干货|PyTorch + OpenVINO™ 开发实战系列教程 第四篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
第4章 人脸与Landmark检测
前面一章主要介绍了图象分类的基本原理、常见模型、迁移学习的基本概念。结合这些基础概念介绍了Pytorch中预训练模型库的使用,以及如何基于自定义数据与迁移学习实现自定义图象分类模型训练与部署使用。
本章我们将更近一步,说明如何使用OpenVINO™ 工具套件中自带的模型库,实现人脸检测与landmark检测。然后通过我们我们自己收集与整理并标注一个人脸landmark数据集,实现自定义人脸landmark模型的训练与部署测试。帮助读者更好的了解OpenVINO™ 工具套件模型库的使用,Pytorch模型训练与部署等相关知识点。
好了,下面我们就开启这一段有趣的技术探索!
4.1 OpenVINO™ 工具套件人脸检测
OpenVINO™ 工具套件的模型库中提供了多个对象检测模型,其中就包含人脸检测,2021.4版本中提供了多个人脸检测模型,这些人脸检测模型有着不同的图象输入分辨率与检测精度,适应不同的场景应用。在实际使用OpenVINO™ 工具套件场景中,是可以考虑直接使用这些人脸检测模型的,根据不同的模型大小与速度,可以选择不同的人脸检测模型。本节我们就一起来探讨OpenVINO™ 工具套件中的人脸检测模型使用。
4.1.1 人脸检测模型
在OpenVINO™ 工具套件TM ToolKit 2021.4版本包含的模型库中有以下几个人脸检测的相关模型,它们名称、输入图象分辨率与适用场景如下:
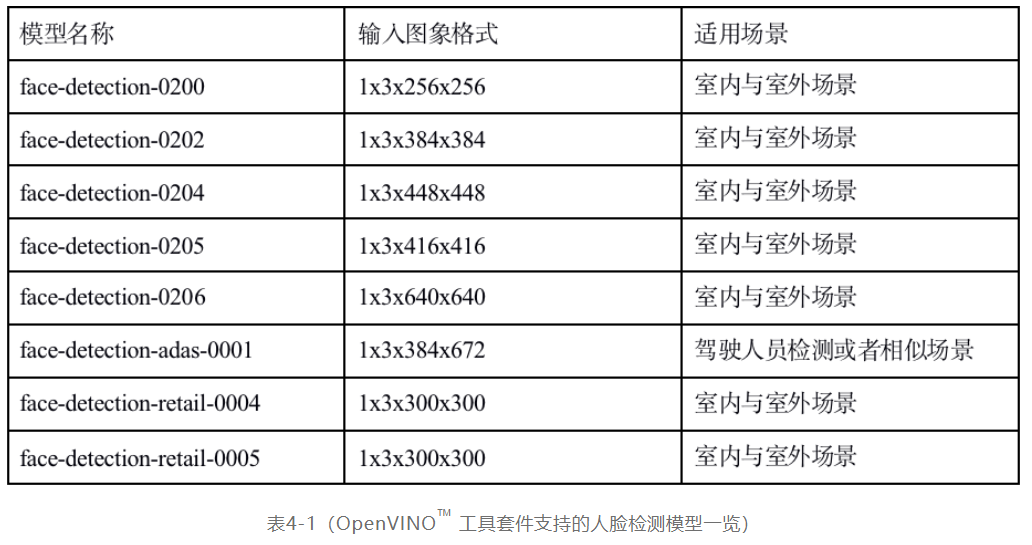
其中输入图象分辨率与格式表示方式为NCHW,这里就不再赘述。这些模型在输出格式方面,205与206(face-detection-0205与face-detection-0206)输出为两个部分,其中一个部分是标签,因为只有一个类别,标签索引均为0,可以不处理;另外一个输出名称为“boxes”格式为:Nx5,这五个数分别为:[`x_min`, `y_min`, `x_max`, `y_max`, `conf`]分别表示检测框的左上角与右下角坐标,conf表示置信度,取值范围为0~1之间。其它模型的输出格式均为1x1xNx7的输出方式,其中N根据不同模型支持的值会不一样,这七个值分别为:[`image_id`, `label`, `conf`, `x_min`, `y_min`, `x_max`, `y_max`],其中image_id表示图象索引,默认为0、label表示类别索引,这里只有一个,所以值也为0、conf表示置信度取值范围在0~1之间、最后四个值表示的检测框的的左上角与右下角坐标。
关于模型的输入与输出格式相关更详细的信息,强烈建议读者在安装好的OpenVINO™ 工具套件工具包
%install_dir%\OpenVINO_2021.4.582\deployment_tools\open_model_zoo\models\intel
目录下找对应的markdown文档查阅。
4.1.2 模型使用
在介绍了OpenVINO™ 工具套件中的人脸检测模型的基础上,开发者就可以通过OpenVINO™ 工具套件推理引擎(IE)SDK来实现模型的加载、输入与输出设置、模型推理与后处理输出,实现一个人脸检测演示。要着手实现OpenVINO™ 工具套件人脸检测代码演示,首先需要的就是下载模型文件,模型文件的下载的命令行如下:
python downloader.py –name fileanme1[,filename2,filename3……]
首先打开命令行窗口,切换目录到(假设默认安装路径为C:\Program Files (x86)\Intel\),然后执行下面的命令行,即可下载这些人脸检测模型文件:

下载好这些模型之后,可以拷贝到制定的一个文件夹内,这样比较方便后续代码演示使用方便。基于OpenVINO™ 工具套件的人脸检测模型实现人脸检测,代码演示分为如下几步完成:
1):加载模型设置输入与输出
ie = IECore()
for device in ie.available_devices:
print(device)
# Read IR
net = ie.read_network(model=face_xml, weights=face_bin)
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))
# 输入设置
n, c, h, w = net.input_info[input_blob].input_data.shape
2):创建推理请求对象,关联设备
# 设备关联推理创建
exec_net = ie.load_network(network=net, device_name="CPU")
注意:这里可以根据第一步查询到的支持设备,替换device_name参数。
3):输入图象预处理并执行推理
# 处理输入图象
src = cv.imread("D:/images/persons.png")
image = cv.resize(src, (w, h))
image = image.transpose(2, 0, 1)
# 推理
res = exec_net.infer(inputs={input_blob:[image]})
预处理部分的代码相关函数与参数含义在本书第二章中都已经详细阐述,这里不再赘述。
4):后处理与结果显示
对推理得到的输出结果,根据使用的不同模型,后处理方式有所不同。205与206人脸检测模型输出的预测结果跟其余模型稍有差异,这部分在代码处理时需要稍加注意,后处理的代码如下:
# 后处理
ih, iw, ic = src.shape
res = prob[out_blob]
if res.ndim == 4: # SSD
for obj in res[0][0]:
if obj[2] > 0.5:
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
cv.rectangle(src, (xmin, ymin), (xmax, ymax), (0, 255, 255), 2, 8)
cv.putText(src, str("%.3f"%obj[2]), (xmin, ymin), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, 8)
else: # 205, 206 FOCS, ATSS
res = prob["boxes"]
for obj in res:
if obj[4] > 0.5:
xmin = int(obj[0] * iw / w)
ymin = int(obj[1] * ih / h)
xmax = int(obj[2] * iw / w)
ymax = int(obj[3] * ih / h)
cv.rectangle(src, (xmin, ymin), (xmax, ymax), (0, 255, 255), 2, 8)
cv.putText(src, str("%.3f" % obj[4]), (xmin, ymin), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1, 8)
print(res.shape)
cv.imshow("face_detect", src)
cv.waitKey(0)
上面的代码从预测结果prob中如果获取到的res数组维度为4则表示模型是SSD检测头输出,格式为1x1xNx7数据,按照说明解析即可;如果prob中获取到的res数组不是四维的,则为205或者206两个人脸检测模型,它的boxes部分输出格式为Nx5,N表示box框数目,5表示box框的左上角与右下角坐标。
注意:205与206人脸检测模型预测坐标值是基于输入图象大小的实际值,而其余人脸检测模型输出的坐标是相对值在0~1范围之间。
上面的人脸检测演示代码,第三步与第四步可以循环使用,实现视频中的人脸检测。
4.2 landmark检测
人脸landmark在人脸对齐、人脸重建、身份鉴别、人脸编辑与人脸AR等方面都有重要作用,一直是人脸研究领域的重点。
4.2.1 人脸landmark概念
但是什么是人脸landmark,首先看一张图:

上图在检测人脸得到白色矩形框区域的基础上,通过OpenVINO™ 工具套件自带的人脸landmark模型实现了对人脸区域关键部位35个点位的预测标记,它就是典型的人脸landmark提取。在深度学习没有那么流行之前,传统的人脸landmark提取有两个让人吐槽的痛点:
■ 人脸的landmark中128个点位与68个点位提取是高耗时操作
■ 人脸landmark提取算法的抗干扰能力与普适性很差
自从深度学习方式在计算机视觉领域大显身手之后,人脸landmark算法通过卷积神经网络实现了稳定性与精准度双提升,现在已经是很多人脸相关应用的标配处理步骤。根据提取的人脸landmark点数的不同,最常见分为:
■ 5点提取 最简单人脸对齐
■ 35点提取 常见人脸对齐、人脸比对、人脸AR
■ 68点提取 场景适用人脸对齐、人脸比对、人脸AR等
■ 128点提取 场景适用人脸对齐、人脸比对、人脸AR等
■ 192点提取,场景适用人脸对齐、人脸比对、人脸AR、人脸3D重建
更多点位的人脸landmark提取这里就不再列出了。
300W是人脸landmark提取最常用的一个基准数据集,支持68个点位与51个点位的人脸landmark数据标注与训练。其中68个点位的landmark人脸标注位置信息如下:
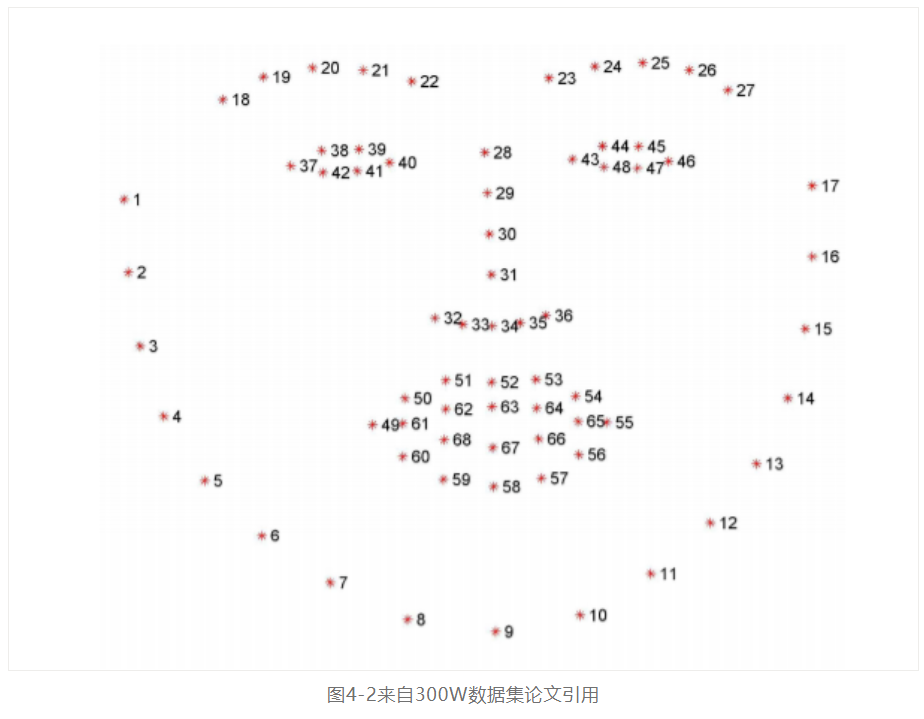
OpenVINO™ 工具套件模型库中有两个预训练landmark模型,分别支持人脸的5点与35点的landmark提取,这两个模型名称与输入输出格式如下:

4.2.2 人脸landmark模型使用
前面我们已经介绍了人脸landmark的基本概念与OpenVINO™ 工具套件模型库中的landmark模型,结合前面一节关于人脸检测的相关知识,这里我们首先通过人脸检测模型实现人脸ROI区域提取,然后针对人脸ROI区域实现landmark检测,实现一个简单人脸五官位置的定位检测。整个演示程序会使用两个深度学习模型,分别是人脸检测模型与landmark检测模型,从OpenVINO™ 工具套件模型库中选择如下:
■ 人脸检测模型-face-detection-0204
■ Landmark 检测35点-facial-landmarks-35-adas-0002
代码演示部分首先对输入视频帧或者图象,进行人脸检测,这部分内容前面一节已经详细交代过这里就不再赘述,我们主要解释如何加载landmark、设置输入输出、截取人脸ROI区域实现landmark检测与点位绘制,代码分为以下几个部分:
■ 加载landmark模型并设置输入输出
# 加载landmark模型并设置
landmark_net = ie.read_network(model=landmark_35_xml, weights=landmark_35_bin)
landmark_input_blob = next(iter(landmark_net.input_info))
landmark_out_blob = next(iter(landmark_net.outputs))
# 输入设置
pn, pc, ph, pw = landmark_net.input_info[landmark_input_blob].input_data.shape
# 设备关联推理创建
landmark_exec_net = ie.load_network(network=landmark_net, device_name="CPU")
■ landmark人脸关键点检测
完成模型加载与推理设置之后,就可以根据人脸检测的结果,截取对应的ROI区域,进行landmark关键点检测并绘制。截取人脸ROI区域并landmark检测的代码如下:
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
if xmin < 0:
xmin = 0
if ymin < 0:
ymin = 0
if xmax >= iw:
xmax = iw - 1
if ymax >= ih:
ymax = ih - 1
roi = src[ymin:ymax, xmin:xmax, :]
infer_landmark(roi, landmark_exec_net, landmark_input_blob, landmark_out_blob, pw, ph)
其中(xmin,ymin)与(xmax,ymax)是预测人脸ROI区域左上角与右下角坐标,检查越界之后,截取得到roi人脸区域,然后调用infer_landmark方法即可完成landmark检测与关键点绘制。其中infer_landmark方法的代码实现如下:
# 处理输入图象
rh, rw, rc = faceImg.shape
roi = cv.resize(faceImg, (pw, ph))
roi = roi.transpose(2, 0, 1)
# 推理
prob = landmark_exe_net.infer(inputs={input_name: [roi]})
landmarks = prob[output_name]
pts = np.reshape(landmarks, (-1, 2))
for pt in pts:
x1 = int(pt[0] * rw)
y1 = int(pt[1] * rh)
cv.circle(faceImg, (x1, y1), 3, (255, 0, 255), 2, 8, 0)
代码首先对人脸ROI图象进行预处理,然后执行模型推理,解析输出,绘制关键点。最终运行结果如下图所示:
需要解释一下的是这35点每个点位置信息可以参考图4-1获得,每个点对应的人脸五官位置,从而实现人脸五官位置的准确定位。

4.3 自定义landmark模型
前面两小节我们基于OpenVINO™ 工具套件模型库提供的人脸检测与landmark模型实现了人脸检测与landmark检测,从这些模型库的文档说明中我们也了解到它们有的是基于pytorch框架训练生成的。这里我们就是通过pytorch框架,设计一个自己的卷积神经网络,然后自己采集数据标注一个五点人脸landmark数据集,训练生成一个自定义的人脸5点landmark检测模型,并通过OpenVINO™ 工具套件进行部署。通过这样一个例子读者更加全面的了解pytorch与OpenVINO™ 工具套件联合开发的各个环节与技术技巧。
4.3.1 人脸landmark数据集制作
人脸数据集的制作,作者没有采用公开数据集来制作人脸,而是通过第一小节的人脸检测程序对输入的视频进行人脸检测并保存,完成了人脸数据采集工作,然后通过一个人脸5点的标注工具实现人脸数据的五点标注,该工具(Face-Annotation-Tool)的下载地址如下:
https://github.com/Mukosame/Face-Annotation-Tool
执行下面的命令行就可以运行该工具,开始数据标注:
python annotate_faces.py -d D:\facedb\image***r/>
其中参数-d表示人脸数据集所在的目录,软件界面显示如下:
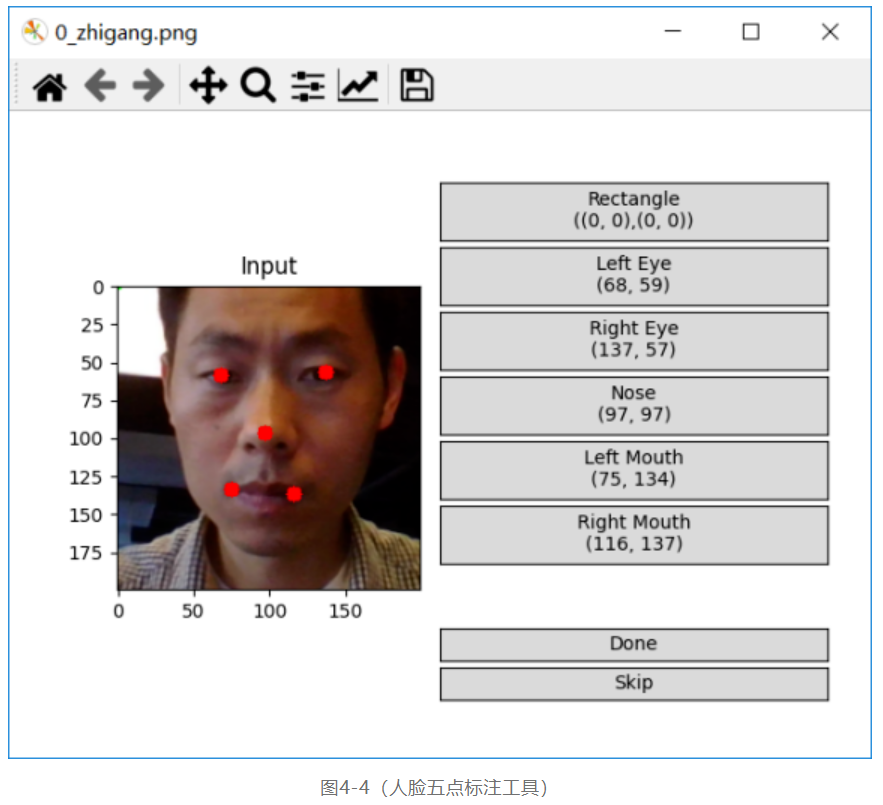
总计标注了1046张人脸5点landmark图象,最终所有的标注信息都会保存在一个txt文件中,每一行代表一张人脸图象的5点标注信息,格式如下:
[文件路径x1y1x2y2x3y3x4y4x5y5]
每一行第一个字符串是图象文件路径,后续十个数值是5点坐标信息,中间以tab键分隔。以此构建了自定义的Dataset数据类,其构建方式与第三章中自定义数据类似,唯一不同的是对getitem方法的实现,数据集的输入是图象,标签是5点的坐标的归一化值,自定义getitem方法的代码实现如下:
if torch.is_tensor(idx):
idx = idx.tolist()
contents = self.landmarks_frame[idx].split('\t')
image_path = contents[0]
img = cv.imread(image_path) # BGR order
h, w, c = img.shape
landmarks = np.zeros(10, dtype=np.float32)
for i in range(1, len(contents), 2):
landmarks[i - 1] = np.float32(contents[i]) / w
landmarks[i] = np.float32(contents[i + 1]) / h
landmarks = landmarks.astype('float32').reshape(-1, 2)
sample = {'image': self.transform(img), 'landmarks': torch.from_numpy(landmarks)}
return sample
最终通过上述代码预处理,输入图象为64x64大小,三通道彩色图象,通道顺序为BGR、坐标归一化到0~1之间的值。这样我们就完成了自定义的数据集制作与数据集类的实现,数据集与相关实现类代码可以参考书前言提到的地址下载并查看!
4.3.2 人脸5点landmark模型与实现
怎么设计一个卷积神经网络实现坐标点的回归预测,作者从OpenVINO™ 工具套件官方提供的一个基于卷积神经网络回归预测landmark的模型landmarks-regression-retail-0009文档中找到了线索。发现模型的主要结构是是基于stacked 3x3卷积、BN层、PReLU激活函数与池化层组成,最后的回归输出是基于全局深度池化操作。基于文档的理解,然后笔者就猜测了它的整个网络结构应该有三个关键部分,大致是这样:
■ 多个单应的Stacked CONV ->BN->PReLU->Pooling
■ 全局深度池化层
■ 全连接输出5点坐标
同时笔者注意到它最终的模型很小,又结合它的输入是64x64大小的图像,觉得栈卷积(Stacked CONV)应该是连续2~3卷积层,这点让人联想作者在设计的时候参考了VGG16~19的结构。然后最重要的是全局深度池化,我当时看到depthwise我就知道了,跟1x1卷积类似,但是它不会有参数计算,图示如下:
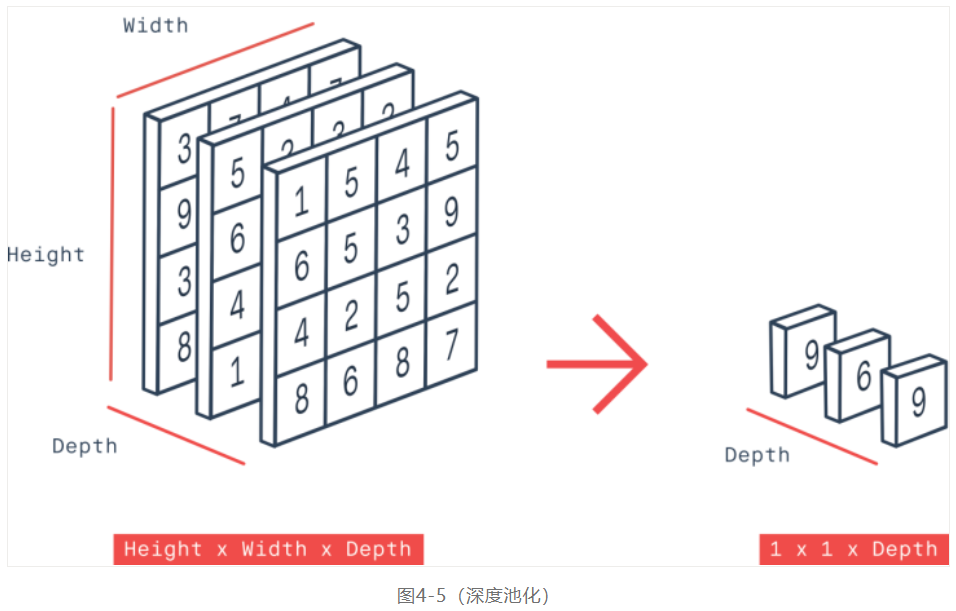
全局均值池化跟全局最大池化的输入为NxCxHxW,输出为NxCx1x1,但是全局深度池化的输出是Nx1xHxW,它是深度方向进行最大或者均值池化操作。Pytorch中没有专门的全局深度池化的函数,笔者的自定义实现如下:
class ChannelPool(torch.nn.MaxPool1d):
def __init__(self, channels, isize):
super(ChannelPool, self).__init__(channels)
self.kernel_size = channels
self.stride = isize
def forward(self, input):
n, c, w, h = input.size()
input = input.view(n,c,w*h).permute(0,2,1)
pooled = torch.nn.functional.max_pool1d(input, self.kernel_size, self.stride,
self.padding, self.dilation, self.ceil_mode,
self.return_indices)
_, _, c = pooled.size()
pooled = pooled.permute(0,2,1)
return pooled.view(n,c,w,h).view(n, w*h)
代码其实很容易理解,就是把每个通道看作是一维池化,然后合并结果,得到输出。完整了自定义的池化操作之后,就可以借助Pytorch中相关函数实现自定义的landmark卷积模型类,这部分的代码实现如下:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = torch.nn.Sequential(
# 卷积层 (64x64x3的图像)
torch.nn.Conv2d(3, 16, 3, padding=1),
torch.nn.Conv2d(16, 32, 3, padding=1),
torch.nn.BatchNorm2d(32),
torch.nn.PReLU(),
torch.nn.MaxPool2d(2, 2),
# 32x32x32
torch.nn.Conv2d(32, 64, 3, padding=1),
torch.nn.Conv2d(64, 64, 3, padding=1),
torch.nn.BatchNorm2d(64),
torch.nn.PReLU(),
torch.nn.MaxPool2d(2, 2),
# 64x64x16
torch.nn.Conv2d(64, 128, 3, padding=1),
torch.nn.Conv2d(128, 128, 3, padding=1),
torch.nn.BatchNorm2d(128),
torch.nn.PReLU(),
torch.nn.MaxPool2d(2, 2)
)
self.dw_max = ChannelPool(128, 8*8)
# linear layer (16*16 -> 10)
self.fc = torch.nn.Linear(64, 10)
def forward(self, x):
# stack convolution layers
x = self.cnn_layers(x)
# 16x16x128
# 深度最大池化层
out = self.dw_max(x)
# 全连接层
out = self.fc(out)
return out
其中self.cnn_layers是几个类似VGG16的卷积结构,然后再完成一个深度最大池化,全链接层输出指定的预测结果,模型的输入与输出结构如下:
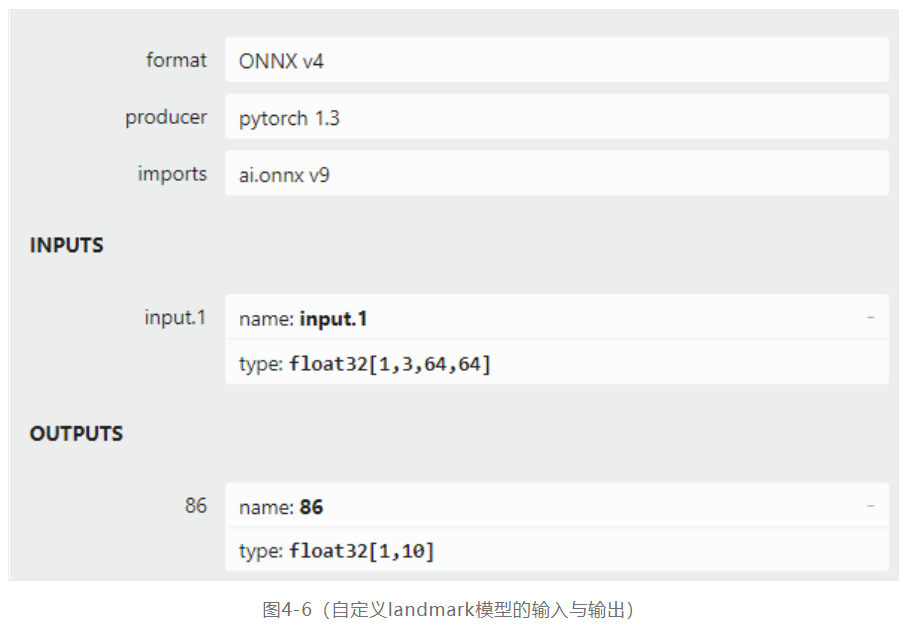
4.3.3 损失函数与训练
在第三章中,基于迁移学习训练图象分类模型的损失是基于交叉熵的损失,对应回归预测,常用的模型损失就是L1或者L2,人脸landmark模型训练的损失是典型的回归损失,这里作者借鉴了OpenVINO™ 工具套件官方模型landmarks-regression-retail-0009的损失公式:
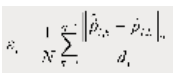
其中i表示第i个样本,N表示总的五个点,然后计算预测值跟真实值的L2,d表示真实值中两个眼睛之间的距离,作为归一化使用处理。损失函数实现的代码如下:
def myloss_fn(pred_y, target_y):
target_y = target_y.view(-1, 10)
sum = torch.zeros(len(target_y)).cuda()
for i in range(0, len(target_y)):
t_item = target_y[i]
p_item = pred_y[i]
dx = t_item[0] - t_item[2]
dy = t_item[1] - t_item[3]
id = torch.sqrt(dx*dx + dy*dy)
# N个点求
for t in range(0, len(t_item), 2):
dx = p_item[t] - t_item[t]
dy = p_item[t+1] - t_item[t+1]
dist = torch.sqrt(dx*dx + dy*dy)
sum[i] += (dist / id)
sum[i] = sum[i] / 5
return torch.sum(sum).cuda()
设计与实现了损失函数之后,其训练代码与第三章中的训练代码相似,这里训练50个epoch,然后保存模型文件,模型训练部分代码如下:
# 训练模型的次数
num_epochs = 50
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
model.train()
for epoch in range(num_epochs):
train_loss = 0.0
for i_batch, sample_batched in enumerate(dataloader):
image***atch, landmark***atch = \
sample_batched['image'], sample_batched['landmarks']
if train_on_gpu:
image***atch, landmark***atch = image***atch.cuda(), landmark***atch.cuda()
optimizer.zero_grad()
# forward pass: compute predicted output***y passing inputs to the model
output = model(image***atch)
# calculate the batch loss
los*****yloss_fn(output, landmark***atch)
# backward pass: compute gradient of the loss with respect to model parameters
los***ackward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training loss
train_loss += loss.item()
# 计算平均损失
train_loss = train_loss / num_train_samples
# 显示训练集与验证集的损失函数
print('Epoch: {} \tTraining Loss: {:.6f} '.format(epoch, train_loss))
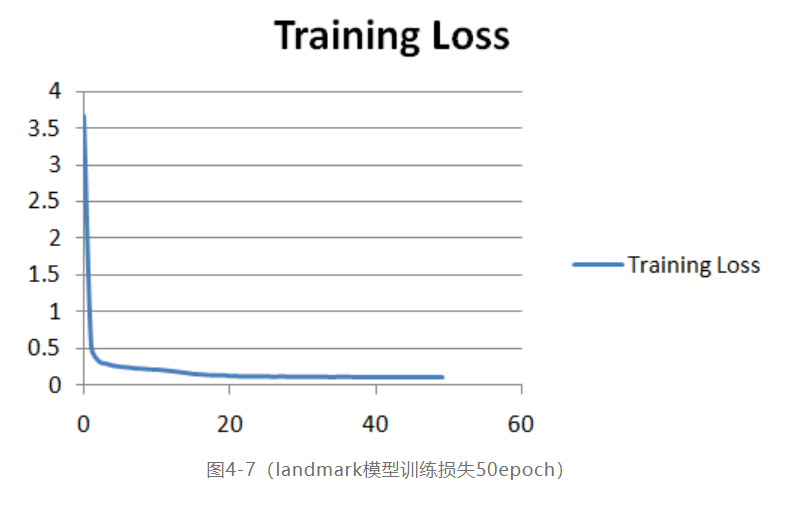
其中dataloader中设置batchSize大小为16。最终50个epoch之后的训练损失曲线如下:
前面已经完成了模型的训练与保存,现在可以通过测试数据验证一下我们训练出来模型是否可以正确的预测人脸的5点landmark。首先需要加载一张测试图象(图4-8左侧)然后完成图象预处理(可以参考数据集类)。最后加载模型输入图象并预测结果之后解析,这部分的代码如下:
x_input = torch.from_numpy(img).view(1, 3, 64, 64)
probs = cnn_model(x_input.cuda())
lm_pts = probs.view(5, 2).cpu().detach().numpy()
print(lm_pts)
for x, y in lm_pts:
x1 = x*w
y1 = y*h
cv.circle(image, (np.int32(x1), np.int32(y1)), 2, (0, 0, 255), 2, 8, 0)
其中cnn_model是通过torch.load加载的自定义训练5点landmark模型,img是预处理之后的图象,测试运行结果如下:
上面我们是直接调用pytorch的pt模型文件完成的模型测试,现在我们需要把部署到OpenVINO™ 工具套件支持的CPU平台上,获得CPU加速。首先需要做到第一步就是把原生的pytorch模型转换为onnx格式的模型,转化的脚本代码如下:

model = torch.load("./model_landmarks.pt")
model.eval()
model.cpu()
dummy_input1 = torch.randn(1, 3, 64, 64)
torch.onnx.export(model, (dummy_input1), "landmark_model.onnx", verbose=True)
细心的读者可能会发现这段转换脚本跟第三章中的转换脚本稍有差异,这是因为笔者在模型保存时选择了直接保存整个模型而不是dict模式,所以加载模型模型时直接使用load即可。转换完之后的onnx格式5点landmark模型大小只有1MB左右。使用第二节中的人脸与landmark检测代码,只需要改动对infer_landmark方法中的输入图象预处理部分,然后就可以完成推理与现实,改动之后的infer_landmark方法实现如下:
# 处理输入图象
rh, rw, rc = faceImg.shape
roi = cv.resize(faceImg, (pw, ph))
img = (np.float32(roi) / 255.0 - 0.5) / 0.5
roi = img.transpose(2, 0, 1)
# 推理
prob = landmark_exe_net.infer(inputs={input_name: [roi]})
landmarks = prob[output_name]
# 输出
pts = np.reshape(landmarks, (-1, 2))
for pt in pts:
x1 = int(pt[0] * rw)
y1 = int(pt[1] * rh)
cv.circle(faceImg, (x1, y1), 3, (255, 0, 255), 2, 8, 0)
上述代码的第一部分是预处理图象,转换为1x3x64x64的输入格式,同时转换为0~1之间的浮点数并减去均值0.5,除以方差0.5;然后执行推理,输出1x10的数组,转换为5x2的5点坐标数据,然后绘制每个坐标点。注意自定义5点landmark模型输出的坐标点值范围在0~1之间,需要乘以图象实际大小,才能转换为正确的屏幕坐标。
额外解释一下均值0.5与方差0.5是怎么来的,理论上均值与方差应该取整个数据集的均值与方差,这里作者在制作数据集与图象预处理的时并没有这么做,而是简单粗暴的取0.5作为均值与方差。这点请读者务必注意,实际制作数据集时多数会用计算得到数据集图象的均值与方差作为预处理的两个参数。
最终程序的运行结果如下:
图4-9的矩形框是人脸检测来自OpenVINO™ 工具套件的官方模型,五点分别对应眼睛、鼻子、嘴巴是笔者自定义并训练的5点landmark模型的测试效果。
本节是从数据集制作到模型训练、部署测试完整的一个案例,该案例通过自定义一个5点landmark模型帮助读者打通从pytorch训练到OpenVINO™ 工具套件模型部署之间的边界,实现一个轻量化模型从设计到训练、转换、推理的全过程。读者可以在此基础上进一步改善与提升模型预测精度。

4.4 人脸AR案例
大家见过很多图象与视频娱乐类的APP,这类APP中几乎都有人脸相关的AR效果,最简单的就是把各种装饰贴到人脸的五官指定的位置,而且十分的精准,看上去严丝合缝。这些人脸AR背后多数都跟人脸landmark提取与面部拟合有关系,从2D到3D的人脸landmark特征点检测与提取是关键技术之一。本节我们将通过一个简单的人脸佩戴眼睛AR案例来综合应用本章前面学习过的人脸检测与landmark检测内容,达到学以致用的目的。
这里我们通过帮助视频中的人脸自动戴口罩跟眼镜AR的案例演示来说明本章知识点的应用场景,提升读者对landmark检测应用场景的认知。案例实现一个自动人脸戴口罩AR功能,首先需要完成一个实时人脸检测,然后基于人脸区域完成landmark检测,这里我们选择35点位的OpenVINO™ 工具套件自带landmark检测模型,然后根据landmark检测得到结果,我们实现贴图层口罩与人脸相对位置的对齐,然后直接上资源图象。这里的资源图象是一张白色背景黑色口罩资料图,如下所示:

根据描述的思路,代码实现部分人脸检测与landmark检测这里就不再给出,不清楚的读者可以参见本章前面小节的内容学习,我们的重点放在如何贴合人脸位置与口罩起始位置的对齐,以及人眼中心位置与眼睛中心位置的贴合,只有贴合跟对齐了这两个位置,AR效果看上去才会比较真实一点。参考图4-1,我们知道人脸landmark检测模型facial-landmarks-35-adas-0002得到的35点位编号中对齐最好在18,34 这两个点对作为起始位置,最大高度点编号是26。因此我们只要把口罩的两边对应到18,34两个点上,然后高度最底边对应到26这个点位,这样就实现对资源图象根据人脸大小在水平与垂直两个方向放缩,根据放缩比率,对ROI区域直接贴图。最终的代码实现如下:
# 寻找点位
# 寻找点位
for idx, pt in enumerate(pts):
if idx == 18:
left_x = 0 # int(pt[0] * rw)
left_y = int(pt[1] * rh)
if idx == 34:
right_x = (rw - 1) # int(pt[0] * rw)
right_y = int(pt[1] * rh)
if idx == 26:
p26_x = int(pt[0] * rw)
p26_y = int(pt[1] * rh)
# 对齐与放缩
dx_t = right_x - left_x
dx_m = anchor_pts[2] - anchor_pts[0]
rate_x = dx_t / dx_m
rate_y = (p26_y - left_y) / (anchor_pts[3] - anchor_pts[1])
dst_mask = cv.resize(mask, (0, 0), fx=rate_x, fy=rate_y)
start_x = np.int(anchor_pts[0] * rate_x);
start_y = np.int(anchor_pts[1] * rate_y);
end_x = np.int(anchor_pts[2] * rate_x)
end_y = np.int(anchor_pts[3] * rate_y)
# 贴图
for row in range(end_y - start_y):
for col in range(end_x - start_x):
b2, g2, r2 = dst_mask[start_y+row, start_x+col]
if b2 < 127 and g2 < 127 and r2 < 127:
faceImg[row+left_y, left_x+col] = ( b2, g2, r2)
代码实现部分首先寻找到18、34、26三个landmark点位,然后对齐口罩资源图象,求得水平与垂直方向的放缩比率,完成对齐操作,最后遍历区域内像素完成贴图。代码运行的结果如下:

4.5 小结
本章是主要介绍了OpenVINO™ 工具套件中的人脸检测与landmark检测模型的的使用,以及如何通过pytorch实现自定义数据集的人脸landmark模型的设计、训练、部署。进一步帮助读者打通OpenVINO™ 工具套件与Pytorch之间的边界,实现从模型训练到模型部署的全过程。
通过本章内容读者可以学习到更多Pytorch深度学习方面关于卷积神经网络设计的知识,搞懂一些基础的网络结构,学习人脸landmark检测与应用,提升代码应用能力。
* 本文内容及配图均为“英特尔物联网”的原创内容。该公众号的运营主体拥有上述内容的著作权或相应许可。除在微信朋友圈分享之外,如未经该运营主体书面同意,请勿转载、转帖或以其他任何方式**、发表或发布上述内容。如需转载上述内容或其中任何部分,请留言联系。