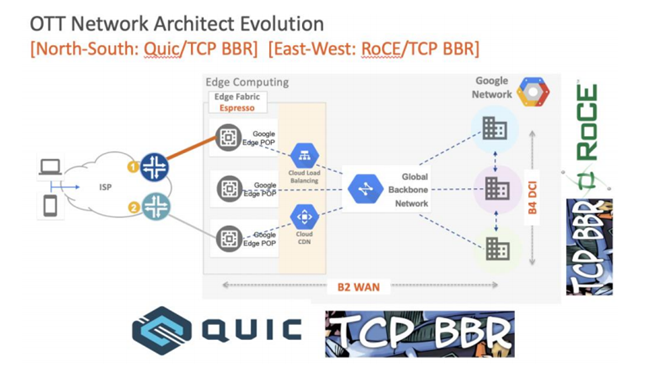
数据中心东西向和南北向负载和流量的变化,越来越依赖服务器智能网卡支持 QUIC/TCP BRR 和RoCEv2 等更多新型协议和技术和CPU负载卸载(offload)。
AI/ML 的蓬勃发展,异构计算(Heterogeneous Computing)在数据中心引入了各种多核心 CPU 处 理器、GPU 图形核心、TPU(Tensor Flow)、DSP、ASIC、FPGA 等融合处理器多种设备的架 构。传统的以 CPU 为中心的数据中心设计理念已经不能满足大规模 GPU 集群,大容量高速 SSD 海量存储器和特殊 FPGA 加速的要求。2019 年很多公司提出来 IPU(I/O Processing Unit)/DPU(Data Processing Unit)等以 SmartNic 为中心的全新数据中心设计思路。相关理念也在云公司 比如微软 Auzre/亚马逊 AWS 的云网络中得以实现。
以 Smartnic 为中心的数据中心架构设计,中心思想就是 Offload CPU 的功能。传统 GPU, SSD, FPGA 数据跨服务器通讯都需要通过 CPU 中转,CPU 成为网络发展的瓶颈。引入IPU之后,传统的GPU和SSD可以更有效的通过RoCEv2和NVMEoF来提供更高带宽和低延时业务。
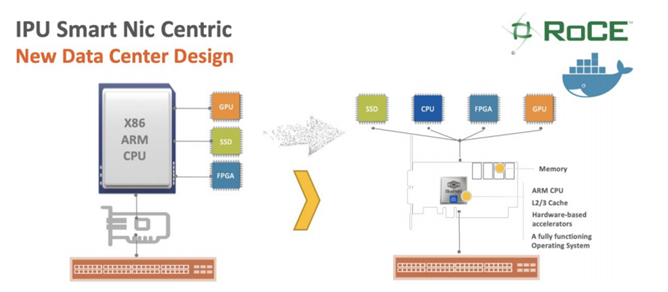
IPU提供类似AWS Nitro的全方位 SDN 网络,SDS存储和SDSec安全支持,并且大部分功能可以卸载到网卡,支持接近裸机性能的全新云网架构。
2.数据中心Underlay网络架构
2.1 Scale Up 和 Scale Out 网络
传统大规模数据中心从4-POST(2004 年设计)演变而来,Google 最早采用4个大型交换机(路由器,Cluster Router)来连接 512 个 TOR 机柜交换机,每个 Cluster Router16 槽位 x 32 端口能提供512个1GE到TOR(Top Of Rack 机柜顶端交换机)。每个TOR接到4个Cluster Router 提供多上行冗余。
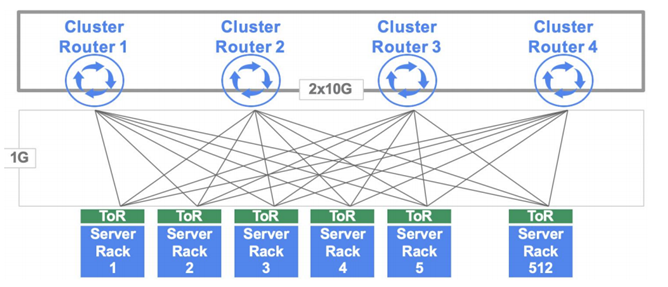
随着超大规模数据中心计算能力和带宽需求越来越高,一个数据中心机房里的 TOR 交换机数量可达3000~5000,单个设备很难支持数千个10GE/25GE/100GE接口。而且大型设备的开发周期很长,数量很少(一个数据中心只需4个),成本很高。大型 OTT纷纷开始在其数据中心中采用CLOS架构,利用数量众多,小规模的基本交换矩阵(CrossBar)来构建超大规模网络Fabric。
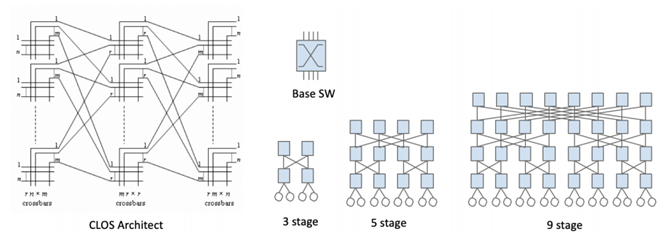
CLOS 网络架构的级数Stage,是基于路径上经过多少跳。比如上图中的3-stage 是最简单的,Leaf/Spine两层,但是从一个服务器到另一个机柜的服务器,经过三跳。以此类推,5-stage 是三层,9-stage是四层架构。
最早的 CLOS 架构应用于构建大型多板卡路由器和交换机。解决单芯片容量不足问题。
2014 年,业界最高密度的单交换芯片仅能提供3.2Tbps(32x100GbE)。Facebook 想要建设超大规模数据中心,一个机房要求能够容纳超过5千个机柜的超大型交换矩阵。架构师决定采用128端口扇出的盒子作为5级CLOS的Spine/Super Spine。BackPack(背包)架构师采用了无阻塞的 Spine/Leaf 架构来构造一个7RU的盒子。其中4个3.2T芯片作为交换矩阵(spine),另外8个3.2T芯片分布到4个业务板卡,每个板卡上有两个3.2T芯片(每个芯片 1.6T 到用户,1.6T 到 Fabric/Spine),总共可以提供16x8=128x100GE用户接口。

对于128x100GE Fabric,可以采用 7RU 的 BackPack 设计,也可以采用 12 个 1RU 的 3.2T (4+8 Spine/Leaf) 设计。BackPack的优缺点如下:
- 128端口扇出,无阻塞,空间占比更优(7RU vs 12RU),板卡级别共享风扇/电源模块。
- 节省 Pizzabox 盒子之间互联的光模块/Cable,采用低价的SerDes 进行板卡级别互联。
- 由于 Backpack 的多颗 Spine/Leaf 芯片只能在同一个机柜,导致到 TOR 交换机距离过长,只能采用更为昂贵的CWDM4光模块。如果采用12个Spine/Leaf 盒子分布到多个楼层的机柜可以采用更便宜的 AOC/SR 光模块达到同样的效果,总体两种方案 TCO 相差不大。
- BackPack 跟传统设备提供商C/J的路由器交换机设计理念完全不一样。每个板卡和交换矩阵都有 CPU,都运行BGP路由协议。板卡之间的MAC/IP Prefix交换也通过BGP。单个BackPack设备,有多个BGP Speaker节点。属于很奇葩的设计。
Facebook 在 2014 年开始设计了 F4 数据中心 Fabric 架构,采用128端口扇出的 Backpack 盒子作为Spine/SuperSpine。如下图立方体(Cubic)设计。

F4 秉承 4-Post 的设计理念,把 4 Post 的四个大路由器替换成四个 Fabric 平面。用 128 端口的Leaf/Spine Fabric 来代替超大型单台多槽位交换机实现 Scale Out 设计。
- RSW(Rack Switch):每个POD 48台TOR交换机汇聚到4台 Fabric Switches 分属四个不同的 平面;POD 可以横向扩展 Scale Out。最多 128 个 POD(包括 Edge POD)。
- FSW(Fabric Switch):每个平面最多128 台 FSW ,4台Fabric 交换机分别上联到四个平面的Spine Switches,Spine平面是完全隔离的。
- SSW(Spine Switch):48 台SSW和最多128台 FSW组成一个平面。汇聚所有的 POD 流量。
- ESW:Edge switch POD(淡黄色部分)里的Edge Switch 和 SSW 互联,可以弹性扩展连往其他 DC,或者去往 Backbone 和互联网的流量
- 超大规模:每个 SSW 有 128 个端口,所以最多接 128 个 FSW,同时还有至少四个FSW作为Edge switch,所以一个数据中心平面可以支持大概120个FSW。也就是120个POD。所以一个F4 数据中心可以最多支持:120x48=5760 RSW,也就是大概 6000 个机柜。
各大云公司采用的架构不太一样,比如 Facebook F4 fabric 采用 BackPack 来构建 5-stage (如果算Chip,每个Backpack 3 stage CLOS,总共 9-Stage Chip) CLOS 架构。
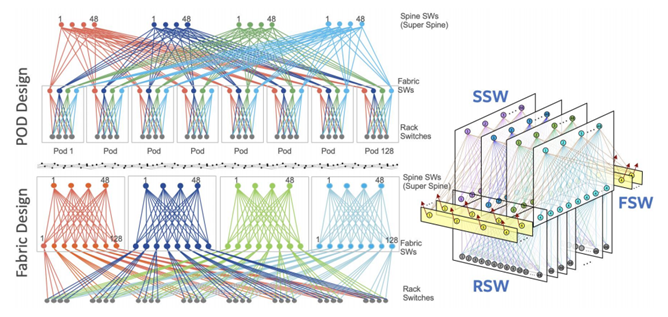
其实Facebook的立方体架构就是普通的5级CLOS。上图中可以看到,如果把右面的立方体四个平面展开(每个平面就是原本 4-Postd 的一个大交换机),就是左下图基于 Fabric 的设计,48 Spine SW+128个Fabric Switches属于同一个平面,每个Fabric Switches接一个POD里的48个Rack Switch。然后左下图的Fabric Design中Fabric Switch 移动到相应的128个POD,就是左上图的基于POD的设计。所以可以看出来虽然三张图画法不同,设计理念不同,但是殊途同归,都是 5 Stage-CLOS 来支持 5~6千机柜的设计。
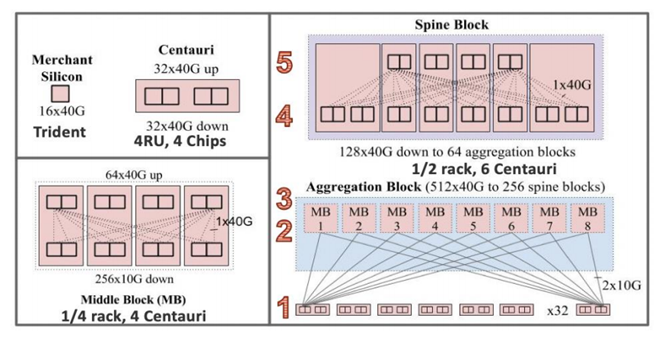
Google在2016年揭晓了基于Trident芯片 16x40GE 设计的 Jupiter 40G Fabric 数据中心架构。实际当年应该已经规模部署 32x100GE 架构(Google一般揭秘2-5年之前的前代技术)。Jupiter 架构设计中,采用四个Trident芯片来构建Centauri(半人马),四个Centauri组成一个Middle Block,6个Centauri 组成一个Spine Block。从芯片的角度其实是5层 9-Stage CLOS架构。
2.2 Fabric as a Switch, Switches as a Fabric
到了 2019 年,各个主流芯片公司纷纷推出 12.8Tbps 的新一代芯片。对比2014年推出的3.2T芯 片,容量提高了4倍。按照同样Backpack的思路,可以基于4+8个12.8T芯片构建 128x400GE 新型盒子。实际上由于400G的光模块在2019年技术远没有成熟,大规模400G Fabric部署不具备性价比。
Switch as a Fabric:单颗大容量芯片盒子可以替代之前的一个小容量芯片构建的交换矩阵Fabric。Facebook优化了Backpack,采用一颗单一12.8Tbps芯片来取代12颗 3.2T的Backpack。实际组大网能力提高远超四倍。如下图所示:
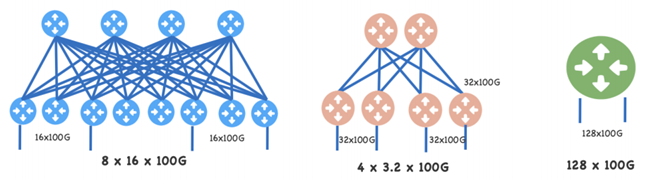
为了提供128x100GE接口能力,如果采用3.2T芯片,需要4(Spine)+8(Leaf)共12颗芯片的 架构,每个leaf 提供16x100GE接入Fabric Spine还有16x100GE用户接入。如果采用3.2T Pizzabox实现同样用户接口能力,总共需要12个3.2T的盒子(12RU)。
随着芯片容量提高,单端口100GE 的价格一般会下降。也就是12.8T盒子价格是小于四个3.2T 盒子,同时加上3.2T芯片之间互联的光模块,光纤,耗电,空间成本,12.8T单芯片盒子方案可以比之前3.2T盒子搭出来的Fabric节省5~6倍的TCO。
Fabric As a Switch: 业界通用采用多颗小型芯片构建一个超大型多槽位交换机/路由器系统。
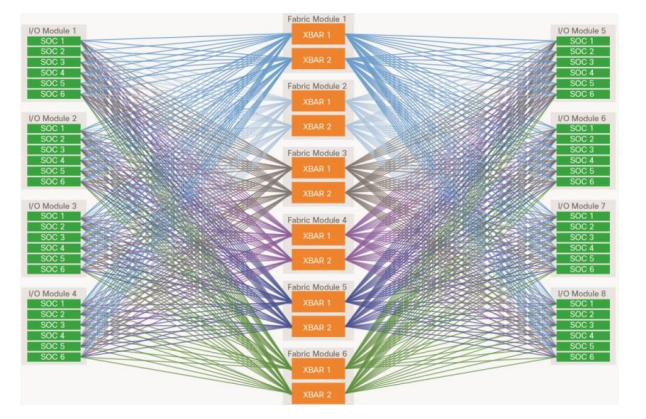
比如Cisco的 Nexus9K 产品架构如图(参见 Cisco ***),早期的多槽位交换机,每板卡上有6个ASIC,8个槽位48个芯片(Leaf)连接到 Cross BAR(Spine)。整个交换机是一个12+48的Leaf/Spine Fabric 系统。
业界在不同阶段/场景。随着芯片技术进步,新一代的芯片可以替代前代的一个 Fabric 矩阵(Switch as A Fabric)。如果追求单机更高端口数量,可以采用多颗芯片Leaf/Spine构建更大交换机(Fabric As a Switch)。技术发展总是螺旋上升,最近几年云公司更喜欢单芯片盒子设计。
2.3 MiniPack 和 F16 新架构 Fabric as Switch, Switch as Fabric
Facebook2019年推出新的盒子设计MiniPack,就是利用了新的12.8T 芯片,从原有 7RU设计,浓缩进 4RU 更小的单芯片盒子。同时单芯片盒子还带来了一些其他的好处。
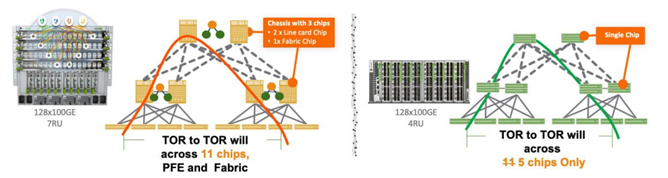
- 更低时延Latency,针对越来越多的AI/ML负载,服务器之间的跳数和时延越来越重要,采用单一芯片的Minipack在5-stage CLOS网络中,服务器到另一台服务器,仅仅需要跨越5个不同的芯片,这些芯片时延低至 400~600ns。同样的网络拓扑,如果采用BackPack则需要跨越11个芯片(每个盒子至少3颗芯片),芯片数量增加一倍以上。如果采用类似Jericho类信元交换盒子的设备每跳时延可达8000ns 以上,时延达到20倍左右。
- 简化,从12 颗3.2T简化成一个单芯片。整机耗电,空间占比(7RU-4RU)等大大减少减少。4RU是提供满载 12x100GE 接口的最优方案,如果采用 200GE/400GE接口,空间占比可以降为2RU(64x200GE)甚至 1RU(32x400GE)。控制平面从12个 BGP speaker 简化到1个BGP speaker。消除了芯片之间的负载均衡效率问题和 PFC/ECN反压流控等问题。
- 时延,流控,负载均衡等非常适合新一代交换机引入RoCEv2技术来支持AI算力。
利用新一代128x100GE 扇出的Minipack单一芯片盒子,Facebook构造了下一代F16 网络架构。Minipack相对于前代的Backpack只是芯片和架构的创新,还是相应的128 端口100GE 扇出。所以理论上是可以沿用F4的架构设计。
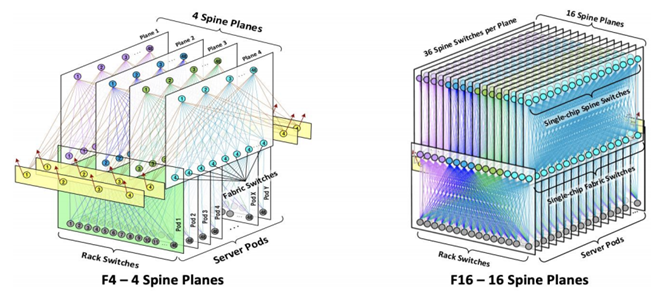
由于单机柜服务器流量增长,4x100GE 每机柜不能满足要求,新的设计RSW有更多的 16x100GE上行。因此架构上从4个Spine平面,增加到16个Spine平面,并且进行了一些微调。
虽然增加了FSW的数量,但是FSW层F4设计采用4平面x12芯片/盒子,总共48个芯片,增加到16个平面单芯片盒子,反而芯片数量减少了2/3,成本,功耗,空间都得到了优化。
- RSW(Rack Switch):保留每个POD 48台TOR 交换机汇聚到16台Fabric Switches 分属16个不同的平面;POD可以横向扩展Scale Out。最多128个POD。
- FSW(Fabric Switch):每个平面最多128台 FSW ,16台Fabric交换机分别上联到 16个平面的Spine Switches,Spine平面是完全隔离的。
- SSW(Spine Switch):36台 SSW 和最多128台FSW组成一个平面。汇聚所有的 POD流量。取消了Edge switch POD,直接通过SSW和其他DC机房的Fabric互联,或者去往Backbone和互联网的流量。
- 超大规模:每个SSW有128个端口,所以最多接128个FSW(POD),同时还有至少8/16个接口去HGRID作为Edge switch,所以一个数据中心平面可以支持大概 120个FSW。也就是120个POD。所以一F4数据中心可以最多支持:120x48=5760 RSW,也 就是大概不到6000个机柜 Switch,跟F4单数据中心支持的机柜数量一致。Facebook 还定义了8个平面的小型数据中心F8 Fabric版本。支持机柜数量不变,但是每机柜只提供8x100GE上行。FSW/SSW数量减半,链路,光模块,光纤数量也都相应减半。
2.4 CLOS 网络规划
Facebook Minipack 单芯片盒子构建Fabric设计,跟很多Tier1云公司思路一致,也影响到很多Tier2甚至中小型数据中心交换矩阵设计。Linkedin 2016年数据中心Fabric Project Altair也是类似的5级CLOS架构,采用3.2T(32x100GE)/1RU 盒子,每个 100GE breakout 出来2x50GE 接口,总共可以分出来64个50GE接口,来支持64个 POD 设计。可以支持32(TOR/POD) x64(POD)=2048个机柜设计。

Linkedin 的数据中心设计需要64端口扇出的盒子,由于当时他们只自研了3.2T的 Falco 开放交换平台,所以采用了一种不得已的Breakout分出50G Fabric设计。现在市场上有各种成熟的64 x 100GE /128x100GE的单芯片盒子。采用3/5-stage 数据中心100GE Fabric 设计,可以提供32~8000个机柜的标准设计。下面以128x100GE(4RU)单芯片盒子为例。

- POD规模:受限制于 Fabric SW(Spine),根据收敛比来定制,128 个端口:
- 无阻塞:64(上行SpineSW)/64(下行 RackSW),每个POD包含64个TOR
- 1:3 收敛比:32(上行SpineSW)/96(下行RackSW),每个POD包含 96个TOR
- POD数量:受限制于Spine SW(SuperSpine),128个端口,可以支持128个 POD
- Fabric规模:
- 无阻塞:128(POD)x 64(TOR/POD) = 8,192机柜(双上联 4K)
- 1:3 收敛比:128(POD)x 96(TOR/POD) = 12,288机柜(双上联 6K)
- 实际部署,要考虑 DC Border Leaf(出口)大概支持6K机柜规模(3K 双上联)
64x100GE(2RU)的Fabric设计类似,理论可以支持2K(无阻塞)/3K(1:3)双联减半,足够满足大部分中小互联网和大企业数据中心需求。128x4RU盒子每RU端口密度也 只是32x100GE。却可以替代2+4个64x100GE的2RU 盒子。在大规模部署时更经济,但是小规模<200~500 racks 时需要具体分析。
2.5 200G/400G Fabric
2019/2020年很多公司推出400G/200G接口的交换机设备,同时服务器网卡也纷纷支持单/双端口50G/100G,甚至开始支持单口200G接口。
很多大型互联网公司在考虑部署100G交换机Fabric之后,是采用200G还是400G Fabric?要回答这个问题,先看多大规模部署?离开规模谈部署都是耍流氓。首先看 Hyperscale云公司广泛采用的Fabric设计:
- 8端口上行的设计:TOR上提供8x200G上行,就可以支持单机柜每服务器40G-100G 的 并发流量。在 PCI-e 3.0(Intel)和 PCI-e4.0(AMD)网卡服务器上带宽足够了。除了存储和AI GPU,大部分TOR还不需要8x400G上行。8x200GE 是个不错的选择。
- 128端口扇出:Spine交换机128x200G=25.6T芯片(采用512 x 56G PAM4 或者 256x112G PAM4)在2020 /21 年成熟。对于51.2T=128x400G 芯片必须要等到 2022/2023 年,512 x 112G PAM4 Serdes 才能成熟。如果要采用56G PAM5的话,单颗芯片Die Size无法放进去1024 x 56 PAM4 Serdes。也就是说200G端口 Spine switch会有 2-3 年以上的生命周期。
- 400G光模块性价比:400G QSFP-DD采用8x56G PAM4技术。价格还是居高不下。以FS.com 网上2020年3月价格来看2KM 100G CWDM4 只要$250左右,而 2KM 400G XDR4/FR4需要$7K-8K。是100G同样距离的32倍左右,远远超过了期望的4倍100GE价格。为了接入51.2T Spine 盒子,需要等4x112G PAM4 技术的 400G光模块,价格短期内只会更高。2020 年很多厂商提供200G光模块,价格可以做到同样距离100G的两倍左 右,200G Fabric交换矩阵的性价比更好。
综上所述,美国很多云公司纷纷采纳200G Fabric设计作为100G的下一代。他们的决定会推动200GE生态,包括56G PAM4网卡(最新 Mellanox ConnectX6),200G光模块和交换机生态。
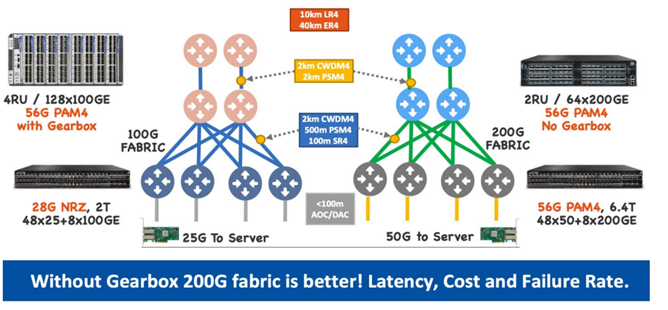
对于私有云混合云和中小型超算数据中心,Spine/Super Spine可以采用12.8T芯片 64x200GE/32x400GE端口扇出,就可以构建2000个机柜的200G/400G Fabric。不需要等25.6T芯片推出市场。
云公司Fabric构建需要不同距离的光模块,Google/AWS/Azure 每家在同样网络位置,采用的光模块技术不尽相同。100G/200G fabric 光模块都成熟,升级到200G价格增加大概1倍左右:
- Spine/SuperSpine 之间: 2km CWDM4 或者 2km PSM4
- Spine/Leaf 之间:2km CWDM4,500m PSM4, 100m SR4
- Leaf/Server 之间: < 100m AOC/DAC
现在转型 200GE fabric,还有以下优势:
- 56G PAM4 芯片成熟,网卡/光模块/交换机 ASI三种芯片都全面支持56G PAM4,从服务器到Fabric设备不需要添加额外的Gearbox,时延降低,成本降低,设备出错概率降低。
- a. Minipack 以太网 ASIC 芯片是 56G PAM4,但是要出 100G NRZ 接口,所以整机添 加了32 个Gearbox 做 PAM4 到 NRZ 的转换。成本更高,时延增加(从 400ns到800ns以上),Gearbox硬件出错需要更换整机或者板卡。
- 空间优势,基于12.8T芯片的2RU Spine/SuperSpine设备,比4RU的 128x100GE 盒子( Minipack )占机架空间更小。
- 成本优势,同样Fabric容量,光模块/光纤 Fiber数量少一半。享受云公司推动 200GE端到端成本降低红利。最近我们推荐给客户的几个200G Fabric,总价格基本上和100G fabric持平,甚至有20%~40%的成本减少。
不可否认,32x400GE接**换机已经推出市场一年。400G AOC 和 Breakout 光纤解决方案成本降低很快,一些客户构建了短距离小型的 Fabric,比如4(SuperSpine)+8(Spine)个1RU 32 x 400GE在一个机柜里,通过breakout 4x100GE 接到 TOR switch 上的方案(某 Telco Cloud 选择)。
但由于400G光模块价格仍然很高(500m~2KM同样距离,20~30倍价格差),同时由于芯片技术限制(51.2T 只能采用100G PAM4新型光模块远不成熟),我们预估400G Fabric在云公司2023+之后才能大规模部署,也就是说200G Fabric会有2-3 年生命周期。2020 年私有云混合云和中小型超算,从100G Fabric 升级到 200G 也可以享受云公司带来的技术红利。
总结的很好
收起