PyTorch + OpenVINO™ 开发实战系列教程 第三篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
第3章 图象分类
通过前面两章的学习,我们已经了解Pytorch框架跟OpenVINO™ 工具套件框架的用途,并且搭建好了开发环境,为本章学习做好了准备工作。本章介绍计算机视觉的基础任务之一图象分类的基本概念、深度学习对图象分类任务的推进与影响,常用的图象分类网络,基准数据集。Pytorch框架自带的图象分类预训练模型库中模型、使用预训练模型实现图象分类、如何导出模型为ONNX格式,使用OpenVINO™ 工具套件完成推理部署。最后通过自定义数据,基于pytorch的模型库实现迁移学习,实现一个自定义数据集的图象分类,并导出模型为ONNX格式使用OpenVINO™ 工具套件完成部署。
本章内容有大量的代码演示环节,源代码也是本书内容的一部分,读者只有亲自动手才会理解与掌握相关的函数知识点,更好的理解本章内容。现在就让我们开启本章内容的学习……
3.1 图象分类概述
图象分类是计算机视觉基础任务之一,应用十分广泛,从手机中的图象自动分类、到各类数字图象归档、以图搜图的搜索引擎等应用中底层都依赖于图象分类算法,早期的图象分类算法都是手工提取特征数据,然后通过机器学习对特征数据分类从而实现图象分类,这类算法的缺点就是准确率比较低、很难在开放场景中大规模普及应用。直到2012年以AlexNet为代表的深度学习技术应用在图象分类中取得了良好的效果,大幅度提升了图象分类的准确性与稳定性。在随后的几年中不同的深度学习模型不断刷新图象分类基准数据集(ImageNet)准确率与稳定性,得益于底层算法的有力支持,图象分类应用也呈现一片繁荣。
3.1.1 图象分类概念
图象分类的目标是自动归类图象到已知的标签类别,从算法类型上看有两种图象分类技术分别是监督分类与无监督分类。正常的图象分类算法分为两步,第一步是训练、第二步是测试,其中训练就通过提取图象特征,然后完成基于特征数据的标签分类;测试是对训练生成的模型通过测试数据验证模型有效性;只有根据测试数据上取得的效果如何才能判别训练方法的正确与否。
在深度学习出现与大规模应用之前,图象分类的训练过程很难实现完成自动化,在特征提取中主要是通过手工特征提取方法实现,这些方法主要包括SIFT、HOG、以及它们组合构成BOW(词袋)等传统图象特征提取方法,然后再通过机器学习方法对特征数据进行分类,预测不同的标签,完成图象分类。基于的深度学习方法则完全颠覆了传统图象分类技术,它基于卷积神经网络(CNN)实现自动特征提取,大大突破了传统手工特征提取的限制,提取到了更加全面与有效的特征信息,然后再基于特征数据完成分类预测,整个训练过程不需要认为干预而且相比传统图象分类方法,CNN大幅提升图象分类准确率与稳定性。传统方法与CNN图象分类算法示意图如下:
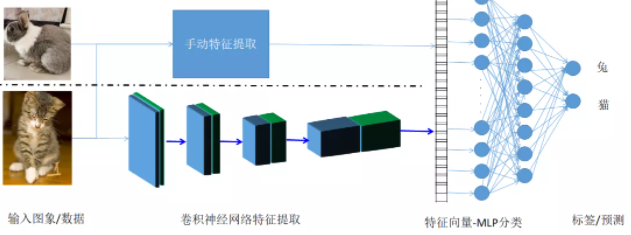
图3-1中展示了传统算法与深度学习算法实现图象分类不同的处理过程主要在于特征提取部分,传统算法采用手动特征提取,而且深度学习基于CNN网络完成特征提取,最终都得到一维特征向量作为输入,经过MLP(多层感知器/人工神经网络)预测分类,跟标签对比。如果预测结果跟标签差异较大则继续训练,直到预测结果跟标签接近(这个过程被称为训练收敛过程)。这样的到的模型可以在测试数据上进行测试,验证模型训练的效果。
3.1.2 ImageNet图象分类竞赛
深度学习推动了图象分类算法精度不断提升,在这个过程中也出现了多种经典的卷积神经网络模型,说到这些经典卷积神经网络模型就不得不说它们训练与测试的基准数据集。这些早期的经典模型都通过参加ImageNet图象分类竞赛表现出卓越的精度,为业界熟知获得高度关注。
这里不得不首先介绍一下ImageNet基准数据集,该数据集是在2009年正式发布提供给外界使用,同步发布的还有基于该数据集的一系列计算机视觉任务竞赛,这其中就包括了图象分类比赛。ImageNet数据集在2009年发布时图象总计有5247个不同类别总计超过320万张图片,后续两年数据集规模超过了500万张,至今ImageNet数据集仍然是计算机视觉领域最重要的基准数据集之一。
ImageNet相关的图象分类竞赛总计举办八届,图象分类预测的错误率(top-5)也从最初2009你那开始的28.2%逐年下降,2017年更是达到惊人的2.25%错误率。竞赛已经完全达到了最初设立提升图象分类准确率的目标,而且远超人类的5%的上限值,再也没有继续举办下去的必要的。ImageNet图象分类竞赛与历年的冠军模型预测错误率图示如下:
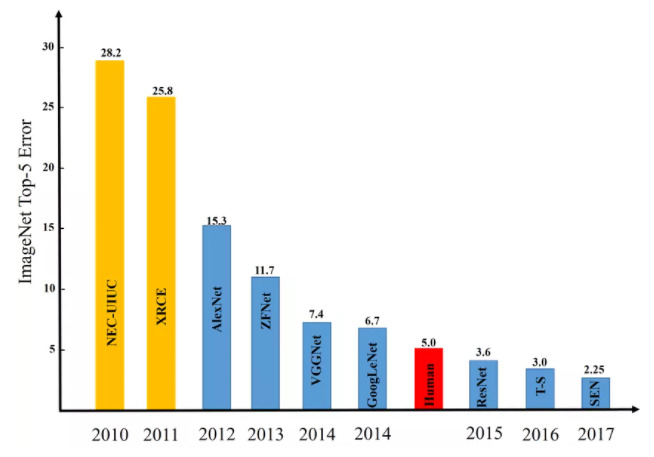
图3-2中Human 5%表示人类的认知水平,图象分类预测top-5错误率在5%,2015年以前的模型都没有超过人类的认知水平、而2015年极其之后的模型都已经远超人类的认知水平。
3.1.3 图象分类模型
ImageNet图象分类竞赛产生了很多经典的模型,这些模型背后是一些典型的模型设计思想,其中两个最常用的经典模型系列是VGG模型系列与ResNet模型系列。
· VGG系列模型
VGG系列模型是2014年ImageNet图象分类竞赛表现杰出的模型之一,它在模型设计跟模型深度方面较2014年之前的模型都有创新,特别是大量改用3x3卷积,有效减少了模型参数与计算量,从而网络权重层数比之前的模型更多,在当年也取得了良好的效果。VGG系列根据权重层数目的不同可以分为VGG11 ~VGG19,作为主干网络常被采用的是VGG16与VGG19两个模型,VGG系列网络的权重层数与结构如下图:
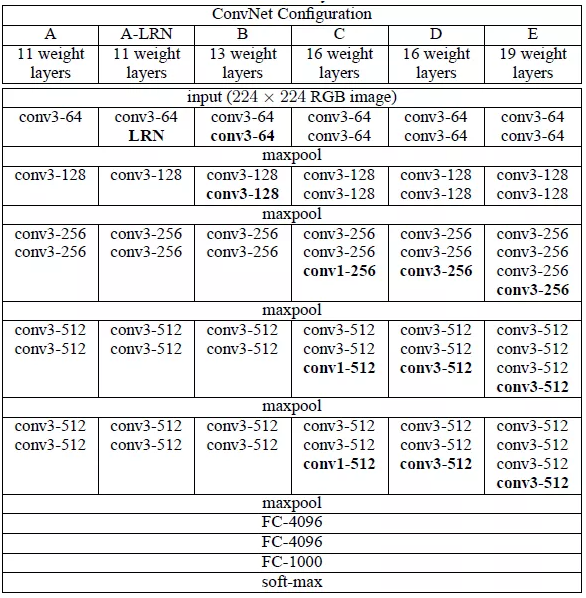
图3-3中conv3表示卷积3x3、conv1表示卷积1x1、conv3-512表示输出通道512个,其它依此类推,FC-4096表示全链接层4096个神经元节点。
· ResNet系列模型
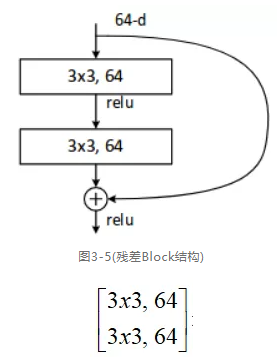
ResNet系列模型是ImageNet图象分类竞赛后期出现的重要基础模型之一,它的残差结构设计思想至今仍然可以从很多新出现的模型中找到踪迹。此外ResNet产生的一系列变种卷积神经网络不仅在图象分类中精度提升明显,还在其它视觉任务中也表现良好。ResNet系列网络图示如下:
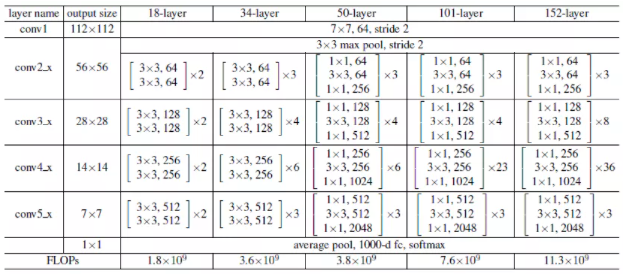
图3-4中18-layers表示权重层(参数计算)数目、FLOPs表示每列对应模型的浮点数计算量、ResNet-18表示18个权重层数目的残差网络模型的简写、
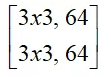
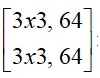
其它常见的基础模型还包括InceptionV2系列模型、MobileNet系列模型、EfficientNet系列模型、DenseNet、ResNext等,感兴趣的读者可以自己阅读相关资料进一步拓展。
3.2 Pytorch图象分类模型使用
通过前面一节内容我们已经了解图象分类的基本概念,常用模型与基准数据集。本节我们将使用Pytorch框架中基于ImageNet数据集的预训练模型库中的模型,来完成图象分类的代码演示,同时学习如何使用Pytorch预训练模型库中的图像分类模型。
Pytorch中torchvision组件下的models包含大多数当前常用的基于ImageNet数据集训练的图象分类模型,这些模型主要包括:
AlexNet
VGG
ResNet
SqueezeNet
DenseNet
Inception v3
GoogLeNet
ShuffleNet v2
MobileNetV2
MobileNetV3
ResNeXt
Wide ResNet
MNASNet
在Pytorch中引用上述列表模型并初始化的代码如下:
import torchvision.models a***odel***r>
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
shufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet_v2 = model***obilenet_v2(pretrained=True)
mobilenet_v3_large = model***obilenet_v3_large(pretrained=True)
mobilenet_v3_**all = model***obilenet_v3_**all(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = model***nasnet1_0(pretrained=True)其中第一行代码是导入模型库支持,剩下的代码则是分别初始化各个预训练模型、其中pretrained=True表示加载该模型的预训练版本。当你在Pycharm中第一次执行上述代码时候,你会发现它运行非常慢,原因是第一次执行它会把模型下载本地,这个是一个绝对耗时的过程,需要一点时间等待。一旦完成模型加载,就可以通过读入一张图象,然后进行预处理之后,作为输入调用模型推理实现图象类别预测。以ResNet18为例,完整代码演示分为如下几个部分:
· 模型加载
Torchvision.models包含了ResNet系列模型,这里我们以ResNet18模型为例,首先需要完成模型库导入与加载初始化,代码如下:
import torchvision.models a***odel***r>
res18 = models.resnet18(pretrained=True)
print(res18) # 打印模型结构上述代码实现了模型加载并通过print功能打印模型模型结构,可以很清楚的对应上图3-4所示的模型结构说明,感兴趣的读者可以自行对照验证。
· 图象预处理
在加载ResNet18模型之后,还需要准备测试图象,完成对测试图象的预处理,才可以作为输入张量数据给模型,然后推理预测分类。所以输入图象预处理非常重要,测试图象预处理必须遵循跟训练图象数据集预处理保持一致原则。ResNet18模型的输入要求如下:
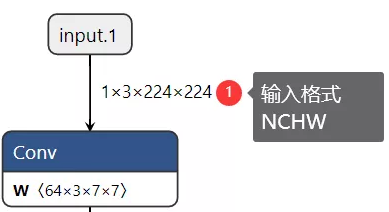
图3-6中输入格式NCHW中N表示图象数目、C表示每张图象的通道数目、H跟W分别表示图象的宽与高。NCHW=1x3x244x244表示输入图象是三通道的大小为224x244,这里需要注意的是torchvision模型库中的预训练模型在训练时候输入图象数据集的通道顺序都是RGB顺序,而OpenCV读入图象默认顺序是RGB,所以需要转换为RGB;此外输入图象数据值被归一化到0~1之间,而且被均值与方差归一化处理,这些必须都要在图象预处理中完成,完成之后转换为NCHW格式输入数据。图象预处理部分的演示代码如下:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
transforms.Resize((224, 224))
])
image = cv.imread("D:/images/flowers.jpg") # space_shuttle.jpg
rgb = cv.cvtColor(image, cv.COLOR_BGR2RGB)
input_x = transform(rgb)
input_x = input_x.view(-1,3,224,224)其中transforms来自第一章中介绍过的torchvision的组件,它是pytorch中图象预处理的神器,低版本只接受来自PIL库读入的图象数据,pytorch1.7以上版本支持直接读取OpenCV图象作为输入数据。toTensor()函数会把图象数据从字节类型转换为0~1之间的浮点数张量、Normalize表示归一化,三个通道减去[0.485, 0.456, 0.406]对应均值,然后除以[0.229, 0.224, 0.225]对应方差;注意这里均值跟方差都是基于整个数据集计算生成的。最后Resize到指定的224x224大小。
· 推理预测
首先检测是否支持GPU运行,如果支持则转换为GPU数据,然后运行,否则CPU运行推理。推理完成以后会得到预测结果,我们使用top-5的模式来显示预测结果,通过OpenCV绘制文本显示预测结果到图象上。这部分的演示代码如下:
# 推理预测
if torch.cuda.is_available():
model = res18.eval().cuda()
pred = model(input_x.cuda())
pred_top5 = torch.topk(pred, 5, 1).indices.cpu().detach().numpy().reshape(5)
else:
model = res18.eval()
pred = model(input_x)
pred_top5 = torch.topk(pred, 5, 1).indices.detach().numpy().reshape(5)
print("top predict class name : %s"%labels[pred_top5[0]])
pred_txt = ""
for i in range(len(pred_top5)):
pred_txt = str(i + 1) + ". " + labels[pred_top5[i]]
cv.putText(image, pred_txt, (20, 30+i*30), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)在推理开始之前,对加载的模型首先要执行eval()操作,然后才可以使用,eval()操作是针对模型推理的调整,目的是保证推理输出结果的一致性。得到预测结果pred,它的显示格式如下:
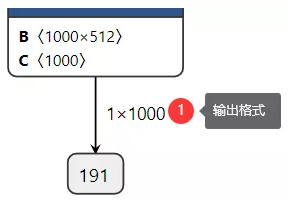
ImageNet数据集是支持1000个类别分类的图象数据集,所以输出格式为Nx1000=1x1000,其中N=1表示图象数目。使用topk函数获取前五个最可能预测类别,然后根据索引转换为对应标签文字,运行结果如下:

图3-8中显示的是top-5的预测结果(top-5准确率意思是预测五个结果有一个是正确结果)
3.3 迁移学习介绍
深度学习在训练环节严重依赖大规模数据集与硬件计算能力,很多知名的业界模型只有顶级人工智能公司有资金购买算力资源跟数据资源支持,实现从零开始的模型训练。对大多数中小型的人工智能公司来说训练超大规模的模型是一件极其困难的事情,这个困难不是技术困难,而是没有足够的资金持续支持模型训练与开发,顶层的人工智能公司资金雄厚,通用开发模型垄断的通用应用场景,在细分领域确少足够数据跟资金的中小型人工智能公司的出路在哪里?答案就是迁移学习。
3.3.1 迁移学习概念
古语有云:“青,取之于蓝,而胜于蓝;冰,水为之,而寒于水”意思是说学习者是可以达到或者超过被学习的对象,前提是基于相似的素材。迁移学习的思想跟这句古语非常接近,当我们想用一个模型,但是有受限于数据集样本数目,计算能力的限制,无法重零开始训练一个模型时,只要有一个超大规模数据集上训练好的模型,在这个模型的基础上,利用我们有限的数据跟算力,复用跟微调模型权重参数,进行有限条件的训练模型,从而在自定义的数据集上面让模型达到或者超过之前的预测精度,这个就是迁移学习。标准模型训练与迁移学习之间的对比如下:
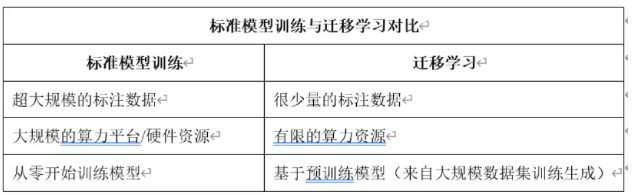
迁移学习不是深度学习之后才有的概念,它是机器学习的分支研究领域之一,从不同的维度跟层次可以分为不同方式的迁移学习,这里我们主要关注的是基于深度学习模型的迁移学习。
迁移学习在计算机视觉领域的应用十分广泛,从图象分类、风格迁移、对象检测、语义分割等视觉任务中都会用到,而且效果良好。针对卷积神经网络不同任务的模型,迁移学习以基于MS-COCO/ImageNet等大规模数据集训练生成的模型为基础,通过采集少量的自定义数据集并标注,使用有限的计算资源进行训练,得到模型在大规模数据集上训练之后相同或者相近的测试精度与稳定性要求。在Pytorch深度学习框架中,torchvison是计算机视觉的迁移学习框架,支持对象检测、图象分类、语义分割等模型的迁移学习。
3.3.2 特征迁移方式
这里的迁移学习方式主要是针对计算机视觉领域的卷积神经网络模型来说,它的迁移学习方式可以分为两种,第一种方式冻结大多数卷积层,只训练微调最后几层;第二种方式则是全部权重层都参与训练,整个模型的参数微调训练。下图是深度神经网络迁移学习方式对比:
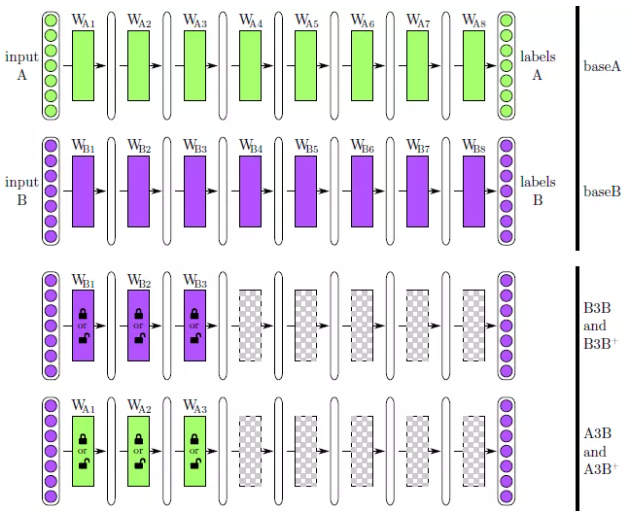
作者把ImageNet数据集分为两部分dataA与DataB,分别对应baseA与baseB两个单独的模型,然后训练得到结果;第三行是采用模型baseB,前三层冻结参数不变后续层随机初始化参数训练,使用dataB训练得到B3B;然后对前三层也不冻结参与微调,后续层随机初始化得到B3B+;第四行则采用模型baseA,然后采取冻结前三层与前三层微调,后续层随机初始化使用训练数据dataB训练分别得到A3B与A3B+。它们实验准确率对比结果如下:
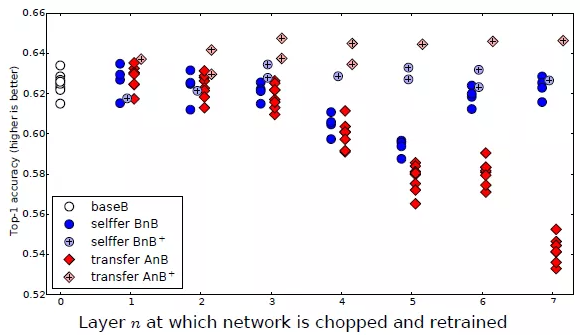
图3-10中可以看到采用全链路参数微调的AnB+不管n等于几,它的结果总是很好,在同等条件下,冻结的层数越多,迁移学习效果越差,参见AnB模型准确率。上述实验有力的说明深度神经网络模型的特征可以在不同数据集上迁移,通过微调达到更好的效果。
3.4 自定义图象分类
本节我们将在pytorch框架中使用迁移学习实现自定义图象数据分类,同时对训练之后保存的模型转换为OpenVINO™ 工具套件的IR格式,实现CPU部署与推理,完成自定义图象分类训练与部署全过程,迈出实战化学习的第一步。
3.4.1 数据集说明与使用
作者选择了一个公开的迁移学习数据集flower_photos,是一个花卉图像分类数据集,包含五个分类标签表示五种不同的花卉,分别是雏菊、蒲公英、玫瑰、向日葵、郁金香,总计包含2934张训练图象,736张测试图象,图象格式均为JPG格式。五种类别花卉图示如下:

在Pytorch中制作数据集主要是通过torch.utils.data.Dataset这个类来完成,实现一个自定义的数据集类。这个其中最重要的做好图像的预处理,要把图象处理成为224x224x3 大小的彩色图像,RGB顺序,值在0~1之间的tensor数据,这样就跟Pytroch的ResNet18预训练模型的预处理的输入格式要求一致了。
· 自定义Dataset类
在Pytorch中官方提供的数据集都已经封装好了Dataset类,比如MNIST数据集、FashionMNIST数据集等。其它的非官方提供的,特别是开发者自己制作的数据集,都需要通过集成Dataset类,实现它的三个方法:
__init__ # 初始化数据集样本
__len__ # 数据集样本数目
__getitem__ # 获取数据集中的每个标注样本其中__init__是初始化方法,只是在创建自定义数据集实例时候运行一次,一般是根据路径加载数据集,定义数据预处理流程等操作。__getitem__方法是根据索引返回数据集中对应的样本、对图象来说,它会完成图象预处理,转换为tensor,返回图象的tensor数据与对应的标注信息(分类标签)。花卉数据集的自定义Dataset类如下:
class FlowerDataset(Dataset):
def __init__(self, root_dir):
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img_dirs = os.listdir(root_dir)
self.label********r>
self.image********r>
index = 0
for label_name in img_dirs:
img_dir = os.path.join(root_dir, label_name)
img_files = os.listdir(img_dir)
for file in img_files:
img_path = os.path.join(img_dir, file)
self.images.append(img_path)
self.labels.append(np.int32(index))
index += 1
def __len__(self):
return len(self.image****r>
def num_of_samples(self):
return len(self.image****r>
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
image_path = self.images[idx]
else:
image_path = self.images[idx]
img = cv.imread(image_path) # BGR order
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
sample = {'image': self.transform(img), 'flower': self.labels[idx]}
return sample需要注意的是在__init__中的变量self.transform是一个组合变换操作,第一步转换为tensor跟后续操作顺序绝对不能调换,否则你会遇到如下错误:
raise TypeError('img should be PIL Image. Got {}'.format(type(img)))
TypeError: img should be PIL Image. Got原因是因为早期的pytorch中transforms图象预处理包接受的输入图象类型是PIL格式的,不支持OpenCV的numpy数据格式数据,但是transforms中的toTensor支持把Numpy数据转换为tensor变量,而transforms中所有的操作都支持tensor数据,所以在数据集中当使用OpenCV读取图象时候必须把toTensor放在第一个操作。自定义数据集类的代码基本结构在本书的后续章节中会反复用到,请读者熟悉并理解上述代码。
· 数据集加载
自定义数据集完成之后,可以通过DataLoader类完成数据集的加载,DataLoader有两个最重要的参数分别是batchSize参数与shuffle参数,batchSize=64表示迭代每次输出64个样本数据,shuffle=True表示对原有数据打乱顺序输出。使用DataLoader加速自定义的花卉数据集并迭代输出样本的代码演示如下:
dataloader = DataLoader(d****atch_size=4, shuffle=True)
# data loader
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(), sample_batched['flower'])运行结果(部分截图)如下:

3.4.2 模型构建
这里笔者选择ResNet系列模型来构建迁移学习模型,首先需要把模型的全链接层的最后的输入从预测ImageNet的1000个类别改为我们自定义数据指定的类别数目5。当采用全链路参数微调时,模型的构建的代码如下:
self.cnn_layers = torchvision.models.resnet18(pretrained=True)
num_ftrs = self.cnn_layers.fc.in_feature***r>
self.cnn_layers.fc = torch.nn.Linear(num_ftrs, 5)当采用冻结全部卷积层参数的方式迁移学习时,模型构建的代码如下:
self.cnn_layers = torchvision.models.resnet18(pretrained=True)
for param in self.cnn_layers.parameters():
param.requires_grad = False
num_ftrs = self.cnn_layers.fc.in_feature***r>
self.cnn_layers.fc = torch.nn.Linear(num_ftrs, 5)这样就完成模型的构建,这部分的完整源代码参考flower_cnn.py这个python源代码文件,这里就不再贴出全部源码。
3.4.3 模型训练
前面已经准备好了训练数据,构建了数据集类与模型类的代码,为模型训练做好了一切准备,指定训练批次参数为4,训练epoch为15,选择交叉熵损失函数与Adam优化器,这部分的代码如下:
bs = 4
dataloader = DataLoader(d****atch_size=bs, shuffle=True)
# 训练模型的次数
num_epochs = 15
# optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
model.train()
# 损失函数
cross_loss = torch.nn.CrossEntropyLoss()关于DataLoader中设置批次参数时需要注意整个训练集数据的多少,数据集数据最好是能被批次整除的,这样最后一个批次就不会出现数据不足。当出现最后一个批次数据不足时,DataLoader类支持通过参数drop_last来决定是否丢掉,默认是不丢掉。然后就可以根据设置epoch开始训练模型,代码如下:
for epoch in range(num_epochs):
train_loss = 0.0
for i_batch, sample_batched in enumerate(dataloader):
image***atch, label_batch = \
sample_batched['image'], sample_batched['flower']
if train_on_gpu:
image***atch, label_batch= image***atch.cuda(), label_batch.cuda()
optimizer.zero_grad()
# forward pass: compute predicted output***y passing inputs to the model
m_label_out_ = model(image***atch)
label_batch = label_batch.long()
# calculate the batch los***r>
loss = cross_los***_label_out_, label_batch)
# backward pass: compute gradient of the loss with respect to model parameter***r>
los***ackward()
# perform a single optimization step (parameter update)
optimizer.step()
# update training los***r>
train_loss += loss.item()
if index % 100 == 0:
print('step: {} \tTraining Loss: {:.6f} '.format(index, loss.item()))
index += 1
# 计算平均损失
train_loss = train_loss / num_train_sample***r>
# 显示训练集与验证集的损失函数
print('Epoch: {} \tTraining Loss: {:.6f} '.format(epoch, train_loss))上述代码在训练过程中,整个数据集循环一次叫做一个epoch,数据集中每次完成一个批次训练就会计算损失,更新模型参数。完成指定的epoch数目之后,就可以保存模型,Pytorch中保存模型有两种典型不同方式,一种方式是保存检查点,目的是方便以后继续训练,可以直接从检查点恢复参数开始训练,这样可以大大节省后续训练的时间与精力;另外一种方式保存为字典形式的Python串行化字节,方便后续模型推理使用。这两种方式分别的分别说明与代码演示如下:
· 保存与加载检查点模式
保存加持点代码如下:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': los****r>
...
}, PATH)其中PATH表示的是保存路径。加载检查点的代码示例如下:
model = YourModelClass(*args, **kwarg****r>
optimizer = TheOptimizerClass(*args, **kwarg****r>
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']然后设置模型为训练模式就可以从检查点继续训练。
· 保存与加载推理模式
保存代码如下:
torch.save(model.state_dict(), PATH)加载代码如下:
model = YourModelClass(*args, **kwarg****r>
model.load_state_dict(torch.load(PATH))
model.eval()注意:在加载之后必须调用模型的eval()方法设置dropout层与BN层参数为推理模式,然后才可以使用模型去推理,否则很可能导致模型训练与推理运行结果不一致
3.4.4 模型部署
前面已经完成了迁移学习图象分类模型的训练与模型保存,现在我们需要使用模型来进行预测,这个过程我们称为模型推理。一个训练好的模型是既可以使用原来训练的深度学习框架来部署,也可以使用第三方模型部署框架进行部署。这里我们将分别演示Pytroch原生推理与OpenVINO™ 工具套件转换推理部署两种方式。
· Pytorch依赖的推理部署
首先需要加载训练好的模型,然后加载测试图象,对测试图象进行预处理,预处理的方式必须与训练时对图象数据集的处理方式一致。这里需要注意的时候加载模型之后必须先eval()才可以后续使用,加载模型的代码如下:
cnn_model = FlowerClassificationModel()
cnn_model.load_state_dict(torch.load("./flower_model.pt"))
cnn_model.eval()
cnn_model.cuda()然后遍历测试图象进行测试,并显示测试结果,代码如下:
image = cv.imread(os.path.join(root_dir, f))
image = cv.cvtColor(image, cv.COLOR_BGR2RGB)
x_input = img_transform(image).view(1, 3, 224, 224)
probs = cnn_model(x_input.cuda())
predic_ = probs.view(5).cpu().detach().numpy()
idx = np.argmax(predic_)
defect_txt = flower_labels[idx]
print(defect_txt, f)
cv.putText(image, defect_txt, (10, 30), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2, 8)
cv.imshow("flower-demo", image)
cv.waitKey(0)运行结果如下:

· OpenVINO™ 工具套件的推理部署
OpenVINO™ 工具套件支持ResNet系列的图象分类模型部署,当前OpenVINO™ 工具套件只支持两种模型格式文件的读取与加载,一种是基于IR格式(.xml与.bin);另外一种基于开放神经网络交换格式(Open Neural Network Exchange简称ONNX)。Pytorch训练的模型可以很方便的通过几行代码转换为ONNX格式,然后就可以脱离pytorch依赖,直接使用OpenVINO™ 工具套件进行部署并推理。将上面迁移学习训练生成的模型转换为ONNX格式的代码如下:
model = FlowerClassificationModel()
model.load_state_dict(torch.load("flower_model.pt"))
model.eval()
model.cpu()
dummy_input1 = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, (dummy_input1), "flower_model.onnx", verbose=True)转换为ONNX格式的模型文件,可以通过OpenVINO™ 工具套件的相关函数直接加载,加载ONNX格式文件并设置输入与输出格式代码如下:
flower_net = ie.read_network(model="flower_model.onnx")
em_input_blob = next(iter(flower_net.input_info))
em_it = iter(flower_net.output****r>
em_out_blob1 = next(em_it)
en, ec, eh, ew = flower_net.input_info[em_input_blob].input_data.shape
print(en, ec, eh, ew)上面的代码中en、ec、eh、ew表示输入图象的数目、通道、高度、宽度,可以简化表示为NCHW=[1x3x224x224]。输出是1x5的二维数据,其中1表示输出图象数目,5表示分类数目,这里花卉是5个类别。然后就可以使用模型进行推理,并解析输出结果,这部分的代码实现如下:
src = cv.imread(img_path)
img = cv.resize(src, (224, 224))
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
blob_img = np.float32(img) / 255.0
input_x = (blob_img - means) / dev
input_x = input_x.transpose((2, 0, 1))
print(input_x.shape)
_res = exec_net.infer(inputs={em_input_blob: [input_x]})
_prob = _res[em_out_blob1] # 1x5
label_index = np.int(np.argmax(_prob, 1))
cv.putText(src, flower_labels[label_index], (50, 50), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 255, 0), 2)
cv.imshow("input", src)
cv.waitKey(0)其中224表示图象大小、除以255是为了归一化到0~1之间。运行预测结果如下:

完整的演示代码读者可以自行下载运行。
本小节把训练生成的模型分别在依赖pytorch框架下运行与导出ONNX格式无pytorch依赖直接通过OpenVINO™ 工具套件部署CPU推理预测,演示了pytorch图象分类模型的不同部署方法。
3.5 小结
本章通过图象分类得概念介绍、支持的常用模型与数据集介绍,了解了图象分类的历史与发展,当前Pytorch中支持的图象分类模型,迁移学习的概念等相关知识。通过一个图象分类的示例代码演示了使用pytorch预训练模型进行图象分类预测,同时完成了基于迁移学习实现自定义图象分类模型的数据处理、训练、部署全流程的代码演示,帮助读者掌握pytorch框架下如何快速完成自定义图象分类模型的训练与部署。