OpenVINO™ 模型转换技术要点解读
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
概述
OpenVINO™ 是由Intel推出的用于深度学习推理加速的开源工具集,具有跨平台、高性能的特点。模型转换技术,是通过OpenVINO™工具集中的模型优化器(Model Optimizer,简称 MO,以下提到的MO均指代模型优化器)将预训练好的模型进行格式转换以及拓扑优化的技术。经过模型转换的神经网络模型,可以在实际的部署阶段获得更优异的性能加速比以及更为通用的跨平台特性。
本文首先会简单回顾模型优化器的作用以及其重要性,然后结合实际案例,讲解模型转换技术的知识要点以及常见问题。
1. 模型转换的作用
使用 OpenVINO™ 进行应用优化的工作流如下:
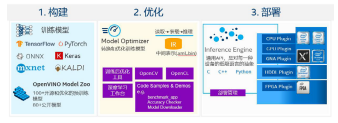
图 1 OpenVINO™ 的工作流程
如图 1 所示,首先,开发者需要基于开源的深度学习框架如Tensorflow, PyTorch 等构建并训练自己的神经网络模型,生成预训练模型;然后,通过 OpenVINO™ 中的 MO,将预训练模型转换成 IR(Intermediate Representation)文件,即中间表示文件。最后,通过 OpenVINO™ 中的推理引擎 (Inference Engine)读取 IR 文件,并根据当前实际的部署设备,调用对应设备的插件,如 GPU 插件、iGPU 插件(此处 iGPU 指集成显卡)等完成推理的调用及优化,输出最终的推理结果。不难看出,环节二是 OpenVINO™ 部署的第一步,也是后续推理操作的基础,因此掌握模型转换技术对于广大开发者尤为重要。
MO 的作用包括模型模式转换和拓扑优化,此外也支持对模型进行从 FP32 到 FP16 的量化。
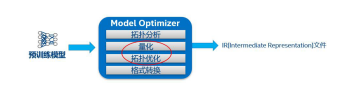
图 2 通过 MO 提升推理性能
如图 2 所示,MO 完整的工作流程包括:首先对预训练模型进行拓扑分析,然后判断是否需要进行低精底量化,接着执行拓扑优化,最后进行格式转换。其中拓扑优化的原理主要是基于数学运算,去除模型中的冗余部分;此外,有些拓扑只会在训练阶段用到,推理时并不会用到,也会将这些拓扑摘除。如果想进一步了解 MO 优化的原理,请参考官方文档:https://docs.openvino.ai/latest/openvino_docs_MO_DG_Default_Model_Optimizer_Optimizations.html。2. 模型转换的重要性
MO属于很重要同时也是极易出现问题的环节,笔者对OpenVINO™官方 github 上的 issue(https://github.com/openvinotoolkit/openvino/issues)进行了简单的统计,如下表所示: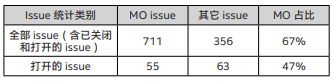
表 1 OpenVINO™ issue 统计结果
由此可见,在整个 OpenVINO™ 的开发过程中,MO 是个难点,很容易遇到问题,尤其是对于刚接触 OpenVINO™ 的开发者,上手不太容易。
OpenVINO™ 的产品团队也意识到这个问题,因此陆续推出了帮助开发者跳过 MO 这一步骤的方法,比如推理引擎直接读取
onnx 格式,但是模型转换仍然具有其不可替代性,现阶段仍然需要开发者花时间去研究掌握:
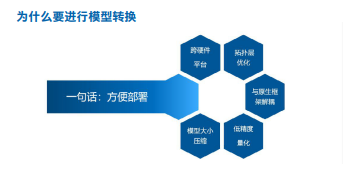
图 3 模型转换的必要性
如图 3 所示,模型转换的必要性可以总结为 5 点:
● 跨硬件平台
统一的IR格式可以确保模型运行在不同架构的硬件平台上,
并且方便统一管理和调试。
● 拓扑层优化
MO 会对模型拓扑进行优化,从而减少模型大小和降低模型
复杂度。
● 与原生框架解耦
IR 格式独立于原生框架,部署工程师不需要了解原生框架的
细节,降低学习成本。
● 低精度量化
OpenVINO™ 自带的低精度量化工具仅支持对 IR 格式的模型
进行低精度量化。
● 模型大小压缩
OpenVINO™ 自带的压缩工具仅支持对 IR 格式的模型进行压缩,同时 OpenVINO™ 中自带的其它工具,比如 dl workbench
(https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Introduction.html),也只支持针对 IR 格式的操作。
综上,模型转换技术是一门非常重要的技术,并且具有一定的上手门槛,值得我们花时间精力来好好的掌握。
3. 模型转换案例解析
笔者总结了一下,模型转换中的常见问题可以大致归纳为以下几类:● 转换参数太多,不熟悉每个参数的作用,不知道该怎样指定MO 参数。
● 遇到问题不知道去哪里找资料,没有解决思路。
● 转换虽然成功,但在推理时结果不正确,无法定位问题在哪里。
● 模型中存在自定义算子,MO 不支持。
下面将通过实际的案例,给大家一一讲解对应的解决方法。
案例一:合理的利用模型转换参数
问题描述:某目标检测模型如图 4 所示含有两个输入,且输入层张量的维度中带有?号。其中 Placeholder 的 layout 为 N,H,W,C,shape 是动态的;Placeholder_1 的 shape 是固定的,但值需要锁定为 [H,W,N]。使用 MO 转换且不设置任何 MO 参数的情况下,转换失败。
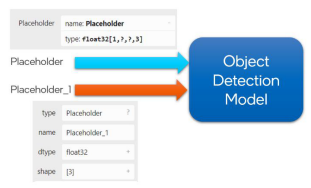
图 4 目标检测模型示意图
需要解决的问题:
1) MO 是否支持维度中带有 ? 号
2) 两个输入如何指定 MO 参数?
解决方法:
通过查阅官方文档:https://docs.openvino.ai/latest/openvino
docs_MO_DG_prepare_model_convert_model_
Converting_Model.html,可得知上述两个问题的答案:

图 5 input_shape 参数说明
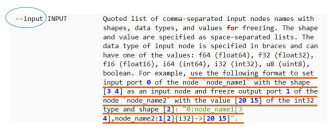
图 6 input 参数说明
针对问题 1),通过图 5 得知,MO 不支持 shape 中含有 ?,如果含有 ? 或 -1,需要通过指定参数将 shape 锁定为固定值。
针对问题 2),通过图 6 得知,如果需要锁定输入参数的值,可以通过指定 input 参数实现,具体到本例中,Placeholder_1需要锁定为 [H,W,N]。假设 batch 设为 1,H 设为 600,W 设为 600,则 Placeholder 需要将 shape 固定为 (1,600,600,3),而 Placeholder_1 需要将值锁定为 [600,600,1]。
因此本例中 MO 转换时,需要添加如下关键参数:--input "Placeholder [1 600 600 3], Placeholder_1[3]->[600 600 1]" 即可完成转换。
案例二:MO 转换完成,但后续检测结果不正确
问题描述:模型转换成功,但是预测结果与原生框架大相径庭。
需要解决的问题:
如何定位问题出在哪里及如何解决?
解决方法:
步骤一:更换推理设备
此步骤是为了排除由于设备差异造成的 bug。如果在不同设备上都是同样的问题,那说明与设备无关,此时可以进行步骤二。如果在不同设备上表现不同,比如在 iGPU 上表现异常,而在CPU 上表现正常,则可以认定为 iGPU 上存在 bug,需要将此bug 提交到 Github 上的 issue 中,等待官方补丁。
步骤二:检查推理程序中的前处理代码
此处需要重点排查颜色格式,layout,归一化处理。具体的说:
1) 颜色格式:推理引擎使用的默认颜色格式为 BGR,如果预训练模型采用的是 RGB,那么在作 MO 转换时,需要如图 7所示,指定 --reverse_input_channels 参数,此错误极为常见。
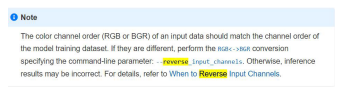
图 7 reverse_input_channels 参数说明
2) layout 检 查: 推 理 引 擎 使 用 的 默 认 layout 为 NCHW,无论是何种原生框架,MO 在转换时均会默认将模型转为NCHW 的 layout。因此在写推理程序时,需要将图片数据按照 NCHW 的格式传给推理引擎。此错误出现几率不高,但也需要自查。
3) 归一化检查:MO 转换时,可以通过指定 --mean_values和 --scale_values 指定归一化参数,公式为:normalized_x= (x-mean_values)/scale_values。指定后,在推理代码中不再需要进行归一化操作。如果不在 MO 转换时指定归一化参数,则在推理代码中需要正常进行归一化操作。此错误有较高出现几率,但较为容易自查。

图 8 mean_values 和 scale_values 参数说明
步骤三:提交官方 github issue,等待官方支持
步骤一和二能解决绝大多数的预测结果不正确的问题,如果反复检查仍不能解决,则需要整理测试用例提交到官方的 issue版块,注意该版块只支持英文,一般五个工作日内能够得到回复。
案例三:算子不支持的问题
这类问题官方有标准解决方案,基本方法是按照官方提供的 模 版 实 现 不 支 持 的 算 子, 感 兴 趣 的 可 查 看 官 方 文 档:https://docs.openvino.ai/latest/openvino_docs_HOWTO_Custom_Layers_Guide.html。
笔者这里提供另外一种解决思路,即通过 MO 对模型进行分割,将不支持的部分单独切出来,使用 c++ 或者 python 实现不支持的部分,而支持的部分使用 MO 进行转换。这种方式的原理,是 MO 支持通过参数 --input 和 --ouput 实现模型的切割,虽然具有局限性(若模型非常复杂则不适用),但也不失为一种选择。下面通过具体的示例进行讲解,该示例来自 于 github 仓 库: :https://github.com/yas-sim/openvinomodel-division-and-simple-custom-layer。
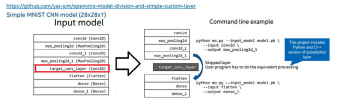
图 9 模型切割示例
如 图 9 所 示,Input model 中 存 在 不 支 持 的 算 子 target_conv_layer,因此在转换时,通过指定 --input 和 --output (参
考 Command line example),将原始模型切割为两个子模型,其中子模型 1 中的输入与原始模型相同,为 conv2d,而输出
为 max_pooling2d_1;子模型 2 中的输入为 flatten,而输出与原始模型相同,为 dense_1。
经过上述操作,我们可以得到两个成功转换的 ir 文件,分别来自于子模型 1 和子模型 2,称之为 ir1 和 ir2。接下来,在推理代码中,我们通过 python 或者是 c++ 来实现 target_conv_layer 的运算。这样,当 ir1 成功完成推理,得到中间数据 data1,我们将 data1 输入给 target_conv_layer 的等价实现,然后得到其输出 data2;最后将 data2 输入给 ir2,从而得到最终的输入结果。
本例中,虽然 input model 直接转换会失败,但通过灵活运用MO 切割模型的特性,我们也可以成功完成模型的转换和部署。
小结:
OpenVINO™ 从 2018 年底诞生到如今,已经发展了三个年头,经过了大量合作伙伴的使用和检验,产品已经比较稳定和成熟,本文中提到的三个案例,涵盖了 MO 中遇到的绝大多数问题,大家可以按图索骥。除去上面讲到的解决思路外,官方还专门整理了 MO 转换中的常见错误:https://docs.openvino.ai/latest/openvino_docs_MO_DG_prepare_model_Model_Optimizer_FAQ.html,当遇到问题时,可以先查阅此页面是否已有解决方案。同时,回顾本文中的示例,可以发现掌握 MO 的核心关键是文
档的阅读和理解,只有充分的理解了 MO 的各个参数,才能灵活运用以帮助我们更好的解决问题。