Windows下训练PyTorch版YOLOv5并用OpenVINO™ 部署 | 开发者实战
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
概述
图像分类(Image Classification),是根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。而在分类任务中比较经典的网络结构有VGGNet,ResNet,以及后面出现的MobileNet与ShuffleNet等,而在本文中主要使用到的是ResNet。
本文使用了YOLOv5模型,使用OpenVINO™ 工具套件为分类模型优化部署的框架,介绍了YOLOv5和OpenVINO™ 工具套件的安装和使用,以及YOLOv5模型训练的全部流程。并详细介绍了OpenVINO™ Inference Engine 应用程序典型开发流程,以及怎样使用Python编程语言开发AI推理应用程序。
1 安装Anaconda
1.1 Anaconda概述
Anaconda是一个用于科学计算的发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
1.2 下载并安装Anaconda
下载并安装Anaconda,具体步骤如下。
第一步,通过网址
https://www.anaconda.com/products/individual
进入Anaconda官网,直接点击Download进行下载,如图1-1所示。

第二步,找到下载文件Anaconda3-2021.05-Windows-x86_64.exe并双击安装到图1-2中的界面,进入用户选项界面默认选择Just Me,再点击Next> 按钮。
第三步,设置安装路径,尽量保持默认路径,然后点击Next>按钮安装,如图1-3所示。
第四步,进入高级安装选项设置,一定要勾选Add Anaconda3 to my PATH environment variable,将Anaconda3的路径添加到环境变量中,然后点击Install 按钮,Anaconda安装完成,如图1-4所示。
1.3 测试Anaconda安装
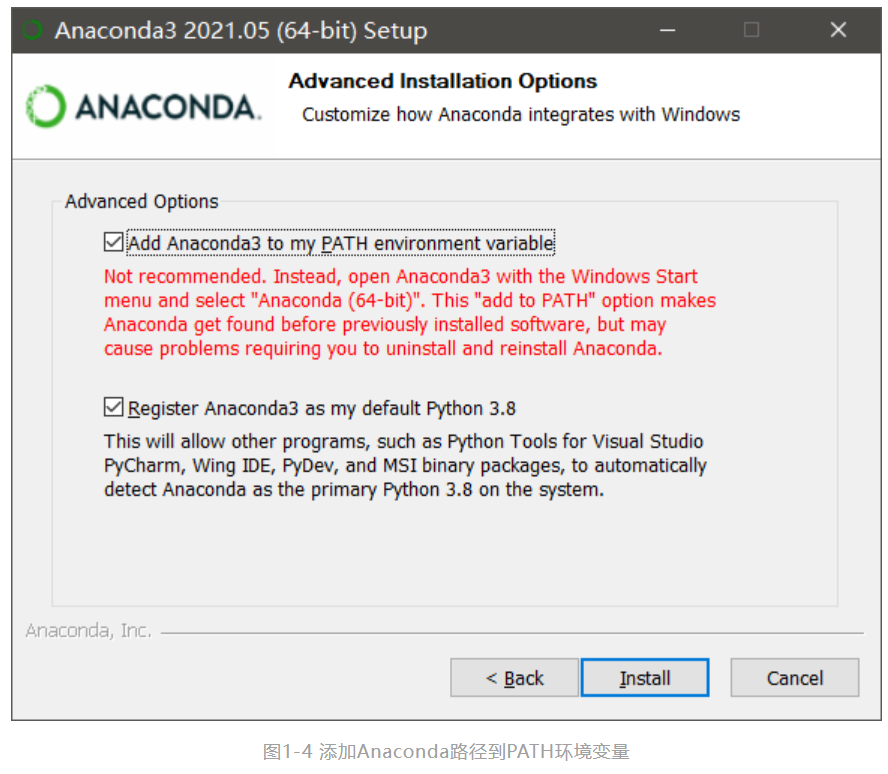
全部安装完毕后,在Windows“开始”菜单中选择 Anaconda Navigator ,进入主界后点击Environments 选项卡,如下图1-5所示可以看到当前的Anaconda默认虚拟环境是base(root),单击base(root)右侧的绿色箭头,在弹出的菜单中选择Open with Python。
在弹出Windows命令行窗口中,输入代码<print< font="">(“hello python”)>,得到如下图1-6的结果证明Anaconda和Python全部安装成功。

2 迅速安装YOLOv5
2.1 安装CUDA与cuDNN库
如果您的计算机有NVIDIA® GPU,请确保满足以下条件并且安装GPU版PaddlePaddl
■ CUDA 工具包10.1/10.2 配合 cuDNN 7 (cuDNN版本>=7.6.5) |
■ CUDA 工具包11.0配合cuDNN v8.0.4 |
■ CUDA 工具包11.2配合cuDNN v8.1.1 |
■ GPU运算能力超过3.0的硬件设备 |
安装CUDA和cuDNN库的步骤如下:
第一步,到以下网址下载11.0vCUDA,如图2-1所示。
https://developer.nvidia.com/cuda-downloads?
第二步,安装完成后双击exe文件开始安装,如图2-2所示。
第三步,之后只需要一路默认安装即可完成,如图2-3所示。

第四步,进入https://developer.nvidia.com/rdp/cudnn-download
安装cuDNN v8.0.4,这里需要登录,如果没有账号的话就去注册一个,如图2-4所示。

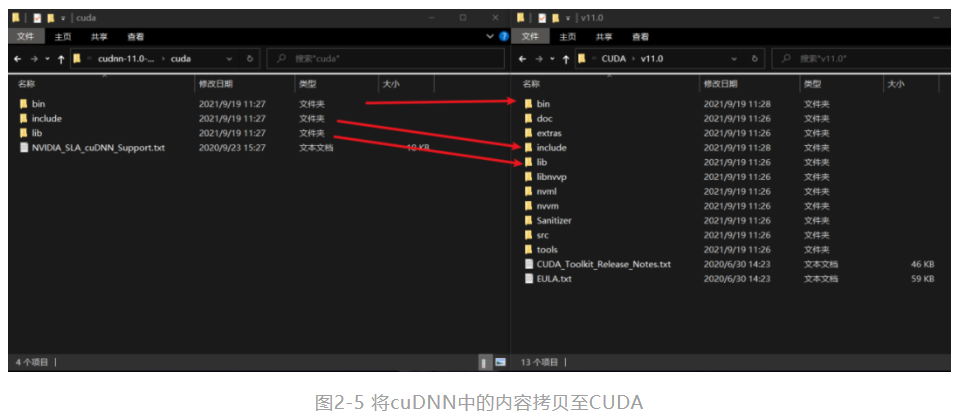
第五步,下载下来的文件是一个压缩包,解压后有三个文件夹bin、include和lib,依次将三个文件夹中的内容拷贝到CUDA的安装目录(默认情况下是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0)下的bin、include和lib下,这个要一一对应,如图2-5所示。
2.2 安装YOLOv5
2.1.1 安装git
Git是一个开源的分布式版本控制系统,可以有效、高速的处理从很小到非常大的项目版本管理。具体安装步骤如下:
第一步,从官网地址:https://git-scm.com/downloads
下载最新版本的Git,如图2-9所示。
第二步,完成安装后会得到exe文件,双击打开,如图2-10所示。
第三步,之后只需要一路默认安装即可完成,如图2-11所示。
2.2.2 安装YOLOv5
第一步,在创建的虚拟环境上从gitee下载,下载命令如下:git clone https://gitee.com/jiujuei**mp/YOLOv5
第二步,安装Python依赖库。Python依赖库在requirements.txt中给出,可通过如下命令安装:pip install --upgrade -r requirements.txt,如图2-13所示。
3 训练模型
本章节基于coco数据集,使用YOLOv5进行图像检测模型的训练与推理。
3.1 数据集准备
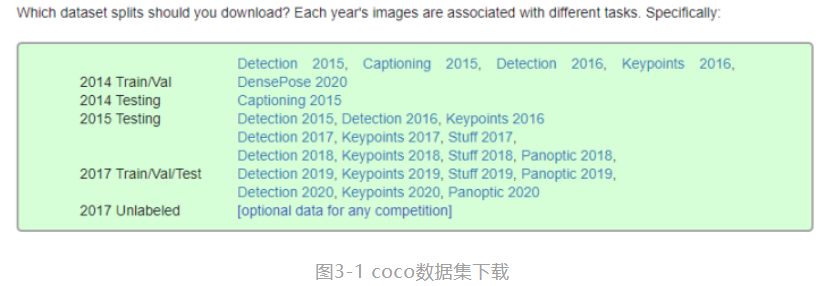
第一步,从网址http://cocodataset.org 进入官网下载coco数据集。
MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
当在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
3.2 使用预训练模型进行训练
3.2.1 训练前设置
第一步,设置PYTHONPATH环境变量。只需设置PYTHONPATH,从而可以从正在用的目录(也就是正在交互模式下使用的当前目录,或者包含顶层文件的目录)以外的其他目录进行导入。具体的设置方法如图3-2所示。
第二步,设置gpu**。设置gpu**是为了指定使用哪张显卡训练,win下目前仅支持一张显卡训练,**设为0
3.2.2 调整网络yaml文件
由于在Windows系统下不支持多进程读取数据,因此训练前需要修改yaml文件。Yaml文件在YOLOv5/data/ 文件夹下,如图3-2所示。
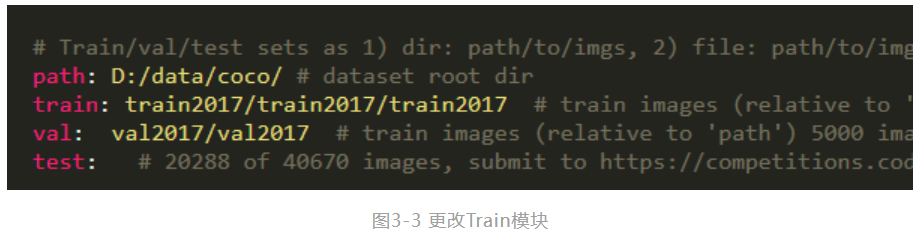
第一步,需要将Train模块中的path,train、val修改为coco数据集对应所在的路径,如图3-4所示。
3.2.3 转换标注文件格式
由于coco数据集的标注文件是按照coco的格式以json文件储存,而YOLOv5使用的是YOLO格式的txt文件,因此需要运行一下脚本先把json文件中的标注信息转换出来:
"""
COCO 格式的数据集转化为 YOLO 格式的数据集
--json_path 输入的json文件路径
--save_path 保存的文件夹名字,默认为当前目录下的labels。
"""
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--json_path', default='./instances_val2017.json',type=str, help="input: coco format(json)")
parser.add_argument('--save_path', default='./labels', type=str, help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
o***akedirs(ana_txt_save_path)
id_map = {} # coco数据集的id不连续!重新映射一下再输出!
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(f"{category['name']}\n")
id_map[category['id']] = i
# print(id_map)
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
f_txt.close() 3.2.3 模型训练
在YOLOv5中提供了YOLOv5s,YOLOv5m YOLOv5l,YOLOv5x等多种结构的模型,不同模型的精度和权值大小不一,用户可以方便地根据自己的需求使用相应的模型以及预训练权值。
本文以YOLOv5s为例,进行coco数据集上的训练
在Anaconda中输入训练脚本
python train.py --img 640 --batch 8 --epochs 50 --data coco.yaml --weights YOLOv5s.pt
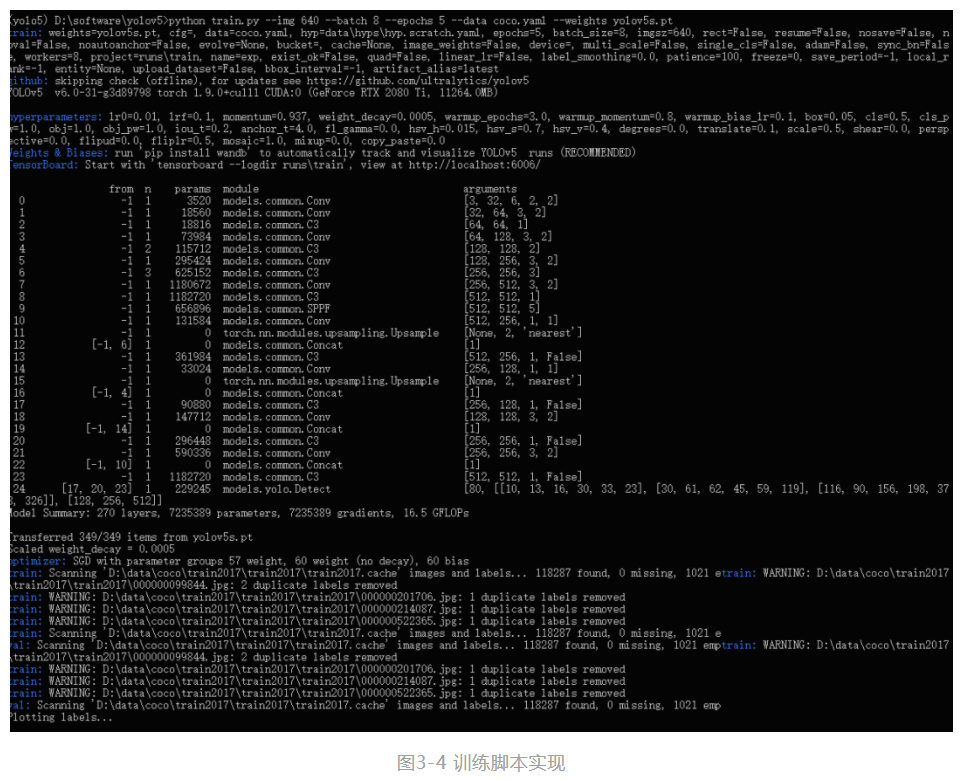
最后,经过50epochs的训练后,得到训练集上结果如下:
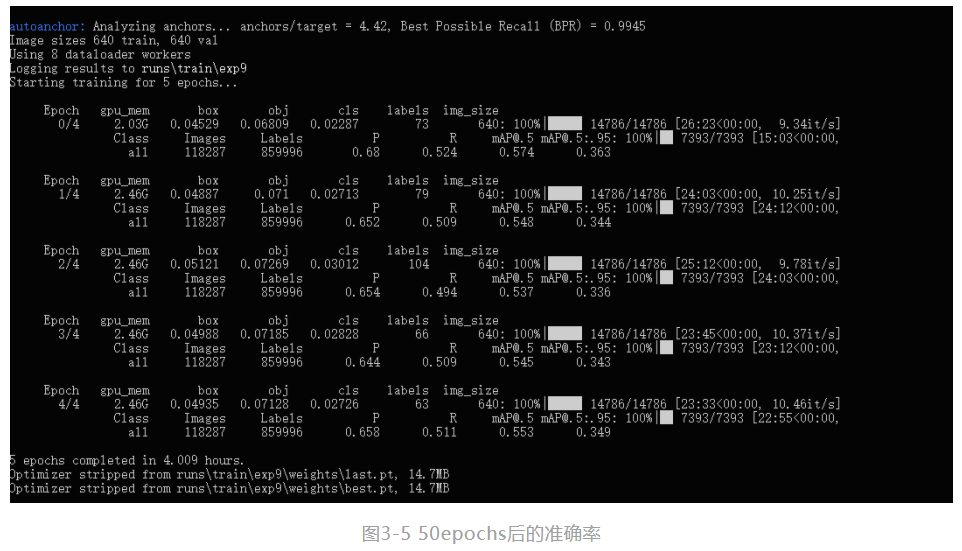
在runs文件夹中有训练后的权值文件以及训练测试的结果:
对YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x分别进行训练,在单张GTX2080ti的条件下,训练50epoches,训练时间分别为:13h、23h、39h、78h
python train.py --data coco.yaml --cfg YOLOv5s.yaml --weight********atch-size 16
YOLOv5m.yaml 8
YOLOv5l.yaml 4
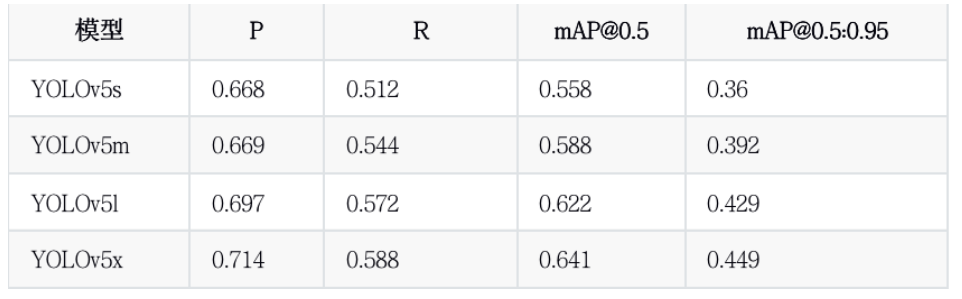
YOLOv5x.yaml 2 训练结果如下所示:
3.2.4 模型推理
使用YOLOv5中的detect.py文件即可完成推理任务,使用命令如下:
python detect.py --source 0 # 本机默认摄像头
file.jpg # 图片
file.mp4 # 视频
path/ # 文件夹下所有媒体
path/*.jpg # 文件夹下某类型媒体
rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtsp视频流
http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # http视频流 得到的推理结果将会在runs/detect文件夹中
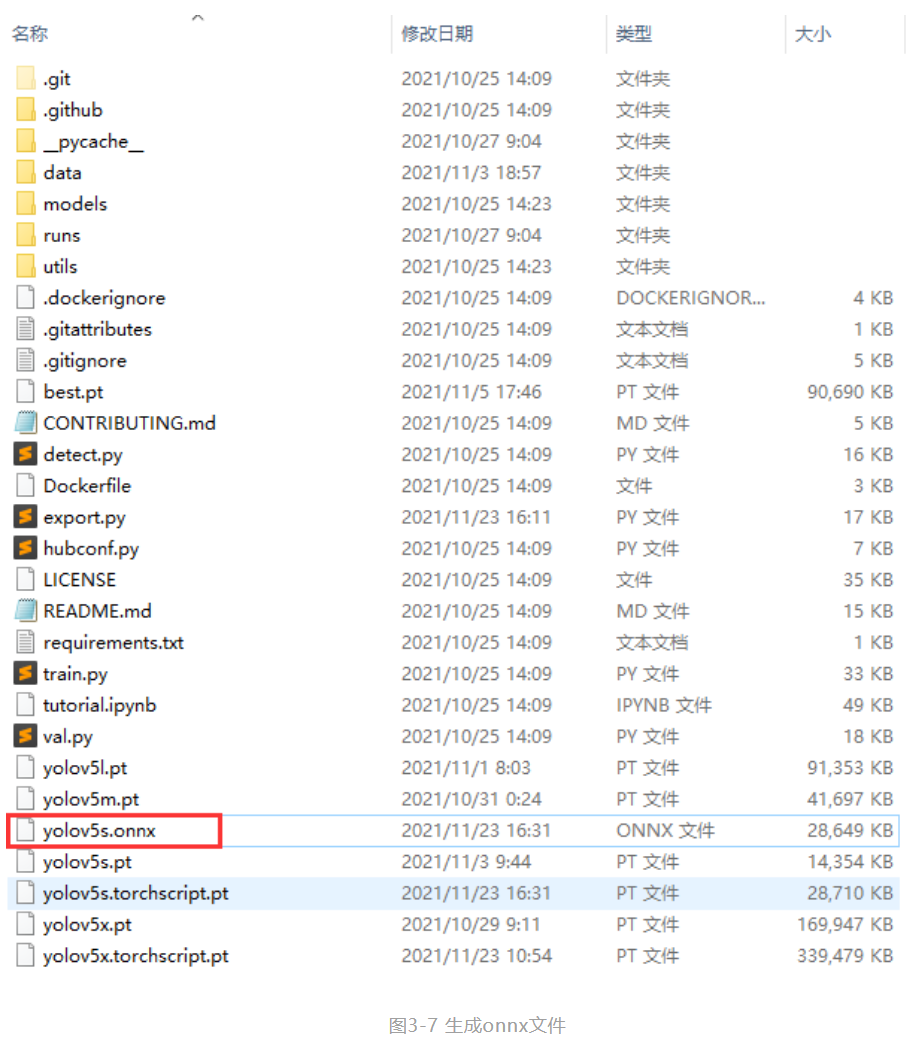
3.2.5 转换为onnx格式
为了能在OpenVINO™ 工具套件中进一步部署,需要把生成的pt文件转化为onnx文件
使用YOLOv5文件夹中的export.py文件,采用如下命令即可:
python export.py --weights YOLOv5s.pt --batch 1 --img 640
随后将会在权值文件夹下生成相应的onnx文件
4 安装OpenVINO™ 工具套件部署
4.1 OpenVINO™ 工具套件简介
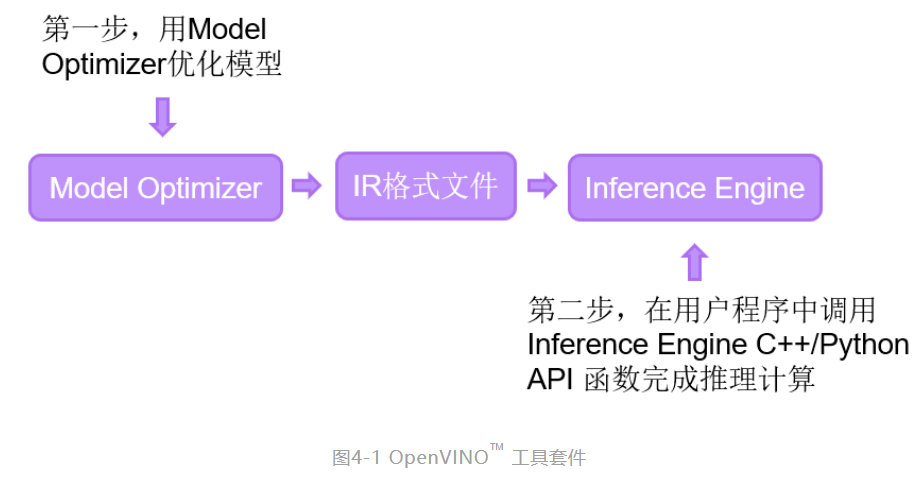
OpenVINO™ 工具套件全称是Open Visual Inference & Neural Network Optimization,是英特尔® 于2018年发布的开源工具包,专注于优化神经网络推理。OpenVINO™ 工具套件主要包括Model Optimizer(模型优化器)和Inference Engine(推理引擎)两个部分。Model Optimizer是用于优化神经网络模型的工具,Inference Engine是用于加速推理计算的软件包。如图4-1所示,即为OpenVINO™ 工具套件的主要组成部分。
4.2 OpenVINO™ 工具套件安装
4.2.1 OpenVINO™ 工具套件下载和安装
下载并安装OpenVINO™ 工具套件的具体步骤如下。
第一步,通过
https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html
进入OpenVINO™ 工具套件官网下载页面,选择合适的版本,本文选择2021.4版本的OpenVINO™ 工具套件,按照如图5-2所示选择,再点击Download按钮即可下载OpenVINO™ 工具套件2021.4版本的安装程序。
第二步,找到OpenVINO™ 工具套件的安装文件w_openvino_toolkit_p_2021.4.689.exe,双击下载安装,安装步骤全部默认安装即可,如图4-3所示。
第三步,安装过程中会有CMake和Mircrosoft Visual Studio依赖软件安装的提示,下面我们继续安装CMake和Mircrosoft Visual Studio软件。
4.2.2 CMake下载和安装
CMake作为一个跨平台的C/C++程序编译开源配置工具,在OpenVINO™ 工具套件的应用中,CMake用来管理OpenVINO™ 工具套件中的演示程序(Demos)和范例程序(Samples)。
下载并安装Cmake的步骤如下所示。
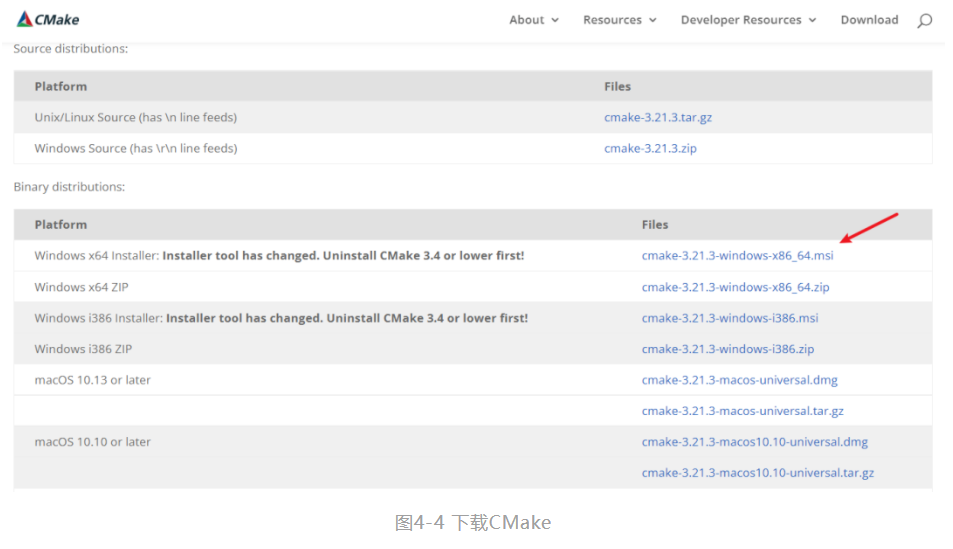
第一步,通过 https://cmake.org/download/ 进入CMake官网下载界面,下载安装文件,选择的CMake版本大于等于3.4版本即可,本文的版本选择为cmake-3.21.3-windows-x86_64.msi,如图4-4所示
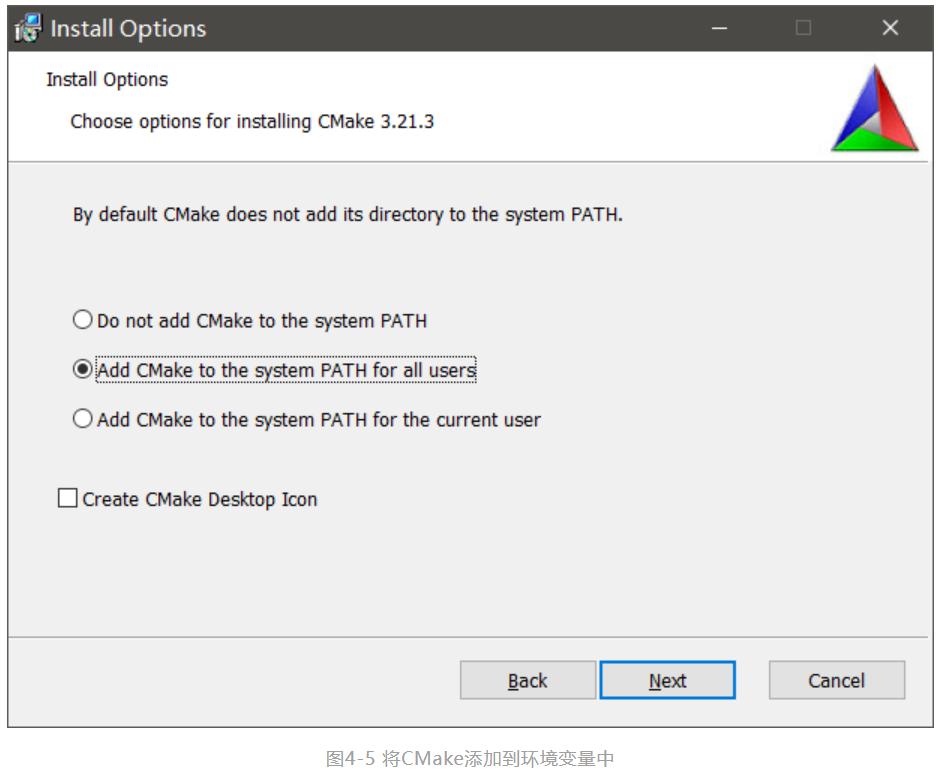
第二步,双击安装文件,默认选项完成安装,在Install Options页面选择Add Cmake to the system PATH for all users将CMake添加到系统变量PATH中。如图4-5所示。
4.2.3 Mircrosoft Visual Studio下载和安装
OpenVINO™ 工具套件支持Mircrosoft Visual Studio 2015、2017和2019。由于Mircrosoft Visual Studio 2017是目前Windows操作系统下应用最广泛的C++ IDE,本文选择使用Mircrosoft Visual Studio 2017版本。
Mircrosoft Visual Studio 2017安装步骤如下:
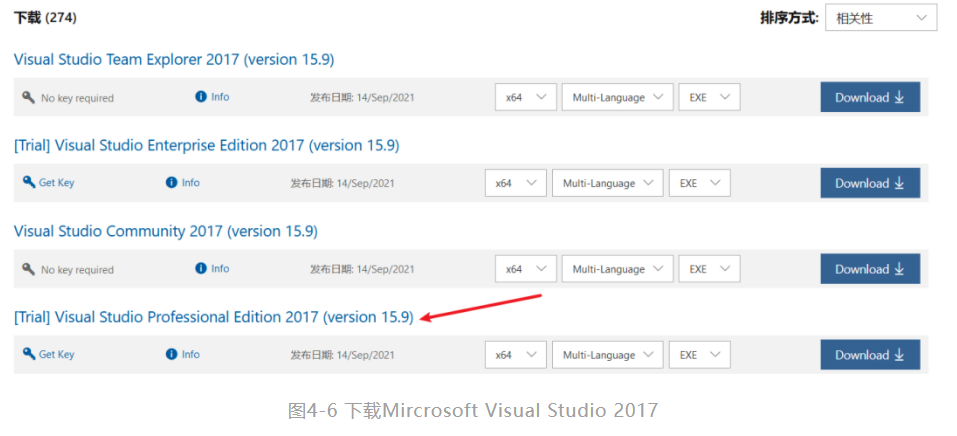
第一步,通过网址https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/ 进入Mircrosoft Visual Studio旧版本下载地址,单击2017,在展开的下载选项中点击“下载”按钮进入Mircrosoft Visual Studio 2017下载页面,在左侧选择Visual Studio 2017(version 15.9),在右侧的选择页面中选择Visual Studio Community 2017(version 15.9),单击Download下载,如图4-6所示。
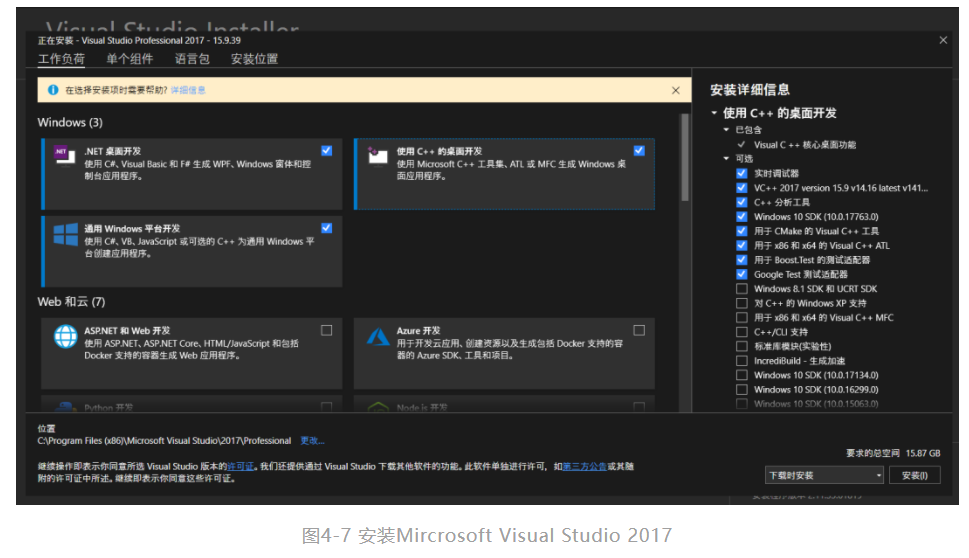
第二步,找到安装文件双击打开,在安装配置中选择“.NET桌面开发”、“使用C++的桌面开发”、“通用Windows平台开发”三个选项后,再选择右下角的“安装”按钮开始安装,如图4-7所示。
4.2.4 OpenVINO™ 工具套件验证安装
第一步,打开命令行输入刚才openvino的安装路径,这里以笔者的为例,输入cdC:\Program Files (x86)\Intel\openvino_2021.4.689\bin。再输入:setupvars设置一个临时的环境变量,如图4-8所示。
第二步,输入cd C:\Program Files(x86)\Intel\ openvino_2021.4.689\deployment_tools
\model_optimizer\install_prerequisites,之后再输入install_prerequisites以配置Caffe *,TensorFlow *,MXNet *,Kaldi *和ONNX *的模型优化器,可以将它们训练的模型转化成IR格式供推理引擎使用,如图4-9所示。
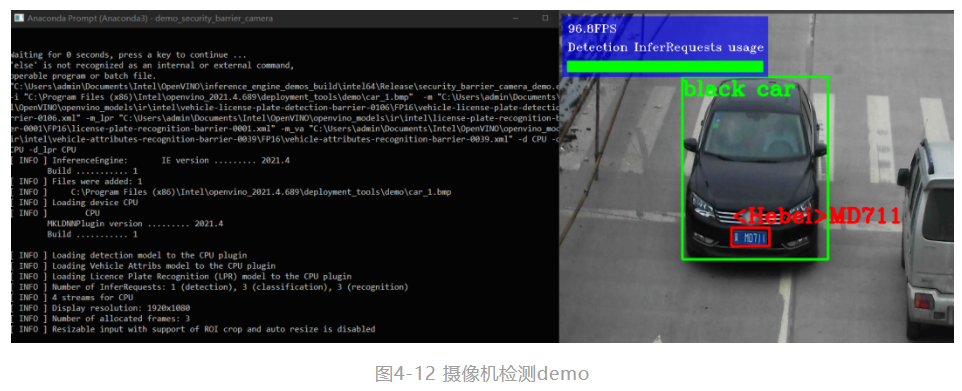
第三步,输入 cd C:\Program Files(x86)\Intel\openvino_2021.4.689\deployment_tools\demo,之后在输入demo_squeezenet_download_convert_run.bat来实现自动下载一个训练好的SqueezeNet model,并且使用Model Optimizer转化成IR格式的数据。(这是官方的方法,但实际上会出问题),如图4-10所示。
笔者在执行bat文件时,并不能正常的下载模型,因此需要手动使用git来下载squeezeNet模型。可以在命令行输入git clone https://github.com/forresti/SqueezeNet,可以下载到如图4-11的文件内容。我们需要提取SqueezeNet_v1.1.caffemodel和deploy.prototxt到测试输出目录下的模型子目录:
C:\Users\admin\Documents\Intel\OpenVINO\openvino_models\models\public\squeezenet1.1,并重命名为squeezenet1.1.caffemodel和squeezenet1.1.prototxt
第四步,在命令行输入demo_security_barrier_camera,得到如图4-12所示的内容,至此OpenVINO™ 工具套件安装完成。
5 使用OpenVINO™ 工具套件部署YOLOv5模型
5.1 使用Model_Optimizer优化模型
5.1.1 转化ONNX模型到IR格式
model_optimizer可以支持ONNX模型的转换,具体步骤如下:
第一步,输入命令来到model_optimizer目录下
cd C:\Program Files (x86)\Intel\openvino_2021.4.689\deployment_tools\model_optimizer
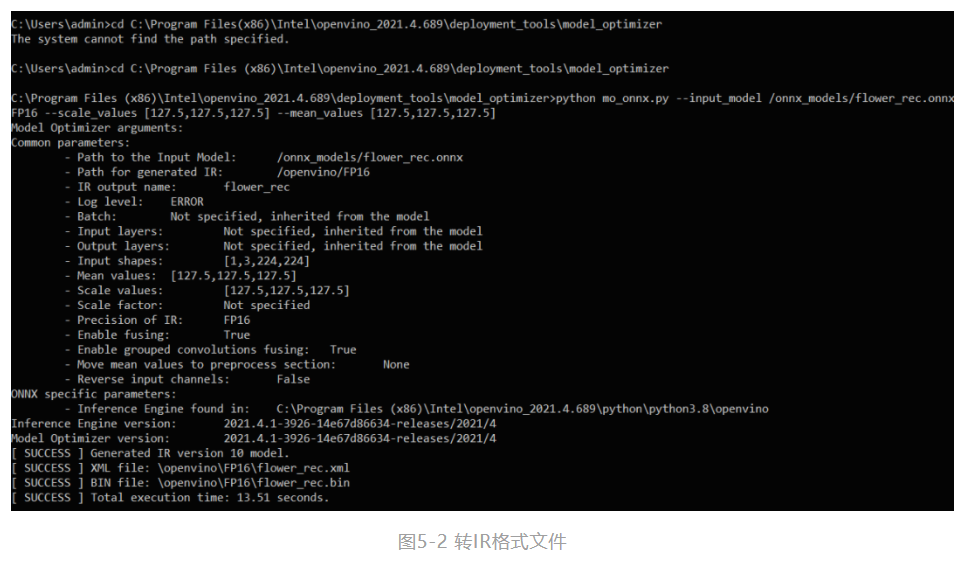
第二步,输入如下命令实现转换
python mo_onnx.py --input_model /onnx_models/flower_rec.onnx --output_dir /openvino/FP16 --input_shape [1,3,224,224] --data_type FP16 --scale_values [127.5,127.5,127.5] --mean_values [127.5,127.5,127.5]
--data_type来指定模型的精度,--input_shape来指定模型接受图像的形状。最关键的两点我要拿出来讲,分别是--mean_value(MV)和--scale_values(SV)。在转到IR模型的时候如果指定了这2个参数,那么在之后用模型做推理的时候就可以不用做Normalization。当转换成功时,将会出现如图5-2中的SUCCESS提示。
5.2 Inference Engine 应用程序典型开发流程
Inference Engine典型的开发流程一共有八步,如图5-3所示:
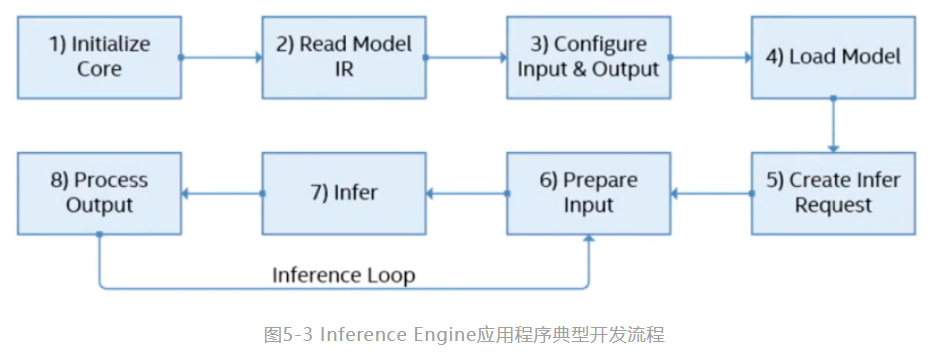
本次的案例开发将会基于Python(环境配置以及使用难度都对于入门新手比较友好),故使用Python对应的API来简单介绍以上的流程。
■ 初始化IECore实例:使用ie=IECore()来初始化Core对象,可用于管理可用设备和读取网络对象。 |
■读入一个IR模型:net = ie.read_network(model=model_xml, weight***odel_bin),将IR模型的路径赋给model_xml与model_bin便可以读取。 |
■ 配置输入和输出:使用input_blob = next(iter(net.inputs)),out_blob = next(iter(net.outputs))定义输入和输出。 |
■将网络加载到设备:exec_net = ie.load_network(network=net, device_name="CPU")将模型加载到设备,载入的硬件由device_name参数决定。 |
■ 创建推理请求:模型载入AI计算硬件后会得到一个infer对象,用于执行AI推理计算。 |
■输入数据:使用inputs={input_blob:[image]} 获取由推断请求分配的Blob,并将图像和数据提供给blob |
■执行推理:使用exec_net.infer(inputs={input_blob:[image]})进行异步请求推理。 |
■ 输出结果:使用res = res[out_blob] 获得推理计算结果。 |
5.3 编写OpenVINO™ AI推理计算Python范例
本节将基于5.1节生成的IR文件flower_rec.xml和flower_rec.bin,从零开始,实现完整的OpenVINO™ AI 推理计算python程序。
5.3.1 OpenVINO™ 工具套件中python和环境变量的设置
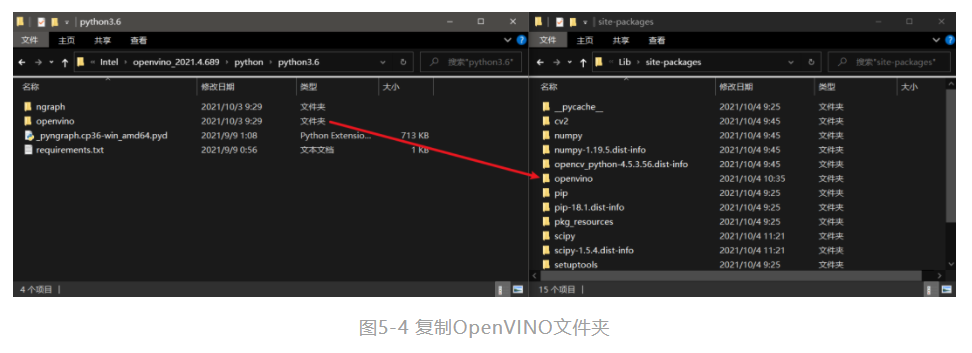
第一步,将路径
C:\Program Files (x86)\Intel\openvino_2021.4.689\python\python3.6下的openvino文件**一份到python安装路径E:\python3.6\Lib\site-packages(python的安装路径可能有所不同,关键是找到Lib\site-packages下即可)下,如图5-4所示。
第二步,使用pip install -r "C:\Program Files(x86)\Intel\openvino_2021.4.689\
python\python3.6\requirements.txt"将所需要的库进行安装。
第三步,将图5-5中红框标识的路径配置进系统环境变量当中。
第四步,在PyCharm中输入如图5-6所示的代码,若能正常输出设备名称则为配置成功。

5.3.2 开发AI推理计算Python应用程序
在成功配置环境变量和项目属性后,使用Python编程语言开发OpenVINO™ 工具套件推理应用程序。
第一步,引入相应库函数,配置推理计算设备,IR文件路径,媒体文件路径,如代码清单6-1所示:
#Step1
from openvino.inference_engine import IECore
import numpy as np
import cv2 as cv
model_xml = "models/YOLOv5s.xml"
model_bin = "models/YOLOv5***in"
src = cv.imread(r"images\image_06626_2.jpg") 其中,各个库的用途如下:
■import IECore定义和实现Inference Engine的类、方法以及函数。 |
■ import cv2 OpenCV库,包含了OpenCV的各个模块。 |
■ import numpy 用于对图像矩阵的处理。 |
第二步,初始化Core对象,管理可用设备和读取网络对象,如代码清单6-2所示
#Step2 初始化Core对象
ie = IECore()
for device in ie.available_devices:
print(device) 第三步,使用读取IR模型(支持.xml格式),将IR模型读入ie.read_network
方法中去。如代码清单6-3所示:
#Step3 读取IR模型
net = ie.read_network(model=model_xml,weight***odel_bin) 第四步,配置模型输入和输出,将模型载入内存后,使用net.outputs和net.inputs参数保存输入和输出,如代码清单6-4所示:
#Step4 配置模型输入和输出
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
n,c,h,w = net.inputs[input_blob].shape 第五步,使用ie.load_network()将模型加载到设备,载入的硬件由LoadNetwork()方法的DEVICE参数决定。如代码清单6-5所示:
#Step5 将模型加载到设备
exec_net = ie.load_network(network=net, device_name="CPU") 第六步,准备输入数据,并按模型要求对图像矩阵进行转置处理,如代码清单6-6所示
#Step6 准备输入数据
image = cv.resize(src,(w,h))
image = image.transpose(2,0,1) 第七步,执行推理计算,使用此前加载到设备上的模型exec_net的infer()方法进行推理,如代码清单6-7所示:
#Step7 执行推理计算
res = exec_net.infer(inputs={input_blob:[image]}) 第八步,处理推理计算结果,使用numpy的np.max()和np.argmax()方法对输出结果进行筛选,获得对应输入图像的推理得分以及标签索引,之后再利用Opencv的putText()与imshow()方法对结果进行显示,如代码清单6-8所示:
#Step8 处理推理计算结果
res = res[out_blob]
print(res.shape)
print(np.max(res,1))
label_index = str(np.argmax(res, 1)[0]) #使用0将list转成数值类型
print(label_index)
label_index = 'classes_index: '+label_index
scores = ' scores: ' + str(np.max(res,1)[0])[:5]
cv.putText(src, label_index, (20,50), cv.FONT_HERSHEY_SIMPLEX, 1.0, (255,255,255), 2, 12)
cv.putText(src, scores, (5,85), cv.FONT_HERSHEY_SIMPLEX, 1.0, (255,255,255), 2, 12)
cv.imshow("flowers recognition",src)
cv.waitKey(0) 第九步,执行程序detection.py,若执行无误将会出现如图5-7所示的结果。

5.4 基于benchmark的性能测试
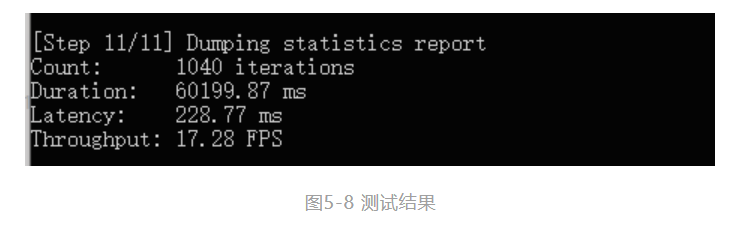
使用OpenVINO™ 工具套件中的benchmarkapp.exe对转化的IR模型进行测试:
命令如下:
benchmark_app.exe -m YOLOv5s.xml -i football.mp4 -d CPU
结果如下所示:
6 总结
本文基于详细介绍了YOLOv5框架和预训练模型,并使用Python编程语言训练coco数据集的完整流程,在模型部署模块中,详细介绍了OpenVINO™ 工具套件及其两个重要组件:Model Optimizer和Inference Engine的安装和使用,将训练完毕的YOLOv5s模型转换为IR格式文件后,使用Python编程语言进行AI应用程序的开发方法。在使用Inference Engine进行模型推理部署是,OpenVINO™ 工具套件提供了八个统一的API接口,流程化的开发方式极大降低了AI应用程序开发的难度,对于不同模型的不同输入输出节点,只需少量改动应用程序,便可快速独立开发属于自己的AI应用程序。
* 本文内容及配图均为“英特尔物联网”的原创内容。该公众号的运营主体拥有上述内容的著作权或相应许可。除在微信朋友圈分享之外,如未经该运营主体书面同意,请勿转载、转帖或以其他任何方式**、发表或发布上述内容。如需转载上述内容或其中任何部分,请留言联系。