Windows环境下使用OpenVINO™ 部署飞桨BiSeNetV2模型 | 开发者实战
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
概述
语义分割(Semantic Segmentation) 是计算机视觉对现实世界理解的基础,大到自动驾驶,小到个人应用只要细心观察都可以发现语义分割的应用场所无处不在,其实语义分割相当于是图像分割和对分割区域的理解。
本文使用了飞桨提供的PaddleSeg图像分类套件训练分类模型,使用OpenVINO™ 工具套件为分类模型优化部署的框架,介绍了PaddleSeg套件和OpenVINO™ 工具套件的安装和使用,以及BisNetV2分割模型训练的全部流程。并详细介绍了OpenVINO™ Inference Engine 应用程序典型开发流程,以及怎样使用Python编程语言开发AI推理应用程序。
01 安装Anaconda
1.1 Anaconda概述
Anaconda是一个用于科学计算的发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
1.2 下载并安装Anaconda
下载并安装Anaconda,具体步骤如下。
第一步,通过网址https://www.anaconda.com/products/individual进入Anaconda官网,直接点击Download进行下载,如图1-1所示。

第二步,找到下载文件Anaconda3-2021.05-Windows-x86_64.exe并双击安装到图1-2中的界面,进入用户选项界面默认选择Just Me,再点击Next> 按钮。
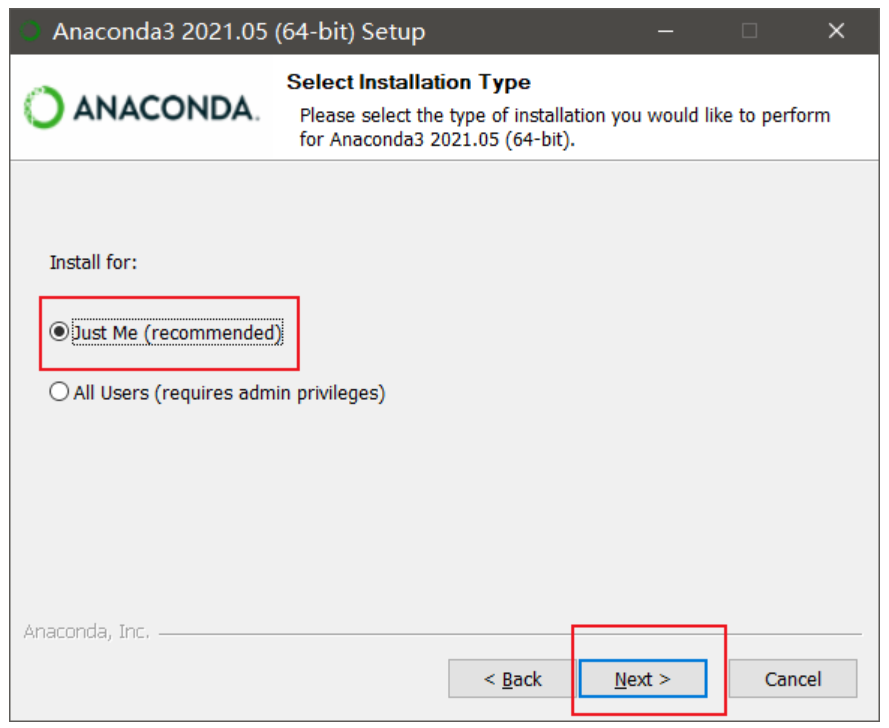
第三步,设置安装路径,尽量保持默认路径,然后点击Next>按钮安装,如图1-3所示。
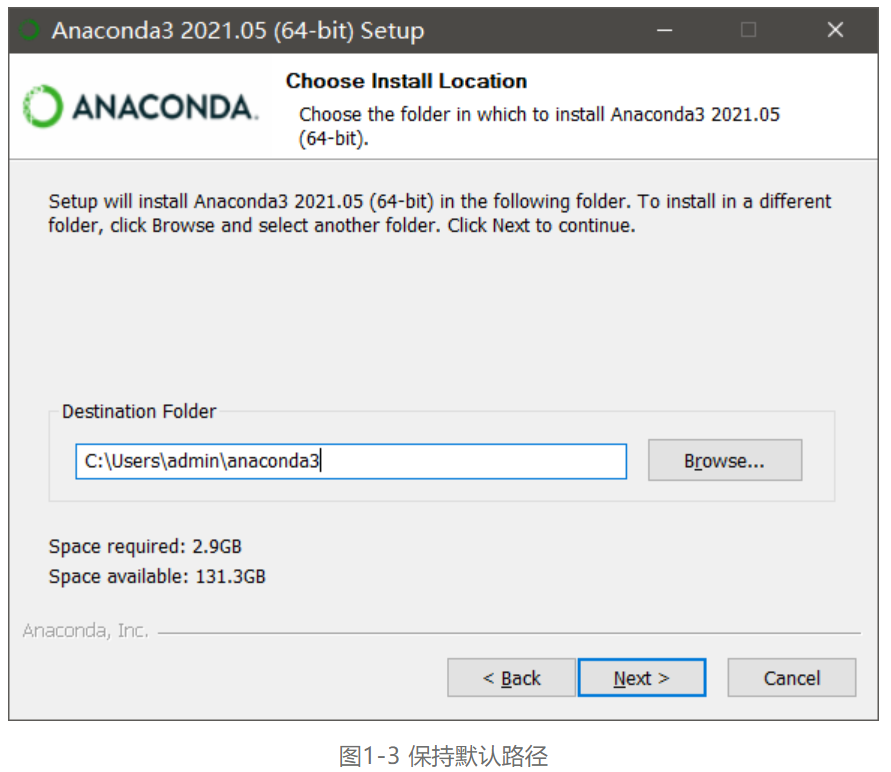
第四步,进入高级安装选项设置,一定要勾选Add Anaconda3 to my PATH environment variable,将Anaconda3的路径添加到环境变量中,然后点击Install 按钮,Anaconda安装完成,如图1-4所示。
1.3 测试Anaconda安装
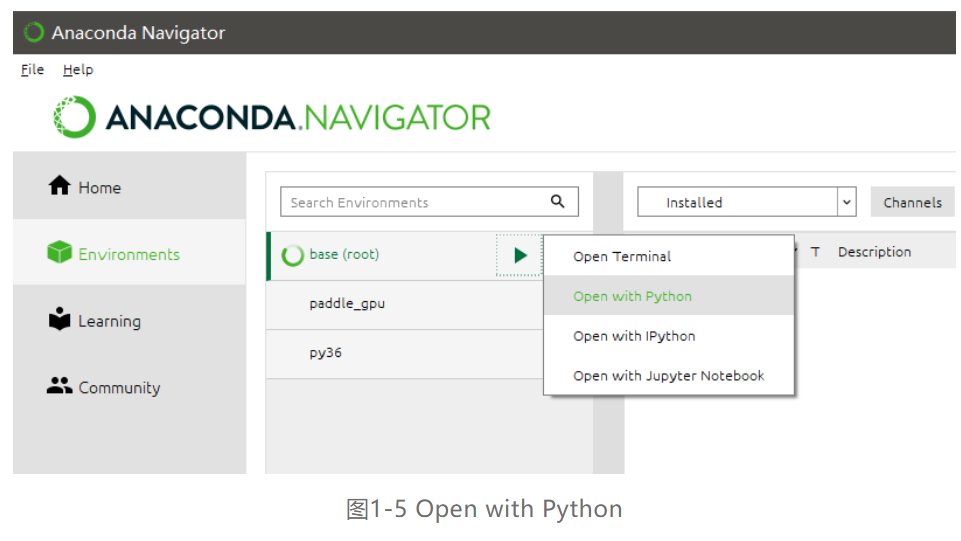
全部安装完毕后,在Windows“开始”菜单中选择 Anaconda Navigator ,进入主界后点击Environments 选项卡,如下图1-5所示可以看到当前的Anaconda默认虚拟环境是base(root),单击base(root)右侧的绿色箭头,在弹出的菜单中选择Open with Python。
在弹出Windows命令行窗口中,输入代码<print< font="">(“hello python”)>,得到如下图1-6的结果证明Anaconda和Python全部安装成功。

02 快速安装PaddlePaddle与PaddleSeg
2.1 PaddlePaddle简介
飞桨(PaddlePaddle)是由百度推出的集深度学习核心框架、工具组件和服务平台为一体的技术先进、功能完备的开源深度学习平台,已被中国企业广泛使用,深度契合企业应用需求,拥有活跃的开发者社区生态。提供丰富的官方支持模型**,并推出全类型的高性能部署和集成方案供开发者使用。
2.2 安装CUDA与cuDNN库
如果您的计算机有NVIDIA® GPU,请确保满足以下条件并且安装GPU版PaddlePaddle
■ CUDA 工具包10.1/10.2 配合 cuDNN 7 (cuDNN版本>=7.6.5) |
■ CUDA 工具包11.0配合cuDNN v8.0.4 |
■ CUDA 工具包11.2配合cuDNN v8.1.1 |
■ GPU运算能力超过3.0的硬件设备 |
安装CUDA和cuDNN库的步骤如下:
第一步,到网址https://developer.nvidia.com/cuda-downloads? 下载11.0vCUDA,如图2-1所示。
第二步,安装完成后双击exe文件开始安装,如图2-2所示。
第三步,之后只需要一路默认安装即可完成,如图2-3所示。
第四步,进入网址https://developer.nvidia.com/rdp/cudnn-download 安装cuDNN v8.0.4,这里需要登录,如果没有账号的话就去注册一个,如图2-4所示。

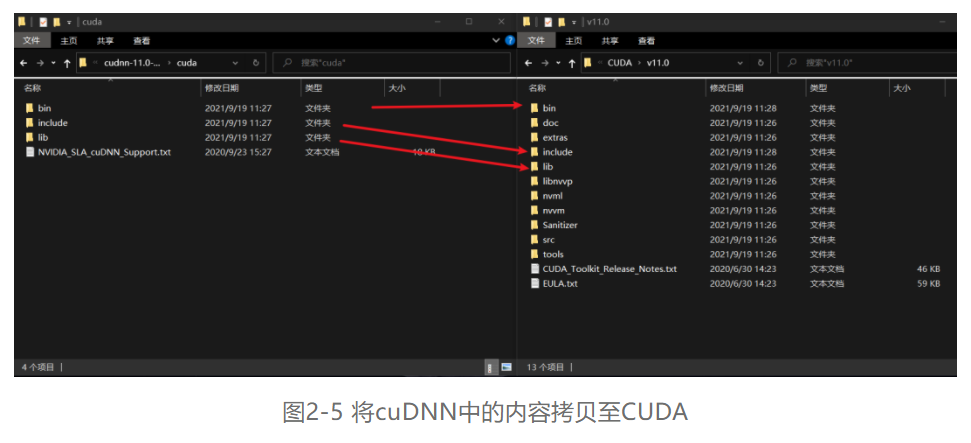
第五步,下载下来的文件是一个压缩包,解压后有三个文件夹bin、include和lib,依次将三个文件夹中的内容拷贝到CUDA的安装目录(默认情况下是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0)下的bin、include和lib下,这个要一一对应,如图2-5所示。
2.3 Windows下的PIP安装PaddlePaddle
2.3.1 环境准备
目前飞桨所支持的环境有:
■ Windows 7/8/10 专业版/企业版 (64bit) |
■ GPU版本支持CUDA 10.1/10.2/11.0/11.2,且仅支持单卡 |
■ Python 版本 3.6+/3.7+/3.8+/3.9+ (64 bit) |
■ pip 版本 20.2.2或更高版本 (64 bit) |
笔者本次所使用的环境是Windows10 专业版 (64bit),CUDA 10.2,python 3.8+。
2.3.2 创建python虚拟环境
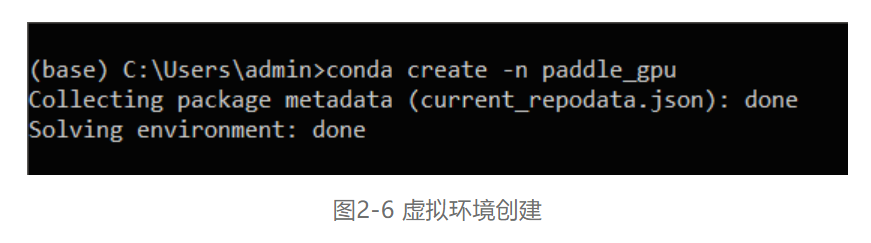
在Anaconda Prompt (Anaconda3)中利用conda create -n 虚拟环境名称 python=3.x来创建虚拟环境,具体如图2-6所示。
2.3.3 在虚拟环境中安装PaddlePaddle
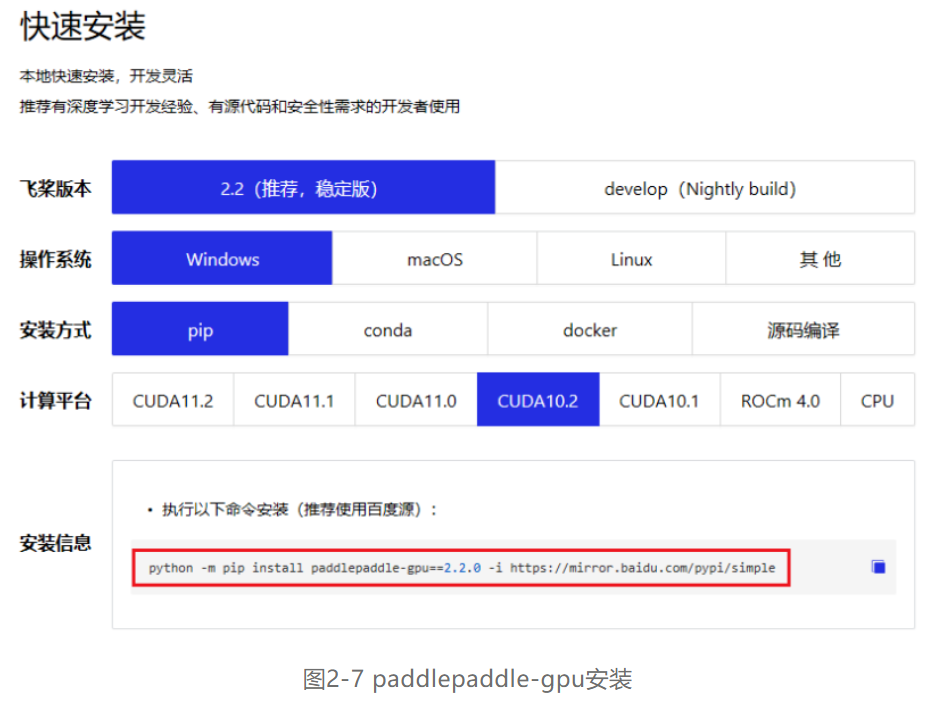
笔者这里选择了下载CUDA10.2,所有版本的下载指令都在官方网站https://www.paddlepaddle.org.cn/里,CUDA10.2的PaddlePaddle的安装指令为如下:
python -m pip install paddlepaddle-gpu==2.2.0 -i https://mirror.baidu.com/pypi/simple如图2-7所示,点击指令右边的**键在终端上运行即可下载。
2.3.4 验证安装
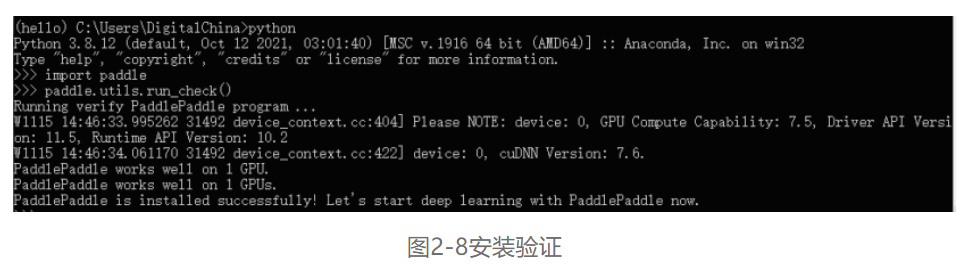
安装完成后您可以使用python进入python解释器,输入import paddle ,再输入 paddle.utils.run_check()如果出现PaddlePaddle is installed successfully!,说明您已成功安装,如图2-8所示。

2.4 安装PaddleSeg
2.4.1 安装git
Git是一个开源的分布式版本控制系统,可以有效、高速的处理从很小到非常大的项目版本管理。具体安装步骤如下:
第一步,从官网地址:https://git-scm.com/downloads下载最新版本的Git,如图2-9所示。
第二步,完成安装后会得到exe文件,双击打开,如图2-10所示。
第三步,之后只需要一路默认安装即可完成,如图2-11所示。
图2-11 git安装完成
第一步,在创建的虚拟环境上从gitee下载,下载命令如下:
git clone https://gitee.com/paddlepaddle/PaddleSeg.git -b release/2.2,如图2-12所示。
第二步,安装Python依赖库。首先通过如下命令:cd PaddleSeg ,进入到PaddleSeg的目录下,因为Python依赖库在requirements.txt中给出,所以可通过如下命令安装:pip install --upgrade -r requirements.txt,成功安装后如图2-13所示。
03 训练模型
本章节基于菠菜老师自己搜集的数据集,使用PaddleSeg进行花朵的图像分类模型的训练与推理。
3.1 数据集准备
从网址https://aistudio.baidu.com/aistudio/datasetdetail/104246进入网站下载数据集,并在PaddleSeg的文件夹中创建一个data文件夹,把下载好的数据集进行解压。
3.2 使用预训练模型进行训练
3.2.1 训练前设置
第一步,设置PYTHONPATH环境变量。只需设置PYTHONPATH,从而可以从正在用的目录(也就是正在交互模式下使用的当前目录,或者包含顶层文件的目录)以外的其他目录进行导入。具体的设置方法如图3-2所示。
第二步,设置gpu**。设置gpu**是为了指定使用哪张显卡训练,win下目前仅支持一张显卡训练,**设为0。
第三步,输入脚本pip install sklearn下载sklearn模块。具体的设置方法如图3-2所示。

3.2.2 模型训练
在PaddleSeg目录下创建一个脚本BisNet2_train.py,然后在Anaconda中输入脚本命令python BisNet2_train.py进行训练,关键的代码如下,完整的BisNet2_train.py代码在附件中。
第一步,数据的加载和预处理,如代码清单3-1所示:
代码清单3-1 数据的加载和预处理
#数据的加载和预处理
import paddleseg.transforms as T
train_transforms = [
T.RandomPaddingCrop(crop_size=(384,384)),
T.RandomHorizontalFlip(prob=0.3),
T.Resize(target_size=(416,416)),
T.Normalize()
]
val_transforms = [
T.Resize(target_size=(416,416)),
T.Normalize()
]
#训练数据集
train_dataset = Dataset(
dataset_root = dataset_dir,
train_path = train_path,
num_classes = 2,
transforms = train_transforms,
edge = True,
separator=' ',
ignore_index=255,
mode = 'train'
)
#评估数据集
val_dataset = Dataset(
dataset_root = dataset_dir,
val_path = test_path,
num_classes = 2,
transforms = val_transforms,
separator=' ',
ignore_index=255,
mode = 'val'
)
第二步,模型选择和开发,如代码清单3-2所示:
代码清单3-2 模型选择和开发
#模型组网
model = BiSeNetV2(
num_classes=2,
lambd=0.25
)
#模型训练和模型评估测试
loss_types = [
CrossEntropyLoss(), # 像素级优化
CrossEntropyLoss(),
CrossEntropyLoss(),
DiceLoss(), # 整体/局部的优化
DiceLoss()
]
loss_coefs = [1.0] * 5
loss_dict = {'types': loss_types, 'coef': loss_coefs}
lr = paddle.optimizer.lr.PolynomialDecay(learning_rate=0.01, decay_steps=3000, end_lr=0.0001)
opt_choice = paddle.optimizer.Momentum(learning_rate=lr, momentum=0.9, parameter***odel.parameters())
#启动模型全流程训练
train(
model,
train_dataset=train_dataset,
val_dataset=val_dataset,
optimizer=opt_choice,
save_dir='output',
iters=6000,
batch_size=8,
save_interval=100,
log_iters=20,
num_workers=0,
use_vdl=False,
losses=loss_dict,
keep_checkpoint_max=5
)
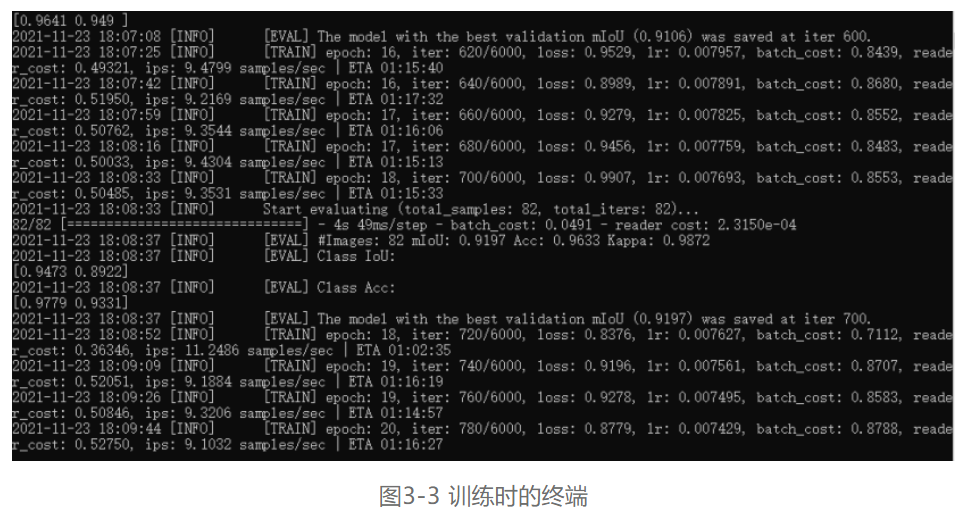
第三步,当模型开始训练时,我们不需要做任何操作,此时终端如图3-3所示:
此时,可以看到电脑消耗的显存如图3-4所示:

最后,训练完成后会在PaddleSeg的目录下生成一个output文件夹,里面的内容如图3-5所示。
3.2.4 模型导出
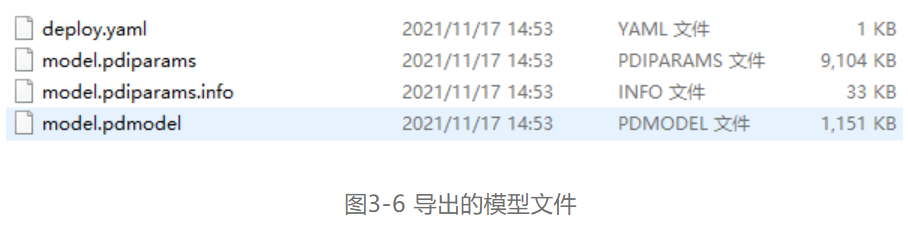
在Anaconda中输入命令python export.py --config C:\Users\DigitalChina\PaddleSeg\configs\bisenet\bisenet_road_224.yml --model C:\Users\DigitalChina\PaddleSeg\output\best_model\model.pdparams导出模型,在output文件夹下就会得到如图3-6这四个文件。
04 安装OpenVINO™ 工具套件部署
4.1 OpenVINO™ 工具套件简介
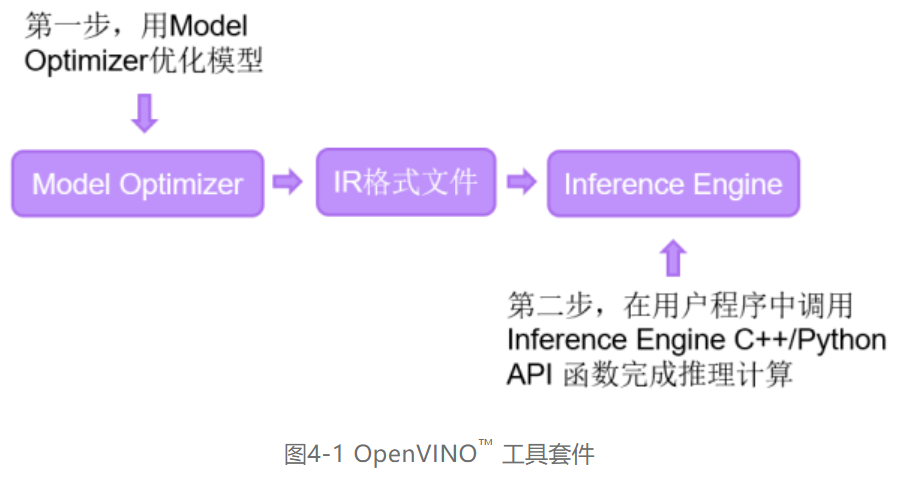
OpenVINO™ 工具套件全称是Open Visual Inference & Neural Network Optimization,是英特尔®于2018年发布的开源工具包,专注于优化神经网络推理。OpenVINO™ 工具套件主要包括Model Optimizer(模型优化器)和Inference Engine(推理引擎)两个部分。Model Optimizer是用于优化神经网络模型的工具,Inference Engine是用于加速推理计算的软件包。如图4-1所示,即为OpenVINO™ 工具套件的主要组成部分。
4.2 OpenVINO™ 工具套件安装
4.2.1 OpenVINO™ 工具套件下载和安装
下载并安装OpenVINO™ 工具套件的具体步骤如下。
第一步,通过网址https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html进入OpenVINO™ 工具套件官网下载页面,选择合适的版本,本文选择2021.4版本的OpenVINO™ 工具套件,按照如图5-2所示选择,再点击Download按钮即可下载OpenVINO™ 工具套件2021.4版本的安装程序。
第二步,找到OpenVINO™ 工具套件的安装文件w_openvino_toolkit_p_2021.4.689.exe,双击下载安装,安装步骤全部默认安装即可,如图4-3所示。
第三步,安装过程中会有CMake和Mircrosoft Visual Studio依赖软件安装的提示,下面我们继续安装CMake和Mircrosoft Visual Studio软件。
4.2.2 CMake下载和安装
CMake作为一个跨平台的C/C++程序编译开源配置工具,在OpenVINO™ 工具套件的应用中,CMake用来管理OpenVINO™ 工具套件中的演示程序(Demos)和范例程序(Samples)。
下载并安装Cmake的步骤如下所示。
第一步,通过网址https://cmake.org/download/ 进入CMake官网下载界面,下载安装文件,选择的CMake版本大于等于3.4版本即可,本文的版本选择为cmake-3.21.3-windows-x86_64.msi,如图4-4所示
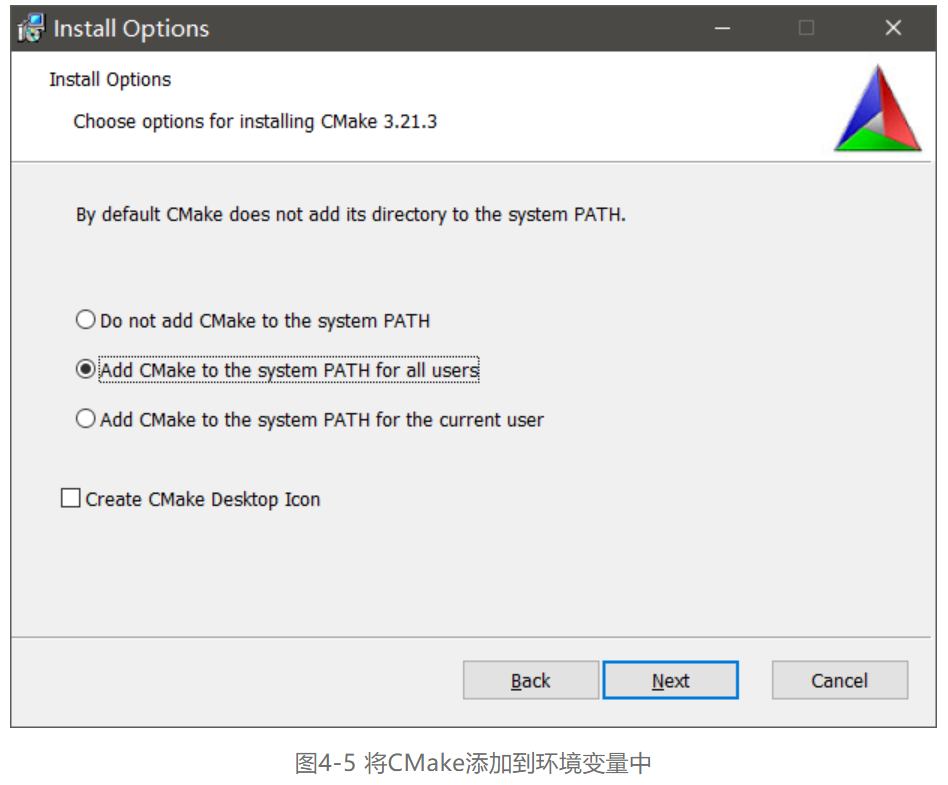
第二步,双击安装文件,默认选项完成安装,在Install Options页面选择Add Cmake to the system PATH for all users将CMake添加到系统变量PATH中。如图4-5所示。
4.2.3
Mircrosoft Visual Studio下载和安装
OpenVINO™ 工具套件支持Mircrosoft Visual Studio 2015、2017和2019。由于Mircrosoft Visual Studio 2017是目前Windows操作系统下应用最广泛的C++ IDE,本文选择使用Mircrosoft Visual Studio 2017版本。
Mircrosoft Visual Studio 2017安装步骤如下:
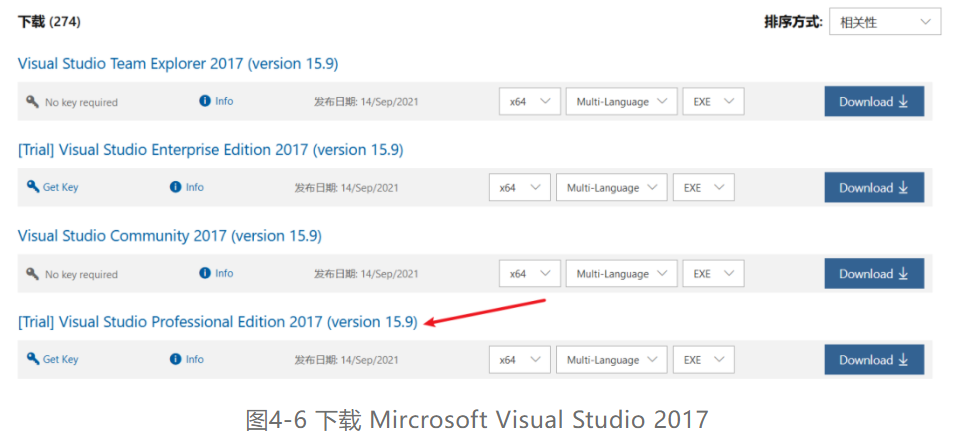
第一步,通过网址https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/ 进入Mircrosoft Visual Studio旧版本下载地址,单击2017,在展开的下载选项中点击“下载”按钮进入Mircrosoft Visual Studio 2017下载页面,在左侧选择Visual Studio 2017(version 15.9),在右侧的选择页面中选择Visual Studio Community 2017(version 15.9),单击Download下载,如图4-6所示。
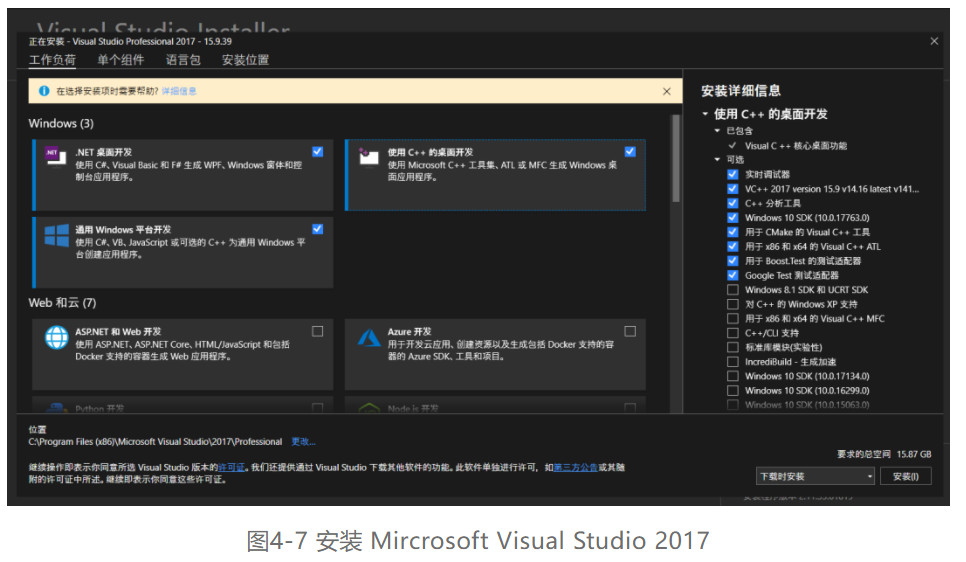
第二步,找到安装文件双击打开,在安装配置中选择“.NET桌面开发”、“使用C++的桌面开发”、“通用Windows平台开发”三个选项后,再选择右下角的“安装”按钮开始安装,如图4-7所示。
4.2.4 OpenVINO验证安装
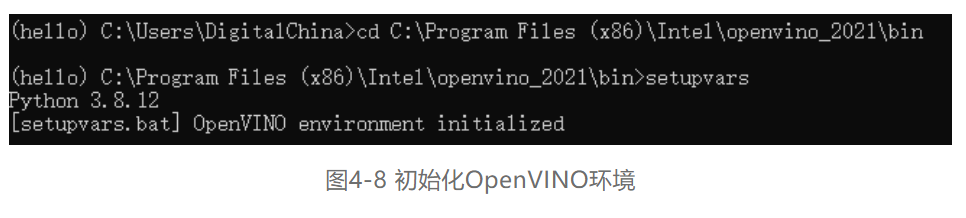
打开命令行输入刚才openvino的安装路径,这里以笔者的为例,输入cd C:\Program Files (x86)\Intel\openvino_2021\bin。再输入:setupvars设置一个临时的环境变量,如图4-8所示。
05 使用OpenVINO™ 工具套件部署BisNetV2模型
5.1 使用Model_Optimizer优化模型
5.1.1 转Paddle模型到ONNX
在前面的章节中,我们已经获得了Paddle的模型,由于目前OpenVINO的model_optimizer还不支持Paddle直接转成IR格式文件,因此需要先转成ONNX类型。具体步骤如下:
第一步,安装paddle2onnx,命令行输入pip install paddle2onnx。
第二步,利用paddle2onnx转换模型,输入paddle2onnx --model_dir C:\Users\DigitalChina\PaddleSeg\output --model_filename model.pdmodel --params_filename model.pdiparams --save_file C:\Users\DigitalChina\PaddleSeg\onnx_models\road_seg.onnx --opset_version 11 --enable_onnx_checker True
这里 model_dir, model_filename, 以及params_filename和save_file替换成自己的文件路径就好。--save_file是转换后的模型要保存的目录,--enable_onnx_checker 把这个也启动,让转换程序帮我们检查模型,如图5-1所示即为转换成功。

5.1.2 转ONNX模型到IR格式
model_optimizer可以支持ONNX模型的转换,具体步骤如下:
第一步,输入命令来到model_optimizer目录下
cd C:\Program Files (x86)\Intel\openvino_2021\deployment_tools\model_optimizer
第二步,输入如下命令实现转换
python mo_onnx.py --input_model C:\Users\DigitalChina\PaddleSeg\onnx_models\road_seg.onnx --output_dir /openvino/FP16 --input_shape [1,3,224,224] --data_type FP16 --scale_values [127.5,127.5,127.5] --mean_values [127.5,127.5,127.5]
--data_type来指定模型的精度,--input_shape来指定模型接受图像的形状。最关键的两点我要拿出来讲,分别是--mean_value(MV)和--scale_values(SV)。在转到IR模型的时候如果指定了这2个参数,那么在之后用模型做推理的时候就可以不用做Normalization。当转换成功时,将会出现如图5-2中的SUCCESS提示。
5.2 Inference Engine 应用程序典型开发流程
Inference Engine典型的开发流程一共有八步,如图5-3所示:
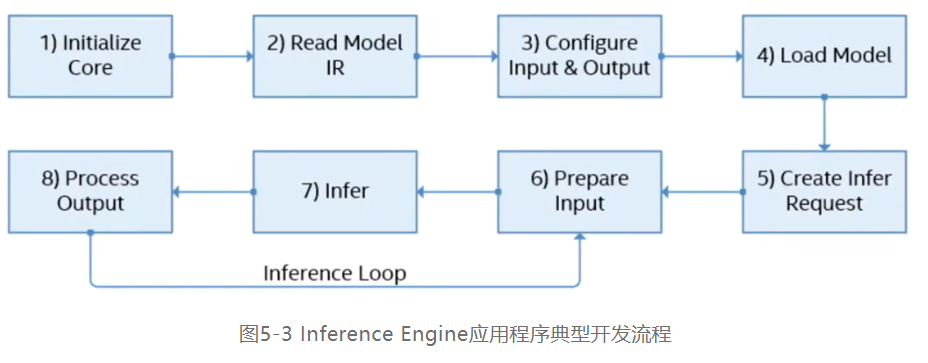
本次的案例开发将会基于Python(环境配置以及使用难度都对于入门新手比较友好),故使用Python对应的API来简单介绍以上的流程。
1.初始化IECore实例:使用ie=IECore()来初始化Core对象,可用于管理可用设备和读取网络对象。
2.读入一个IR模型:net = ie.read_network(model=model_xml,weight***odel_bin),将IR模型的路径赋给model_xml与model_bin便可以读取。
3.配置输入:使用input_blob = next(iter(net.inputs))定义输入。
4.将网络加载到设备:exec_net = ie.load_network(network=net, device_name="CPU")将模型加载到设备,载入的硬件由device_name参数决定。
5.创建推理请求:模型载入AI计算硬件后会得到一个infer对象,用于执行AI推理计算。
6.输入数据:使用img = cv2.imread(img_fn)获取图像和数据。
7.执行推理:使用exec_net.infer(inputs={input_blob:img_input})进行异步请求推理。
8.输出结果:使用result = exec_net.infer(inputs={input_blob: img_input}) 获得推理计算结果。
5.3 编写OpenVINO™ AI推理计算Python范例
本节将基于5.1节生成的IR文件flower_rec.xml和flower_rec.bin,从零开始,实现完整的OpenVINO™ AI 推理计算python程序。
5.3.1 openvino中python
和环境变量的设置
第一步,将路径C:\Program Files (x86)\Intel\openvino_2021.4.689\python\python3.6下的openvino文件**一份到python安装路径E:\python3.6\Lib\site-packages(python的安装路径可能有所不同,关键是找到Lib\site-packages下即可)下,如图5-4所示。
第二步,使用pip install -r "C:\Program Files(x86)\Intel\openvino_2021\python\python3.8\requirements.txt"将所需要的库进行安装。
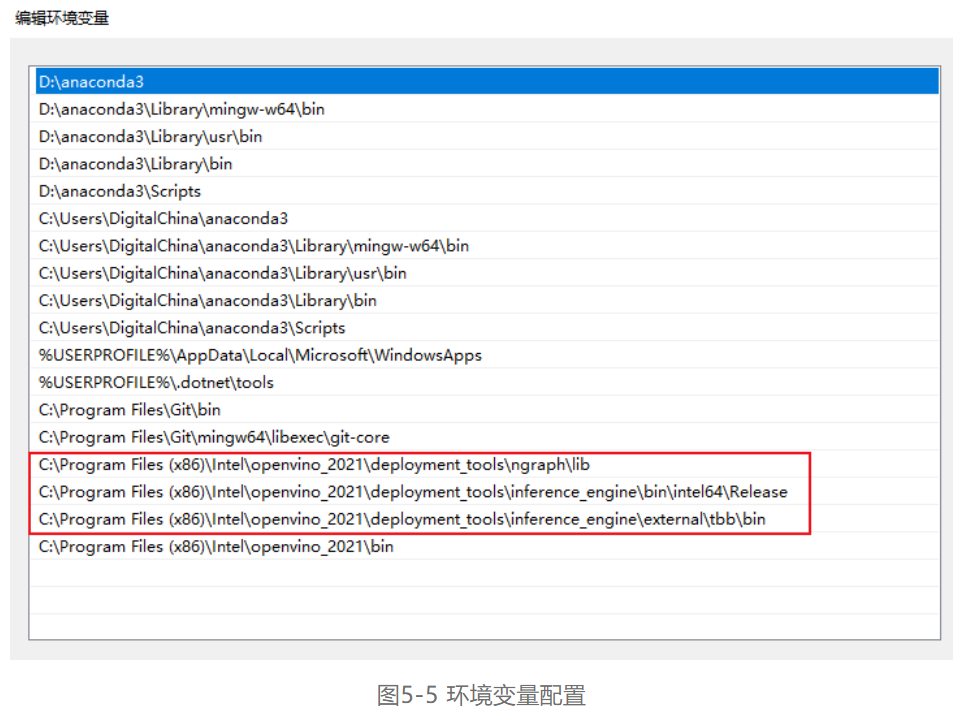
第三步,将图5-5中红框标识的路径配置进系统环境变量当中。
第四步,在PyCharm中输入如图5-6所示的代码,若能正常输出设备名称则为配置成功。

5.3.2 开发AI推理计算Python应用程序
在成功配置环境变量和项目属性后,使用Python编程语言开发OpenVINO™ 推理应用程序。
第一步,引入相应库函数,配置推理计算设备,IR文件路径,媒体文件路径,如代码清单6-1所示:
代码清单6-1 引入相应库和配置路径
#Step1
from openvino.inference_engine import IENetwork,IECore
import numpy as np
import paddleseg.transforms as T
import cv2 as cv
model_xml = r"C:/openvino/FP16/road_seg.xml"
model_bin = r"C:/openvino/FP16/road_seg.bin"
transforms = [T.Resize(target_size=(224,224))] 其中,各个库的用途如下:
■ import IECore定义和实现Inference Engine的类、方法以及函数。 |
■ import cv2 OpenCV库,包含了OpenCV的各个模块。 |
■ import numpy 用于对图像矩阵的处理。 |
■ import paddleseg.transform 用于将图像预处理/增强操作进行组合和裁剪 |
第二步,初始化Core对象,管理可用设备和读取网络对象,如代码清单6-2所示
代码清单6-2 初始化Core对象
#Step2 初始化Core对象
ie = IECore() 第三步,使用读取IR模型(支持.xml格式),将IR模型读入ie.read_network
方法中去。如代码清单6-3所示:
代码清单6-3 读入IR模型
#Step3 读取IR模型
net = ie.read_network(model=model_xml,weight***odel_bin) 第四步,配置模型输入和输出,将模型载入内存后,使用net.outputs和net.inputs参数保存输入和输出,如代码清单6-4所示:
代码清单6-4 配置输入
#Step4 配置模型输入
input_blob = next(iter(net.inputs))
第五步,使用ie.load_network()将模型加载到设备,载入的硬件由LoadNetwork()方法的DEVICE参数决定。如代码清单6-5所示:
代码清单6-5 载入模型到硬件
#Step5 将模型加载到设备
exec_net = ie.load_network(network=net, device_name="CPU") 第六步,准备输入数据,并按模型要求对图像矩阵进行转置处理,如代码清单6-6所示
代码清单6-6 准备输入数据
#Step6 准备输入数据
img_fn = 'C:/openvino/boxhill_079.jpg'
img = cv.imread(img_fn)
img, _ = T.Compose(transforms)(img)
第七步,执行推理计算,使用此前加载到设备上的模型exec_net的infer()方法进行推理,如代码清单6-7所示:
代码清单6-7 执行推理计算
#Step7 执行推理计算
result = exec_net.infer(inputs={input_blob:img_input})
img_segmentation = result['save_infer_model/scale_0.tmp_1'] 第八步,处理推理计算结果,使用numpy的np.max()和np.argmax()方法对输出结果进行筛选,获得对应输入图像的推理得分以及标签索引,之后再利用Opencv的putText()与imshow()方法对结果进行显示,如代码清单6-8所示:
代码清单6-8 输出推理计算结果
#Step8 处理推理计算结果
img_segmentation = np.squeeze(img_segmentation)
class_colors = [[0,0,0], [0,255,0]]
class_colors = np.asarray(class_colors, dtype=np.uint8)
img_mask = class_colors[img_segmentation]
img_mask, _ = T.Compose(transforms)(img_mask)
img_overlayed = cv2.addWeighted(img, 0.8, img_mask, 0.2, 0.5)
img_overlayed = img_overlayed.transpose(1,2,0)
img_overlayed = cv2.cvtColor(img_overlayed, cv2.COLOR_RGB2BGR)
save_img(img_overlayed, 'demo.jpg') 第九步,执行程序ir.py,若执行无误将会在桌面上出现如图5-8所示的结果,另外附上图5-7未推理前的图片给大家做对比。

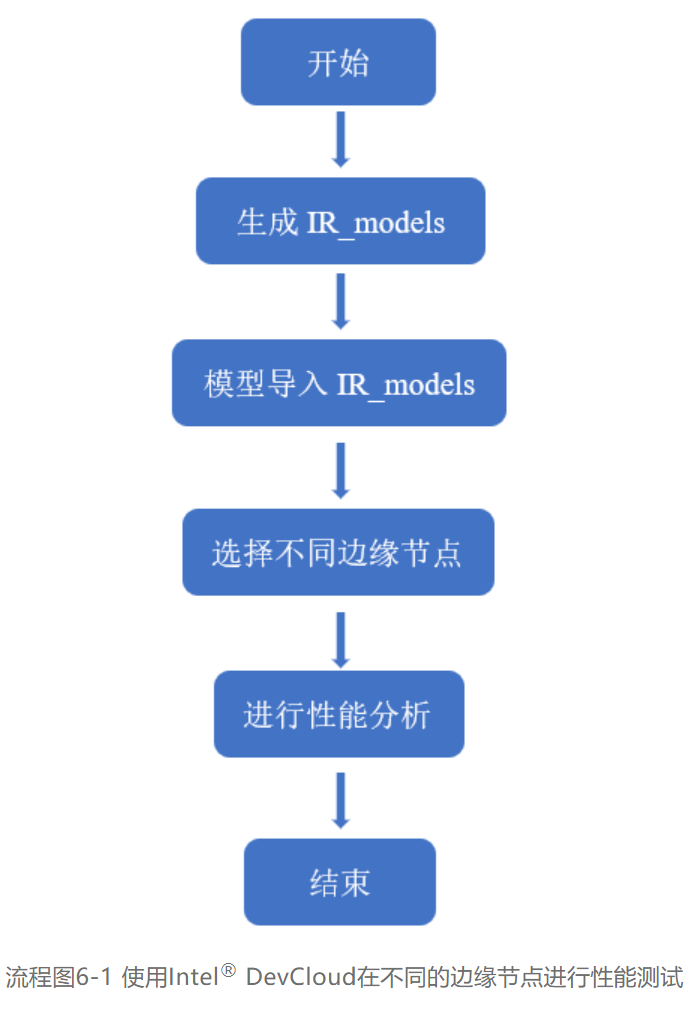
03 使用Intel® DevCloud 不同边缘节点进行性能测试
面向边缘的Intel® DevCloud是一项云服务,旨在帮助开发人员使用Intel® OpenVINO™ 工具套件构建原型并试验计算机视觉应用,注册成功后,可以访问一系列的基于Python和C++的Iupyter* Notebook教程和示例解决方案,并通过web浏览器直接执行。本文通过Jupyter* Notebook中给出的基于Python语言的Benchmark_APP示例,访问不同的边缘节点进行性能测试。
使用Intel® DevCloud在不同的边缘节点进行性能测试一共分为四个步骤,
第一步,在Intel® DevCloud的Benchmak_APP目录下创建IR_models文件夹目录结构
第二步,将BiSeNetV2 IR模型导入IR_models内对应数据格式子文件夹
第三步,使用Benchmark_APP对不同的边缘节点进行性能测试
第四步,通过测试结果进行性能分析,选出高性能AI部署解决方案
具体步骤如流程图6-1所示:
6.1 生成IR_models目录结构并导入模型
在Jupyter* Notebooks的Reference-samples/iot-devcloud/openvino-dev-latest/develop-samples/python/benchmarkAPP-python的所在目录中,创建IR_models目录结构,因为Benckmark_APP的路径是固定的,需要配合其固定好的目录结构,让Benchmark_APP能够找到对应的IR_models。首先创建IR_models文件夹,创建的子文件夹名字基于你转换IR格式时所选择的精度,笔者选择的是FP16,所以在文件夹中创建FP16的子文件夹,上传自己的模型到子文件夹中。其具体步骤如下:
第一步,首先进入网址https://devcloud.intel.com/edge/,注册并登录,然后进入网址https://software.intel.com/content/www/us/en/develop/tools/devcloud/edge/build.html后,点击页面中显示的“Connect and Create”下的Connect to Jupyter Notebook按键,如图6-1所示。即可转入Jupyter* Notebooks界面,然后即可运行相关测试。
第二步,进入Reference-samples/iot-devcloud/openvino-dev-latest/develop-samples/python/benchmarkAPP-python路径目录下,然后点开右上方的“New”选项,在弹出的选项框中选择“Teminal”进入命令行终端。如图6-2所示。
第三步,进入命令行终端后即可在命令行终端使用命令创建IR_models文件夹目录结构,进入Teminal后,使用命令< cd ~/Reference-samples/iot-devcloud/openvino-dev-latest/developer-samples/python/benchmarkApp-python >进入benchmarkAPP-python的文件夹目录下,再使用命令

图6-3 创建BiSeNetV2工作文件夹
第四步,使用命令

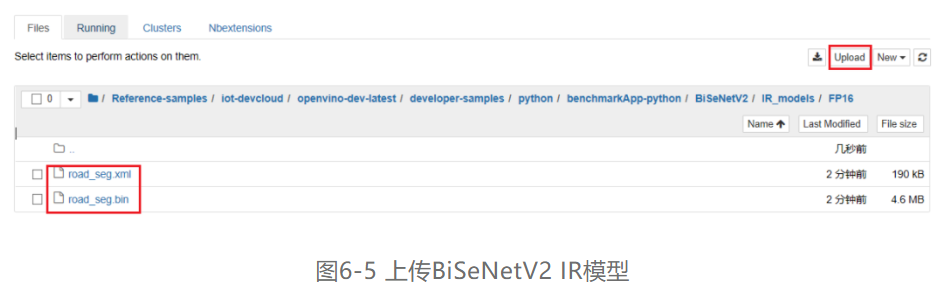
第五步,导入BiSeNetV2模型,根据使用模型优化器进行模型转换时的数据格式,对应不同子文件夹上传BiSeNetV2 IR模型,本文以数据格式FP16为例,将IR模型导入FP16的文件夹,如图6-5所示。首先进入FP16子文件夹内,点击右上角“Upload”按键,选择正确本地路径,再点击“确定”即可将BiSeNetV2 IR模型上传到数据格式为FP16的IR_models文件夹中。
6.2 访问边缘节点进行性能测试
将“创建IR_models目录结构”和“导入本地BiSeNetV2模型”的准备工作做完后,即可访问Intel® DevCloud的边缘节点,对不同的Intel硬件进行性能的测试本文。使用Intel® DevCloud 提供的基于Python语言的Benchmark_APP示例,访问不同的边缘节点进行性能测试。其步骤如下:
第一步,打开Reference-samples/iot-devcloud/openvino-dev-latest/developer-samples/python/benchmarkApp-python路径下的“BenchmarkAPP.ipynb”,点击左边目录“1.9 Creating lists of FP16 and FP32 models”查看其Python脚本,并在脚本中添加语句“models = ["BiSeNetV2"]”,从头运行到1.9节(其中1.8节可以跳过,因为不需要使用AWS S3存储桶存储模型文件),可以看到以及读入FP16数据格式的BiSeNetV2 IR模型,如图6-6所示。

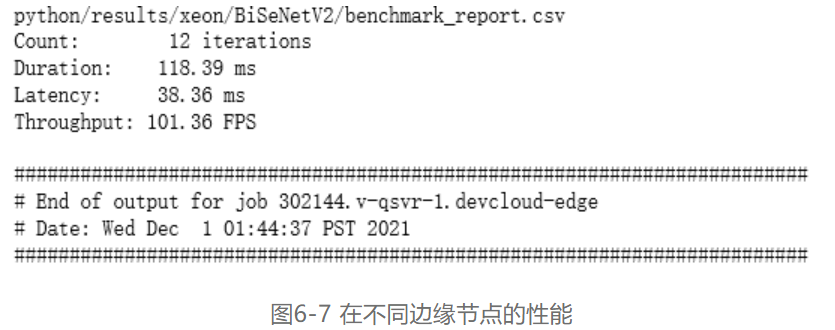
第二步,读入IR模型后,请先运行“BenchmarkAPP.ipynb”里的“Intel® Distribution of OpenVINO™ Toolkit version check:”和“Wait until the benchmarking report files are written”两个部分。然后即可使用深度学习模型对单个系统进行基准测试。在“Benchmark Individual system with the deep learning model”这一部分单元格中,列举五个不同硬件的边缘节点来进行推理工作。首先以“3.0.1 Run the Benchmark tool app with Intel® Core™ CPU”单元格为例,此单元格将作业提交给配备Intel® Core™ i5 6500TE CPU的IEI Tank* 870的边缘节点,推理工作将在CPU上运行。运行完此单元格后,会在“benchmarkAPP-python”路径下生成相关的“benchmark_app_job.sh…”相关运行日志文件。点开日志文件,便可以显示出在此边缘节点推理的吞吐量和延迟,如图6-7所示:
第三步,确定Intel® DevCloud所支持的边缘节点群,边缘计算节点是面向物联网边缘机器学习推理构建和配置的工业计算系统,并已经托管在DenCloud中,一边使用预先开发的示例或者试验各种架构和解决方案。首先确定Intel® DevCloud所支持的边缘节点群,以及他们的Group ID。进入网址https://devcloud.intel.com/zh/edge/resource_docs/selecting_targets/-u8fb9-u7f18-u8282-u70b9即可查看Intel® DevCloud所支持的边缘节点群及其相关的配置信息,如图6-8所示:

6.3 对不同边缘节点进行性能分析
在边缘节点群中可以根据需求选择不同的边缘节点,对不同的架构或解决方案进行试验,在本步骤以Group ID为idc046,CPU为Intel® Core™ i5-1145G7E,GPU为Intel® Iris® Xe Graphics边缘节点为例,介绍怎样在“BenchmarkAPP.ipynb”中添加新的边缘节点并使用Benchmark_APP对其边缘节点的模型部署进行性能测试和分析。
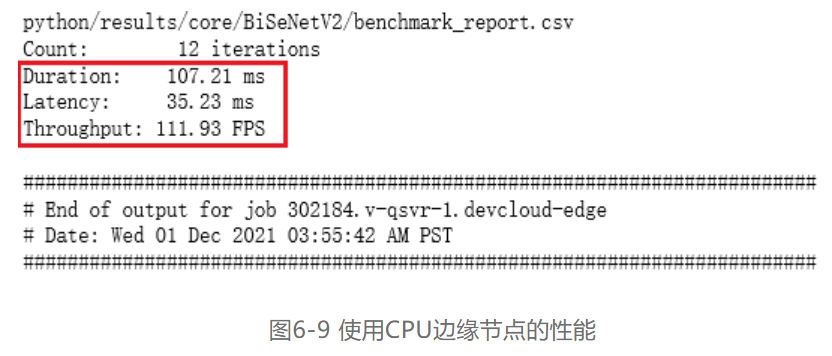
6.3.1 使用CPU边缘节点进行性能分析
使用Intel® Core™ i5 1145G7E CPU边缘节点进行性能分析的具体操作步骤如下:
第一步,在“BenchmarkAPP.ipynb”中重新打开一个单元格,并将单元格“3.0.1 Run the Benchmark tool app with Intel® Core™ CPU”里的代码脚本**进新打开的单元格。
第二步,将单元格内脚本代码的第一行
6.3.2 使用GPU边缘节点进行性能分析
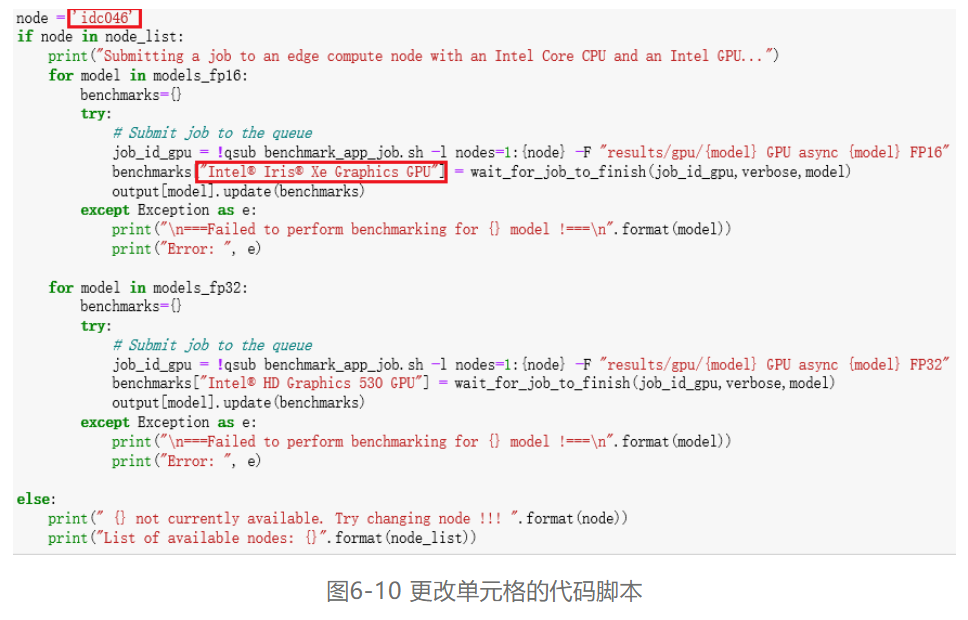
使用Intel® Iris® Xe Graphics GPU边缘节点进行性能分析的具体操作步骤如下:
第一步,在“BenchmarkAPP.ipynb”中重新打开一个单元格,并将单元格“3.0.3 Run Benchmark tool application with Intel® HD Graphics 530 GPU”里的代码脚本**进新打开的单元格。
第二步,将单元格内脚本代码的第一行
第三步,由于本次的GPU边缘节点为Intel® Iris® Xe Graphics,且模型的数据格式为FP32,所以请修改脚本中第十九行
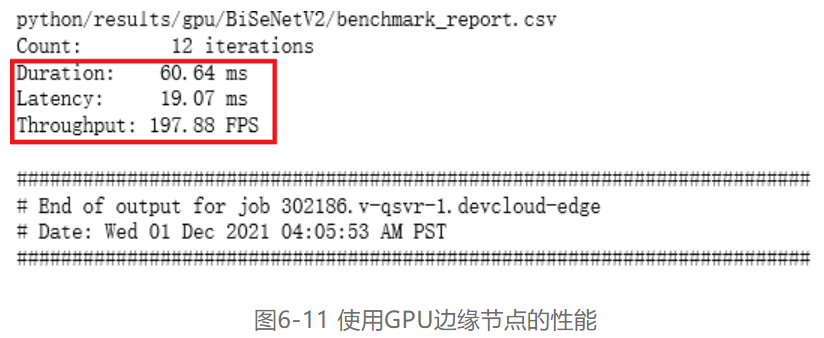
第四步,代码更改完毕后,即可启动运行单元格,同2.2节第二步表述的过程一样,会在“benchmarkAPP-python”路径下生成相关的“benchmark_app_job.sh…”相关运行日志文件。点开日志文件,便可以显示出在GPU为Intel® Iris® Xe Graphics边缘节点推理的吞吐量和延迟,如图6-11所示:
6.4 BiSeNetV2模型在不边同缘节点性能
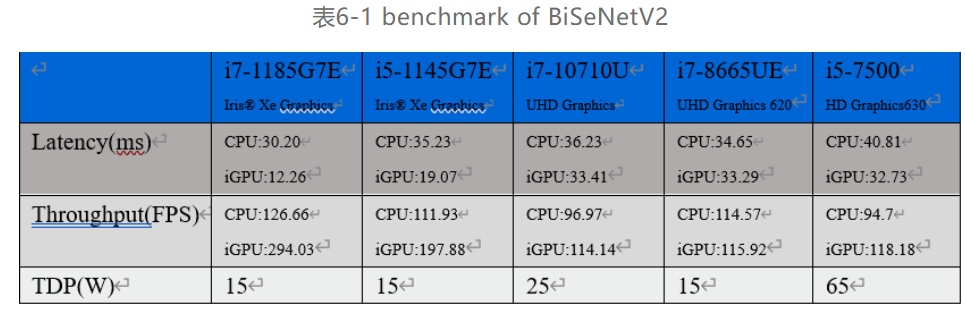
将Group ID为idc046,CPU为Intel® Core™ i5 1145G7E,GPU为Intel® Iris® Xe Graphics边缘节点的CPU和GPU吞吐量和延迟测试出来后,即可同样步骤对其他边缘节点进行性能的分析,本文选择了7-11th CPU的边缘节点,进行性能的测试与对比,结果如表6-1所示,在表中的边缘节点群中可以根据需求选择不同的边缘节点,对不同的架构或解决方案进行试验。
6.5 本章小结
通过使用Intel® DevCloud的Benchmark_APP在各个目标硬件上进行性能测试,其覆盖的边缘计算方案可以应用多个场景,比如在最高吞吐量应用场景可以选择i7-1185G7或i5-1145G7搭配Iris® Xe Graphics,通过Iris® Xe Graphics进行IR模型的推理,最低功耗应用场景可以选择功耗为15W TDP的i7-1185G7E或i5-1145G7E,通过Iris® Xe Graphics进行IR模型的推理。或者推荐功耗为15W TDP的i7-8865UE,由CPU做推理。由此看来DevCloud和OpenVINO™ 工具套件可以帮助计算机视觉应用程序开发人员充分利用其应用程序,并可以为每个任务和解决方案选择最理想的硬件。
在AI应用程序、解决方案等开发过程中,在程序准备好后,我们可以在开发服务器的CPU上运行代码,或者将代码发送至Intel® DevCloud中的一个或者多个边缘计算硬件集群,以加速推理。通过这些试验,开发者可以完全了解了所需的知识,避免潜在的陷阱、优化性能,确认需要采购的硬件,以加速产品上市速度!
07 总结
本文通过从零开始训练提供了数据集的图像分割BisNetV2模型,详细介绍了基于PaddleSeg框架和预训练模型,使用Python编程语言训练路面分割的完整流程,在模型部署模块中,详细介绍了OpenVINO™ 工具套件及其重要组件Inference Engine的安装和使用,将训练完毕的BisNetV2模型转换为IR格式文件后,使用Python编程语言进行AI应用程序的开发方法。在使用Inference Engine进行模型推理部署是,OpenVINO™ 工具套件提供了八个统一的API接口,流程化的开发方式极大降低了AI应用程序开发的难度,对于不同模型的不同输入输出节点,只需少量改动应用程序,便可快速独立开发属于自己的AI应用程序。
* 本文内容及配图均为“英特尔物联网”的原创内容。该公众号的运营主体拥有上述内容的著作权或相应许可。除在微信朋友圈分享之外,如未经该运营主体书面同意,请勿转载、转帖或以其他任何方式**、发表或发布上述内容。如需转载上述内容或其中任何部分,请留言联系。