OpenVINO™ Notebooks教程-中篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
第二章 OpenVINO™ 的核心组件
在上篇中我们了解到OpenVINO™ 是为加速人工智能应用和解决方案开发而生的工具包,基于最新一代的深度学习人工神经网络-包括卷积神经网络 (CNN)、递归神经网络(RNN),能够部署于从边缘到云端的各种架构中,从而实现包括机器视觉、自动语音识别、自然语言处理和推荐系统等多种人工智能应用。
我们知道如果从零开始进行人工智能应用及方案开发将是一项巨大的工程,搜集数据、清洗数据、框架选择、模型训练、**模型、应用开发、测试验证、部署运营,需要投入大量的人力、物力、财力才能完成这一复杂的项目。在上一篇中我们也提到,利用OpenVINO™ 工具包,开发者在不了解算法细节的前提下同样可以快速完成人工智能应用开发,是如何实现的呢?在下面的章节中,我们结合OpenVINO™ 笔记一一解密。在本章节中我们依旧遵循实训原则,边学边练,少说多练,不断巩固知识点学习。
2.1 核心组件与工作流程
知其然,知其所以然。我们先来了解OpenVINO™ 工具包核心组件以及组件之间是如何配合相互完成全部工作流程。推理引擎 Inferece Engine、模型优化器Model Optimizer、优是加速人工智能应用开发的利剑。
推理引擎管理经过优化的神经网络模型的加载和编译,进行推理运算,并输出结果;推理引擎提供统一API接口可以在英特尔多种硬件上进行高性能推理。
模型优化器是一个跨平台命令行工具,将经过训练的神经网络从源框架转换为与 nGraph 兼容的开源中间表示 (IR),用于推理运算。模型优化器支持Caffe、TensorFlow、MXNet、Kaldi 、Pytorch、PaddlePaddle和 ONNX等常用框架预训练的模型输入,进行一些优化,去除冗余的层,并在可能的情况下将操作分组为更简单、更快速的图层用于加速推理运算。
下图展示的是OpenVINO™ 从准备模型至完成推理完整的工作流程:
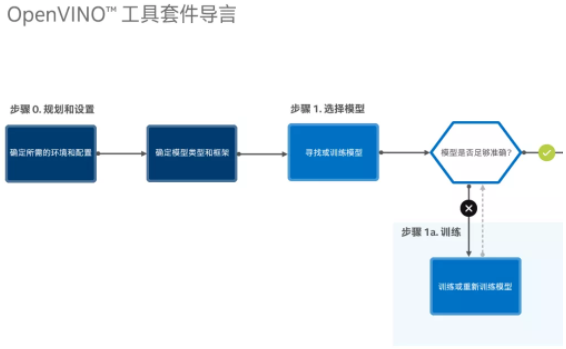
图2-1 先导步骤准备模型
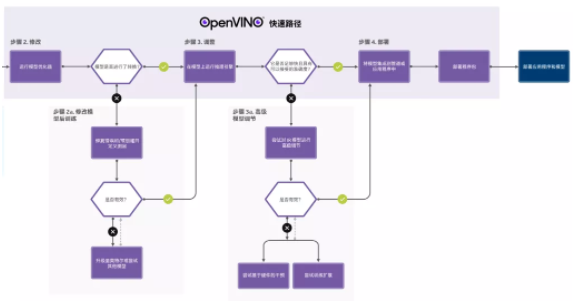
图2-2 模型优化至推理部署流程
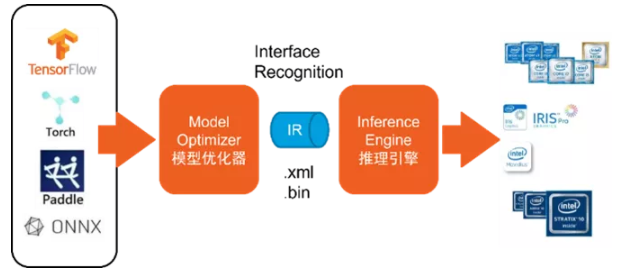
图2-3 推理引擎与模型优化器协同工作
通过以上介绍我们已了解,模型优化器可以对主流框架的预处理模型进行优化及转化,充分利用已有资源不必从零开始加快了应用开发进程;推理引擎提供统一的API可以运行在不同的硬件平台上,并且可以指定模型运行在特定的硬件设备上,一次编程永久使用,加快了推理进程;优化工具集以及行业应用演示案例即提供了参考代码又提供了性能优化工具,加快了应用开发流程;核心组件三剑客协同作用,我们使用OpenVINO™ 工具包既可以作为学习人工智能开发的技术指导又可以作为快速开发应用从而加速产品进入市场的好工具。
笔者认为实训教程比较好的展现形式就是少说多练,用较为精炼的语言突出重点,通过大量的实践案例巩固学习成果。这也是我们推荐使用OpenVINO™ 笔记作为教程的原因。
从下一节开始,我们利用OpenVINO™ 笔记深入学习核心组件使用,详解核心组件API从而掌握推理引擎及模型优化器使用技能。
我们执行Jupyter命令开启学习之旅。
source $HOME/openvino_env/bin/activate
jupyter-lab openvino_notebooks/notebooks
图2-4 OpenVINO™ 笔记工作环境
2.2 推力引擎详解
2.1.1 Hello World
学习目标:
· 认识OpenVINO™ 推理引擎
· 掌握使用推理引擎基础步骤
· 了解笔记使用的模型及软件模块
Hello World,Hello OpenVINO™ 。看到Hello World,这代表将会用最简洁的代码展示将要学习的内容,我们开始操练。
在OpenVINO™ 笔记工程中双击001-hello-world进入子目录,双击001-hello-world.ipynb打开笔记文件。
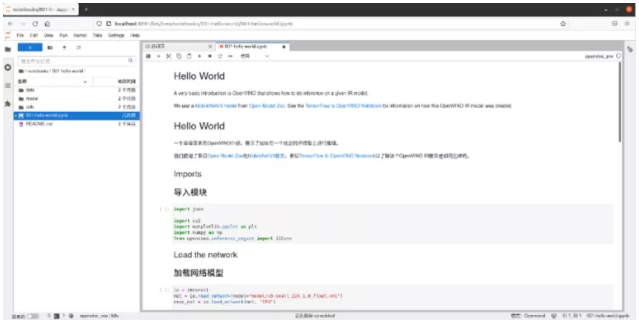
图2-5 hello-world笔记
我们使用笔记执行全部单元格命令,快速获得最终结果。进入运行菜单-点击运行全部单元格按钮。
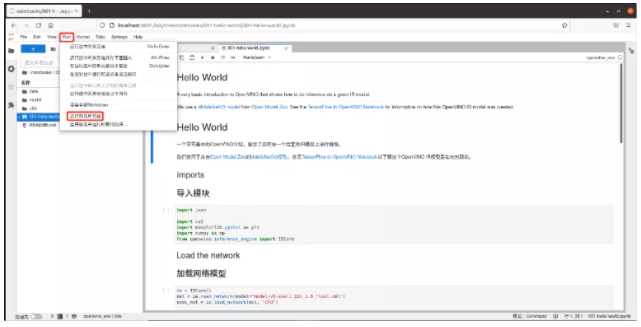
图2-6 hello-world笔记执行全部单元格
不需要等待太久,我们就得到了对输入图片进行分类推理结果,显示结果图片中是短毛寻回犬。
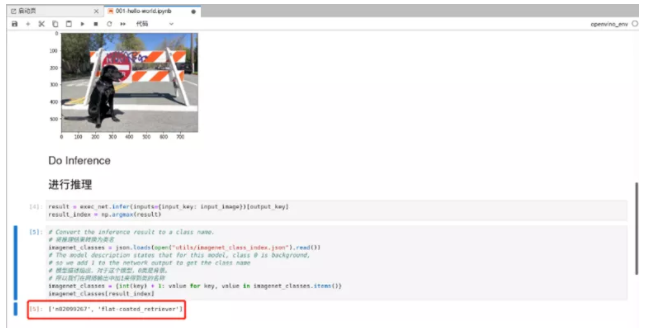
图2-7 hello-world运行结果
演示笔记仅用19行代码就实现了人工智能分类应用,恭喜我们正式开启了人工智能应用开发之路。接下来我们通过解读代码来学习笔记是如何实现图片分类识别的功能。我们使用笔记单步执行功能,查看每一步的执行情况。在单步执行研读代码之前,我们选择内核菜单栏,点击重启内核并清楚所有结果为我们接下来单步操作做好准备。
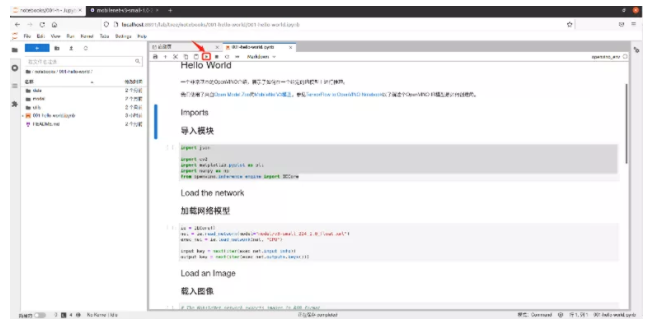
图2-8 hello-world单步执行
1、导入程序所需要的python模块

图2-9 hello-world导入模块
import json
import cv2
import matplotlib.pyplot as plt
import numpy as np
from openvino.inference_engine import IECore认识新模块:
· json(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于阅读和编写。
· cv2大名鼎鼎的openCV机器视觉函数库
· matplotlib 是一个2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。通过 matplotlib开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。
· numpy(Numerical Python)是一个开源的数值计算扩展。这个工具可用来存储和处理大型矩阵,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
· OpenVINO™ .inference_engine 推理引擎模块
2、加载网络模型
初始化推理引擎、读入网络模型、配置使用的硬件设备并加载网络、配置输入输出

图2-10 hello-world加载网络模型
ie = IECore()
net = ie.read_network(model="model/v3-**all_224_1.0_float.xml")
exec_net = ie.load_network(net, "CPU")
input_key = next(iter(exec_net.input_info))
output_key = next(iter(exec_net.outputs.keys()))· MobileNetV3模型介绍
MobileNet是由Gooogle研究者们设计的一类卷积神经网络,模型具有计算消耗小、运行速度快、运行效果准的特点,非常适合在移动设备上运行。
3、 加载图片
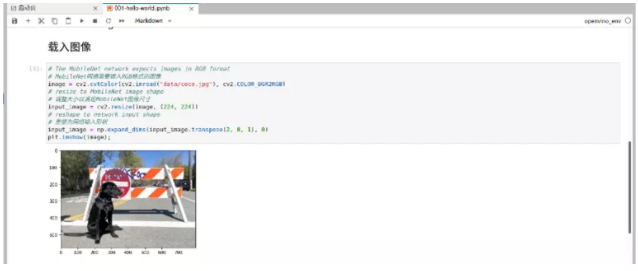
图2-11 hello-world加载显示图片
image = cv2.cvtColor(cv2.imread("data/coco.jpg"), cv2.COLOR_BGR2RGB)
input_image = cv2.resize(image, (224, 224))
input_image = np.expand_dims(input_image.transpose(2, 0, 1), 0)
plt.imshow(image);读取图片、色彩空间转换openCV库默认读取图片的格式为BGR,mobilenetv3需要输入的色彩空间为RGB,因此在读出图片后需要进行色彩空间转换;调整输入图片尺寸为224x224以适配模型需要。代码执行完成,将显示需要推理的图片。
4、 执行推理
result = exec_net.infer(inputs={input_key: input_image})[output_key]
result_index = np.argmax(result)5、处理并显示结果
imagenet_classes=json.loads(open("utils/imagenet_class_index.json").read())
imagenet_classes={int(key) + 1: value for key, value in imagenet_classes.item******r>imagenet_classes[result_index]将推理结果与json文件中的类名进行匹配,具有更好的可读性。
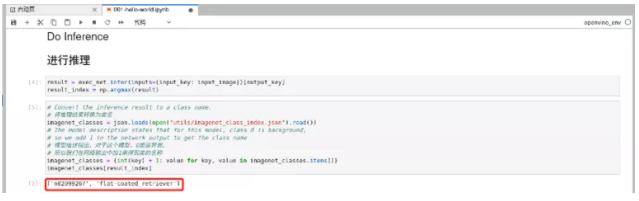
图2-12 hello-world显示推理结果
2.2.2 推理引擎API详解
学习目标:
1、掌握推理引擎API使用
在上一节中我们学习了利用推理引擎开仅用十几行代码便完成分类任务的案例,在本节中我们深入学习推理引擎的API,掌握完整的开发流程。
双击002-OpenVINO™ -api目录,双击打开002-OpenVINO™ -api.ipynb笔记。本节解释了OpenVINO™ 推理引擎API的基础知识。它包括:
· 加载推理引擎及信息显示
· 加载不同模型
· IR模型
· ONNX模型
· 获取模型信息
· 模型输入
· 模型输出
· 使用模型进行推理
· 重塑和调整大小
· 改变图像大小
· 改变批量大小
为便于学习笔记本被划分为带有标题的章节。每一节都是独立的,不依赖于前面的章节。同时,笔记提供了一个分割和分类的IR模型和一个分割的ONNX模型作为例子。我们同样使用Juypter笔记单步执行的功能进行学习。
1、 导入模块并初始化引擎
 图2-11 OpenVINO™ -图2-11 OpenVINO™ -api初始化推理引擎
图2-11 OpenVINO™ -图2-11 OpenVINO™ -api初始化推理引擎from openvino.inference_engine import IECore
ie = IECore()2、 查询支持的硬件设备并显示

图2-14 OpenVINO™ -api查询系统支持的推理设备
devices = ie.available_device***r>for device in devices:
device_name = ie.get_metric(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")3、 加载模型

图2-15 OpenVINO™ -api加载模型
from openvino.inference_engine import IECore
ie = IECore()
classification_model_xml = "model/classification.xml"
net = ie.read_network(model=classification_model_xml)
exec_net = ie.load_network(network=net, device_name="CPU")在初始化推理引擎后,首先用read_network()读取模型文件,然后用load_network()将其加载到指定设备上。IR模型IR(Intermediate Representation)模型由一个包含模型信息的.xml文件和一个包含权重的.bin文件组成。read_network()希望权重文件与xml文件位于同一目录下,文件名相同,扩展名为.bin:model_weights_file == Path(model_xml).with_suffix(".bin")。如果是这种情况,指定权重文件是可选的。如果权重文件有不同的文件名,可以通过read_network()的weights参数来指定。
新版本的推理引擎支持直接读取ONNX模型,读取和加载ONNX模型的方法与读取和加载IR模型的方法相同。model参数指向ONNX文件名。

图2-16 OpenVINO™ -api加载ONNX模型
from openvino.inference_engine import IECore
ie = IECore()
onnx_model = "model/segmentation.onnx"
net_onnx = ie.read_network(model=onnx_model)
exec_net_onnx = ie.load_network(network=net_onnx, device_name="CPU")4、 获取关于模型的信息
OpenVINO™ IENetwork实例存储了关于模型的信息。关于模型的输入和输出的信息在net.input_info和net.output中。这些也是ExecutableNetwork实例的属性。在下面的单元格中我们使用net.input_info和net.output,你也可以使用exec_net.input_info和exec_net.output。
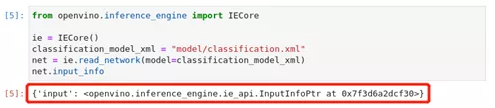
图2-17 OpenVINO™ -api模型信息
from openvino.inference_engine import IECore
ie = IECore()
classification_model_xml = "model/classification.xml"
net = ie.read_network(model=classification_model_xml)
net.input_info模型输入,上面的单元格显示,加载的模型期望有一个输入,名称为_input_。如果加载了一个不同的模型,你可能会看到一个不同的输入层名称,而且你可能会看到更多的输入。有一个对第一个输入层名称的引用通常是有用的。对于一个只有一个输入的模型,next(iter(net.input_info))得到这个名称。

图2-18 OpenVINO™ -api模型输入
input_layer = next(iter(net.input_info))
input_layer
图2-19 OpenVINO™ -api模型信息
print(f"input layout: {net.input_info[input_layer].layout}")
print(f"input precision: {net.input_info[input_layer].precision}")
print(f"input shape: {net.input_info[input_layer].tensor_desc.dims}")5、 模型输出
模型输出信息存储在net.output中。上面的单元格显示,该模型返回一个输出,名称为_MobilenetV3/Predictions/Softmax_。如果你加载了一个不同的模型,你可能会看到一个不同的输出层名称,你可能会看到更多的输出。因为这个模型有一个输出,所以按照输入层的方法来获取它的名字。
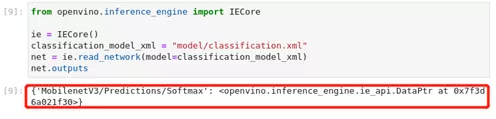
图2-20 OpenVINO™ -api模型输出
from openvino.inference_engine import IECore
ie = IECore()
classification_model_xml = "model/classification.xml"
net = ie.read_network(model=classification_model_xml)
net.outputs
devices = ie.available_device***r>for device in devices:
device_name = ie.get_metric(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")
图2-21 OpenVINO™ -api模型输出信息
print(f"output layout: {net.outputs[output_layer].layout}")
print(f"output precision: {net.outputs[output_layer].precision}")
print(f"output shape: {net.outputs[output_layer].shape}")6、 使用模型进行推理
要使用模型进行推理,请调用_ExecutableNetwork_的infer()方法,即我们用load_network()加载的exec_net。infer()需要带有参数,_inputs_是一个字典,将输入层名称映射到输入数据。
1) 准备工作:加载网络
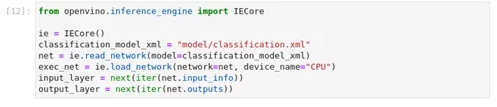
图2-22 OpenVINO™ -api初始化引擎并加载网络
from openvino.inference_engine import IECore
ie = IECore()
classification_model_xml = "model/classification.xml"
net = ie.read_network(model=classification_model_xml)
exec_net = ie.load_network(network=net, device_name="CPU")
input_layer = next(iter(net.input_info))
output_layer = next(iter(net.outputs))2) 准备工作:加载图像并转换为输入形状。
为了在网络中处理图像,需要将其加载到一个数组中,调整为网络所期望的形状,并转换为网络的输入布局。

图2-23 OpenVINO™ -api读入图片信息
import cv2
image_filename = "data/coco_hollywood.jpg"
image = cv2.imread(image_filename)
image.shape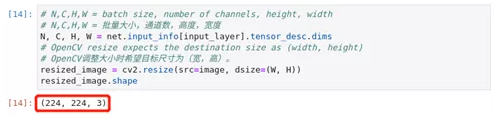
图2-16 OpenVINO™ -api加载ONNX模型
N, C, H, W = net.input_info[input_layer].tensor_desc.dim***r>resized_image = cv2.resize(src=image, dsize=(W, H))
resized_image.shape现在,图像的宽度和高度是网络所期望的。它仍然是H,C,W格式。我们首先调用np.transpose()将其改为N,C,H,W格式(其中N=1),然后通过调用np.expand_dims()添加N维。用np.astype()将数据转换为FP32。

图2-25 OpenVINO™ -api处理图片符合模型要求
import numpy as np
input_data = np.expand_dims(np.transpose(resized_image, (2, 0, 1)), 0).astype(np.float32)
input_data.shape现在,输入数据的形状是正确的,仅用一个简单的命令即可进行推理。

图2-26 OpenVINO™ -api 推理获得结果
result = exec_net.infer({input_layer: input_data})
result
图2-27 OpenVINO™ -api 推理结果
output = result[output_layer]
output.shape输出的形状是(1,1001),我们看到这是输出的预期形状。这个输出形状表明,该网络返回了1001个类的概率
5) 重塑和调整大小
· 调整图像大小
我们可以不使用重塑图像来适应模型,而是通过重塑模型来适应图像。注意不是所有的模型都支持重塑,而支持重塑的模型可能不支持所有的输入形状。如果你重塑模型的输入形状,模型的准确性也可能受到影响。我们首先检查模型的输入形状,然后重塑为新的输入形状。
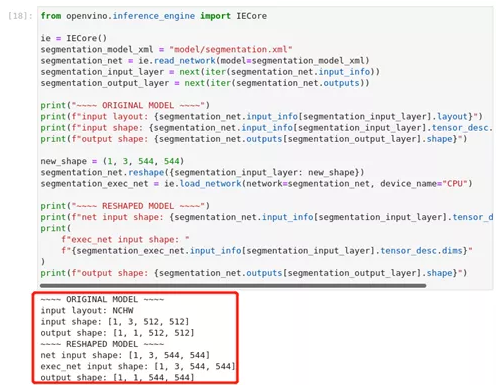
图2-28 OpenVINO™ -api 调整图像尺寸
from OpenVINO.inference_engine import IECore
ie = IECore()
segmentation_model_xml = "model/segmentation.xml"
segmentation_net = ie.read_network(model=segmentation_model_xml)
segmentation_input_layer = next(iter(segmentation_net.input_info))
segmentation_output_layer = next(iter(segmentation_net.output*****r>print("~~~~ ORIGINAL MODEL ~~~~")
print(f"input layout: {segmentation_net.input_info[segmentation_input_layer].layout}")
print(f"input shape: {segmentation_net.input_info[segmentation_input_layer].tensor_desc.dim******r>print(f"output shape: {segmentation_net.outputs[segmentation_output_layer].shape}")
new_shape = (1, 3, 544, 544)
segmentation_net.reshape({segmentation_input_layer: new_shape})
segmentation_exec_net = ie.load_network(network=segmentation_net, device_name="CPU")
print("~~~~ RESHAPED MODEL ~~~~")
print(f"net input shape: {segmentation_net.input_info[segmentation_input_layer].tensor_desc.dim******r>print(
f"exec_net input shape: "
f"{segmentation_exec_net.input_info[segmentation_input_layer].tensor_desc.dim*****r>)
print(f"output shape: {segmentation_net.outputs[segmentation_output_layer].shape}")· 改变批处理大小
我们也可以使用.reshape()来设置批量大小,通过增加_new_shape_的第一个元素。例如,要设置2个批次的大小,在上面的单元格中设置new_shape = (2,3,544,544)。如果你只想改变批量大小,你也可以直接设置batch_size属性。
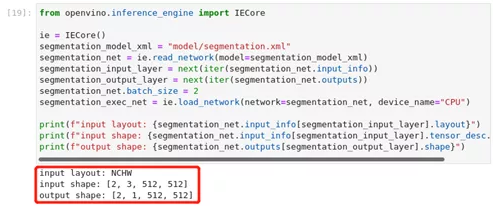
图2-29 OpenVINO™ -api 调整批处理大小
from OpenVINO.inference_engine import IECore
ie = IECore()
segmentation_model_xml = "model/segmentation.xml"
segmentation_net = ie.read_network(model=segmentation_model_xml)
segmentation_input_layer = next(iter(segmentation_net.input_info))
segmentation_output_layer = next(iter(segmentation_net.output*****r>segmentation_net.batch_size = 2
segmentation_exec_net = ie.load_network(network=segmentation_net, device_name="CPU")
print(f"input layout: {segmentation_net.input_info[segmentation_input_layer].layout}")
print(f"input shape: {segmentation_net.input_info[segmentation_input_layer].tensor_desc.dim******r>print(f"output shape: {segmentation_net.outputs[segmentation_output_layer].shape}")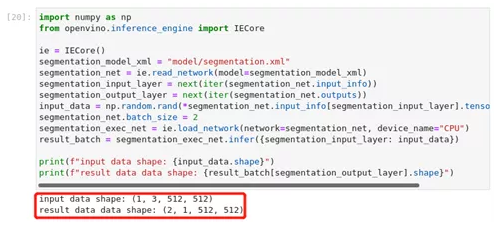
图2-30 OpenVINO™ -api批量为2的情况
import numpy as np
from OpenVINO.inference_engine import IECore
ie = IECore()
segmentation_model_xml = "model/segmentation.xml"
segmentation_net = ie.read_network(model=segmentation_model_xml)
segmentation_input_layer = next(iter(segmentation_net.input_info))
segmentation_output_layer = next(iter(segmentation_net.output*****r>input_data = np.random.rand(*segmentation_net.input_info[segmentation_input_layer].tensor_desc.dim****r>segmentation_net.batch_size = 2
segmentation_exec_net = ie.load_network(network=segmentation_net, device_name="CPU")
result_batch = segmentation_exec_net.infer({segmentation_input_layer: input_data})
print(f"input data shape: {input_data.shape}")
print(f"result data data shape: {result_batch[segmentation_output_layer].shape}")输出显示,如果批次大小为2,网络输出将有2的批次大小,即使只有一个图像通过网络传播。不管批次大小如何,你总是可以在一个图像上做推理。在这种情况下,只有第一个网络输出包含有意义的信息。通过创建批次大小为2的随机数据来验证对两幅图像的推理是否有效。
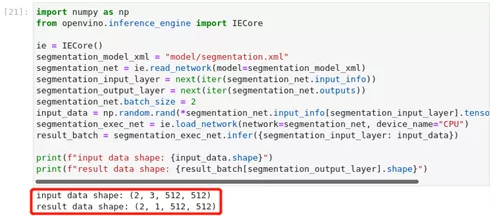
图2-31 OpenVINO™ -api批次为2的输出结果
import numpy as np
from OpenVINO.inference_engine import IECore
ie = IECore()
segmentation_model_xml = "model/segmentation.xml"
segmentation_net = ie.read_network(model=segmentation_model_xml)
segmentation_input_layer = next(iter(segmentation_net.input_info))
segmentation_output_layer = next(iter(segmentation_net.output*****r>segmentation_net.batch_size = 2
input_data = np.random.rand(*segmentation_net.input_info[segmentation_input_layer].tensor_desc.dim****r>segmentation_exec_net = ie.load_network(network=segmentation_net, device_name="CPU")
result_batch = segmentation_exec_net.infer({segmentation_input_layer: input_data})
print(f"input data shape: {input_data.shape}")
print(f"result data shape: {result_batch[segmentation_output_layer].shape}")通过上面的学习,我们可以总结出使用推理引擎进行推理的流程,我们只要按照流程步骤进行编程便可得到结果。我们再来回顾下完整流程,在后续的章节中我们会通过不同的案例不断练习这个流程,直至熟练掌握:
· 初始化载入硬件插件,所有AI计算硬件的插件都由IECore对象自行内部管理。读取IR文件,用类IECore将IR文件使用read_network()方法读入到IENetwork类对象中去。
· 配置输入输出,将模型载入内存后,用inputs和outputs指定模型输入输出张量的精度和布局(layout)。
· 载入模型,模型载入AI计算硬件后,会获得一个ExecutableNetwork对象,该对象执行推理计算。read_network()方法中的deviceName参数指定使用哪个AI计算硬件。
· 准备输入数据通过OpenCV采集图像数据到Mat对象,然后用frameToBlob()函数将OpenCV Mat对象中的图像数据传给InferenceEngine Blob对象,AI模型将从InferenceEngine Blob对象中获取图像数据。
· 执行推理计算,用infer()方法执行同步推理计算,或者用StartAsync()和Wait()方法执行异步推理计算。
· 处理模型输出输出为模型输出的张量outputs,此时可以对结果进行读取、打标签或画框等操作。
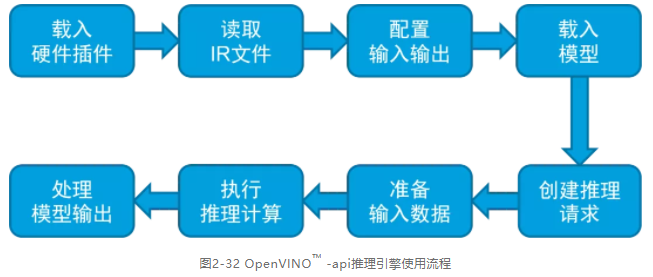
图2-32 OpenVINO™ -api推理引擎使用流程
2.3.3 Hello Segmentation
学习目标:
· 巩固学习推理引擎API
· 掌握推理引擎使用流程
· 认识道路分割模型
在上节中我们详细学习了推理引擎的API使用,我们按照初始化推理引擎-读取网络模型-配置输入输出-载入模型-准备数据-执行推理-处理输出数据的流程即可完成人工智能应用的开发。在本节中,我们使用Open Model Zoo的[road-segmentation-adas-0001]模型进行练习,巩固推理引擎的API学习成果。ADAS是高级驾驶辅助服务的缩写。该模型识别了四个类别:背景、道路、路边和标志。该模型的原框架为PyTorch,输入图像大小896x512。了解背景后我们开始操练。
1、 导入模块
图2-33 hello-segmentation
import cv2
import matplotlib.pyplot as plt
import numpy as np
import sy***r>from OpenVINO.inference_engine import IECore
sys.path.append("../util*****r>from notebook_utils import segmentation_map_to_image2、 加载模型

图2-34 hello-segmentation初始化引擎及加载模型
ie = IECore()
net = ie.read_network(
model="model/road-segmentation-adas-0001.xml")
exec_net = ie.load_network(net, "CPU")
output_layer_ir = next(iter(exec_net.output*****r>input_layer_ir = next(iter(exec_net.input_info))3、 加载图像
根据网络模型输入要求,对图像进行处理并显示原始图像

图2-35 hello-segmentation图像处理
image = cv2.imread("data/empty_road_mapillary.jpg")
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_h, image_w, _ = image.shap
N, C, H, W = net.input_info[input_layer_ir].tensor_desc.dim***r>resized_image = cv2.resize(image, (W, H))
input_image = np.expand_dim****r>resized_image.transpose(2, 0, 1), 0
)
plt.imshow(rgb_image)读入图像、将图像色彩空间由BGR转换为RGB、根据网络模型输入需要调整图像尺寸,显示图像。
4、 执行推理并显示结果
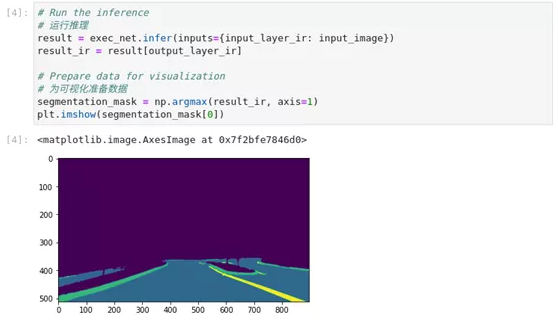
图2-36 hello-segmentation推理结果
result = exec_net.infer(inputs={input_layer_ir: input_image})
result_ir = result[output_layer_ir]
segmentation_mask = np.argmax(result_ir, axis=1)
plt.imshow(segmentation_mask[0])5、 准备数据可视化
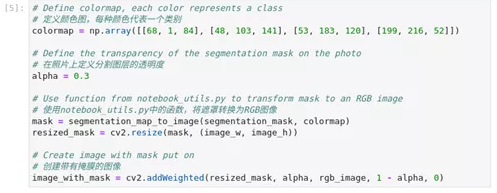
图2-37 hello-segmentation可视化准备
alpha = 0.3
mask = segmentation_map_to_image(segmentation_mask, colormap)
resized_mask = cv2.resize(mask, (image_w, image_h))
image_with_mask = cv2.addWeighted(resized_mask, alpha, rgb_image, 1 - alpha, 0)在这一步中,定义颜色图,每种类别以一种颜色表示,定义了分割图层的透明度,使用工具函数进行图像色彩空间转换,创建带有掩膜的图像。下一步进行数据可视化展示。
6、 数据可视化展示
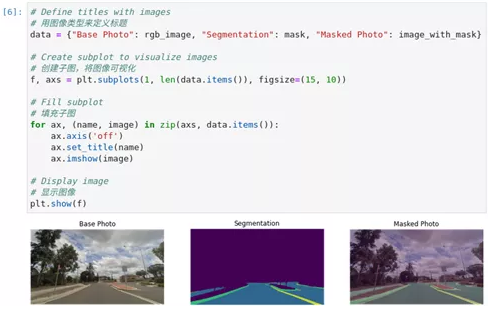
图2-38 hello-segmentation可视化展示
data = {"Base Photo": rgb_image, "Segmentation": mask, "Masked Photo": image_with_mask}
f, axs = plt.subplots(1, len(data.items()), figsize=(15, 10))
for ax, (name, image) in zip(axs, data.items()):
ax.axis('off')
ax.set_title(name)
ax.imshow(image)
plt.show(f)2.2.4 Hello Detection
本节目标:· 强化学习推理引擎API
· 熟练掌握推理引擎使用流程
· 了解文本检测模型
本节学习使用推理引擎完成检测模型的应用,学习如何在一个给定的IR模型上进行文本检测。我们使用Open Model Zoo中的[horizontal-text-detection-0001]模型。它检测图像中的文本,并返回形状为[100, 5]的blob数据。对于每个检测的描述都有[x_min, y_min, x_max, y_max, conf]格式。该模型是基于FCOS架构的文本检测器,以类似MobileNetV2为骨干,适用于有或多或少水平文字的室内/室外场景。源框架为PyTorch,与基础模型相比,该模型的主要优点是尺寸更小,性能更快。
下面我们开始练习。
1、 导入所需模块

图2-39 hello-detection导入模块
import cv2
import matplotlib.pyplot as plt
import numpy as np
from OpenVINO.inference_engine import IECore
from os.path import isfile2、 加载网络模型
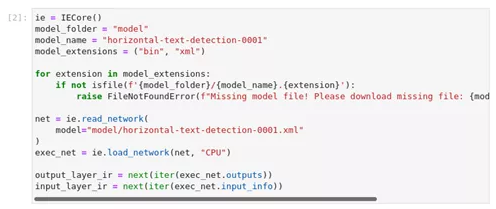
图2-40 hello-detection加载网络模型
ie = IECore()
model_folder = "model"
model_name = "horizontal-text-detection-0001"
model_extension*******in", "xml")
for extension in model_extensions:
if not isfile(f'{model_folder}/{model_name}.{extension}'):
raise FileNotFoundError(f"Missing model file! Please download missing file: {model_name}.{extension}")
net = ie.read_network(
model="model/horizontal-text-detection-0001.xml"
)
exec_net = ie.load_network(net, "CPU")
output_layer_ir = next(iter(exec_net.output*****r>input_layer_ir = next(iter(exec_net.input_info))3、加载并处理图片
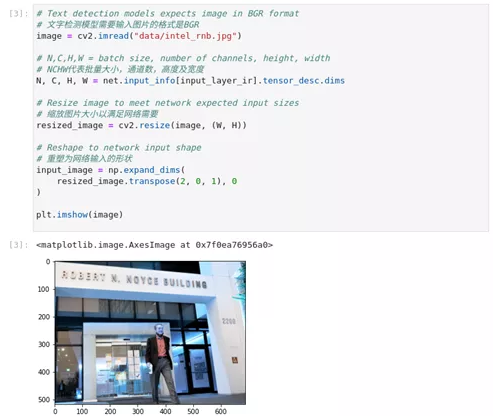
图2-41 hello-detection图片预处理
image = cv2.imread("data/intel_rnb.jpg")
N, C, H, W = net.input_info[input_layer_ir].tensor_desc.dim***r>resized_image = cv2.resize(image, (W, H))
input_image = np.expand_dim****r>resized_image.transpose(2, 0, 1), 0
)
plt.imshow(image)4、进行推理
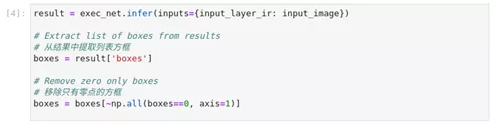
图2-42 hello-detection加载网络模型
result = exec_net.infer(inputs={input_layer_ir: input_image})
boxes = result['boxe*****r>boxe*****oxes[~np.all(boxes==0, axis=1)]5、 数据可视化
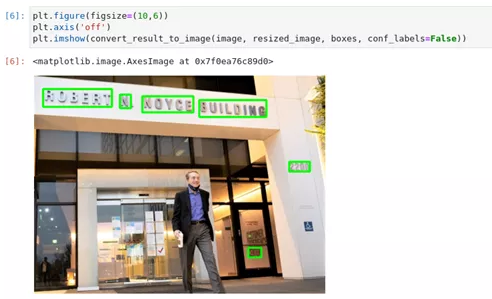
图2-43 hello-detection结果展示
def convert_result_to_image(bgr_image, resized_image, boxes, threshold=0.3, conf_labels=True):
def multiply_by_ratio(ratio_x, ratio_y, box):
return [max(shape * ratio_y, 10) if idx % 2 else shape * ratio_x for idx, shape in enumerate(box[:-1])]
colors = {'red': (255, 0, 0), 'green': (0, 255, 0)}
(real_y, real_x), (resized_y, resized_x) = image.shape[:2], resized_image.shape[:2]
ratio_x, ratio_y = real_x/resized_x, real_y/resized_y
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
for box in boxes:
conf = box[-1]
if conf > threshold:
(x_min, y_min, x_max, y_max) = map(int, multiply_by_ratio(ratio_x, ratio_y, box))
rgb_image = cv2.rectangle(
rgb_image,
(x_min, y_min),
(x_max, y_max),
colors['green'],
3
)
if conf_labels:
rgb_image = cv2.putText(
rgb_image,
f"{conf:.2f}",
(x_min, y_min - 10),
cv2.FONT_HERSHEY_SIMPLEX,
0.8,
colors['red'],
1,
cv2.LINE_AA
)
return rgb_image
plt.figure(figsize=(10,6))
plt.axis('off')
plt.imshow(convert_result_to_image(image, resized_image, boxes, conf_labels=False))2.1.5 小结
通过本节学习我们掌握了推理引擎API函数、掌握了使用推理引擎进行开发的完整流程,同时通过案例我们学习了Mobilenetv3分类模型、基于PyTorch框架的道路分割模型以及文本检测模型。
2.3 模型优化器详解
我们一直在学习探讨深度学习、神经网络。其实,神经网络并不复杂,就是多个神经元的堆叠。多个神经元之间通过网络拓扑结构相连,具备一定的分类能力,谓之“神经网络”。通常情况,网络层数越多、参数越多,数据越多推理的精度越高。但并不是所有的网络层都有助于进行推理。OpenVINO™ 的模型优化器可以自动识别推理过程中是无用的,并且可能会增加推理时间的图层,比如对于训练很重要的Dropout图层。通过对于无用层的裁剪完成模型优化功能。
我们先了解下模型优化器提供的功能及特点:
· 优化网络
· 改变格式
· 削减部分网络
· 支持自定义层
· 支持主流框架格式包括TensorFlow、Caffe、MXNet、Kaidi和ONNX格式
· 生成文件为IR中间层
· 模型优化器后准确度、精度基本不变,但性能必定会提升。模型生成IR中间层
在了解完模型优化器的工作原理后,我们开始实训环节,在后续章节中我们将练习将Tensoflow模型、PyTorch模型、PaddlePaddle模型进行优化并完成推理。
2.3.1 Tensorflow模型优化
学习目标:掌握将TensorFlow模型转换为OpenVINO™ IR格式
1、 导入模块
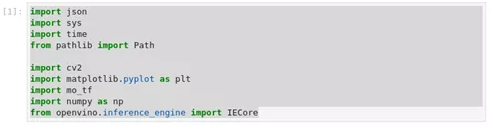
图2-44 tensorflow-to-OpenVINO™ 导入模块
import json
import sy***r>import time
from pathlib import Path
import cv2
import matplotlib.pyplot as plt
import mo_tf
import numpy as np
from openvino . inference_engine import IECore· pathlib 是python自带的用于处理文件路径的模块,使用pathlib可以创建路径对象。使用路径对象而不是字符串的一个重要优点是,我们可以在路径对象上调用方法。
· mo_tf 模型优化器用于处理tensorflow模型的转换的模块

图2-45 tensorflow-to-OpenVINO™ 定义模型名称
model_path = Path("model/v3-**all_224_1.0_float.pb")
ir_path = Path(model_path).with_suffix(".xml")2、 构建转换命令
调用OpenVINO™ 模型优化工具,将TensorFlow模型转换为OpenVINO™ IR,精度为FP16。模型被保存到当前目录。我们将平均值添加到模型中,并通过--scale_values将输出与标准偏差进行缩放。有了这些选项,在通过网络传播之前,没有必要对输入数据进行标准化处理。原始模型希望输入的图像是RGB格式的。转换后的模型也希望是RGB格式的图像。如果你想让转换后的模型适用于BGR图像,你可以使用--反转输入通道选项。参见模型优化器开发者指南以了解更多关于模型优化器的信息,包括命令行选项的描述。查看模型文档,了解有关模型的信息,包括输入形状、预期颜色顺序和平均值。
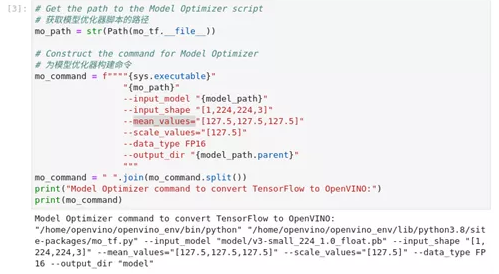
图2-46 tensorflow-to-OpenVINO™ 构建优化命令
mo_path = str(Path(mo_tf.__file__))
mo_command = f""""{sys.executable}"
"{mo_path}"
--input_model "{model_path}"
--input_shape "[1,224,224,3]"
--mean_values="[127.5,127.5,127.5]"
--scale_values="[127.5]"
--data_type FP16
--output_dir "{model_path.parent}"
"""
mo_command = " ".join(mo_command.split())
print("Model Optimizer command to convert TensorFlow to OpenVINO™ :")
print(mo_command)3、 执行优化命令
模型优化过程会花一些时间,根据运行设备不同时间会有差异。当我们看到输出结果的最后几行包括`[ SUCCESS ] Generated IR version 10 model.`则模型优化是成功的。同时我们在model文件夹可以看到新生成的xml及bin文件。
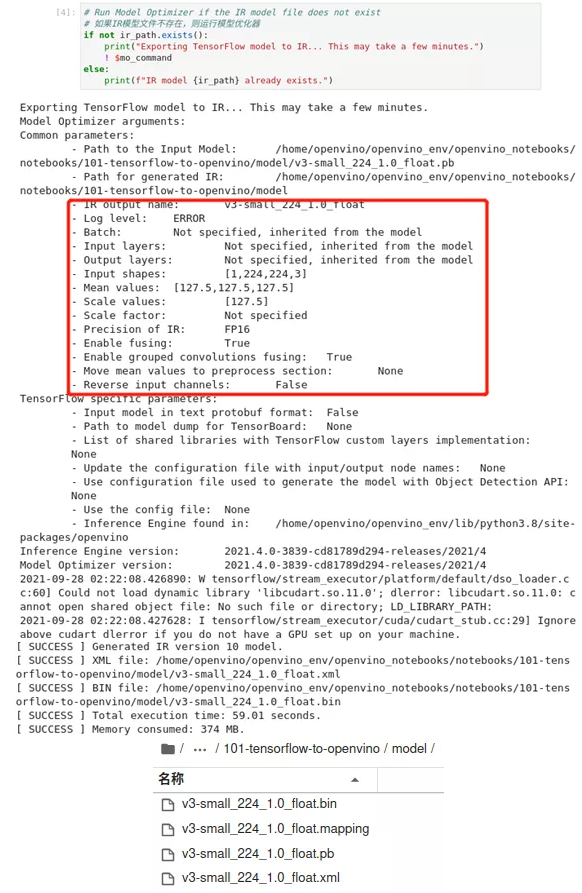
图2-47 tensorflow-to-OpenVINO™ 执行模型优化及模型输出
1) 加载模型

图2-48 tensorflow-to-OpenVINO™ 加载模型
ie = IECore()
net = ie.read_network(str(ir_path))
exec_net = ie.load_network(net, "CPU")
图2-49 tensorflow-to-OpenVINO™ 获取模型信息
input_key = list(exec_net.input_info)[0]
output_key = list(exec_net.outputs.keys())[0]
network_input_shape = exec_net.input_info[input_key].tensor_desc.dims
图2-50 tensorflow-to-OpenVINO™ 获取模型信息
image = cv2.cvtColor(cv2.imread("data/coco.jpg"), cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image, (224, 224))
input_image = np.reshape(resized_image, network_input_shape) / 255
input_image = np.expand_dims(np.transpose(resized_image, (2, 0, 1)), 0)
plt.imshow(image)4) 执行推理
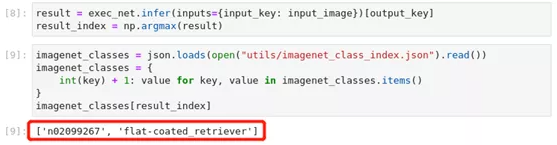
图2-51 tensorflow-to-OpenVINO™执行推理并输出结果
esult = exec_net.infer(inputs={input_key: input_image})[output_key]
result_index = np.argmax(result)
imagenet_classes = json.loads(open("utils/imagenet_class_index.json").read())
imagenet_classe*******r>int(key) + 1: value for key, value in imagenet_classes.item*****r>}
imagenet_classes[result_index]5) 性能测试
测量在一千张图片上进行推理所需的时间。以便于显示出模型优化后的性能。对于更精确的基准测试,请使用OpenVINO™ 基准测试工具。我们在后面的章节会学习如何使用OpenVINO™ Benchmark进行基准测试。
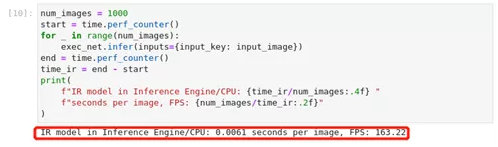
图2-52 tensorflow-to-OpenVINO™ 性能测试结果
num_images = 1000
start = time.perf_counter()
for _ in range(num_images):
exec_net.infer(inputs={input_key: input_image})
end = time.perf_counter()
time_ir = end - start
print(
f"IR model in Inference Engine/CPU: {time_ir/num_images:.4f} "
f"seconds per image, FPS: {num_images/time_ir:.2f}"
)2.1.2 PyTorch模型优化
学习目标:
· 掌握PyTorch模型转化为ONNX格式的方法
· 掌握将ONNX转化为IR格式的方法
本节演示了使用OpenVINO™ 对PyTorch语义分割模型进行优化并使用转换后的模型进行推理的逐步说明。
PyTorch模型需要先被转换为ONNX格式,然后再使用模型优化器将ONNX模型转化为OpenVINO™ 中间表示(IR)格式。ONNX和IR模型被加载到OpenVINO™ 推理引擎中以显示模型预测。该模型在CityScapes上进行了预训练。模型来源是https://github.com/ekzhang/fastseg 。
Fastseg是用于实时语义分割的MobileNetV3的PyTorch实现,具有预训练的权重和最先进的性能。
我们开始实操练习
1、 导入模块

图2-53 pytorch-onnx-to-OpenVINO™ 导入模块
import sy***r>
import time
import o***r>
from pathlib import Path
import cv2
import matplotlib.pyplot as plt
import mo_onnx
import numpy as np
import torch
from fastseg import MobileV3Large
from openvino.inference_engine import IECore
sys.path.append("../util*****r>
from notebook_utils import CityScapesSegmentation, segmentation_map_to_image, viz_result_image· mo_onnx 模型优化器转换ONNX格式模块
· torch PyTorch框架的功能模块,包含卷积函数、池化功能等
· fastseg fastseg算法模型模块
2、 模型转换配置
设置模型的名称,以及将用于网络的图像宽度和高度。CityScapes是在2048x1024的图像上进行预训练的。使用更小的尺寸会影响模型的准确性,但会提高推理速度。
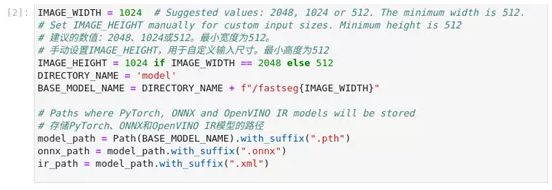
图2-54 pytorch-onnx-to-OpenVINO™ 模型转换配置
IMAGE_WIDTH = 1024
IMAGE_HEIGHT = 1024 if IMAGE_WIDTH == 2048 else 512
DIRECTORY_NAME = 'model'
BASE_MODEL_NAME = DIRECTORY_NAME + f"/fastseg{IMAGE_WIDTH}"
model_path = Path(BASE_MODEL_NAME).with_suffix(".pth")
onnx_path = model_path.with_suffix(".onnx")
ir_path = model_path.with_suffix(".xml")3、 下载Fastseg模型
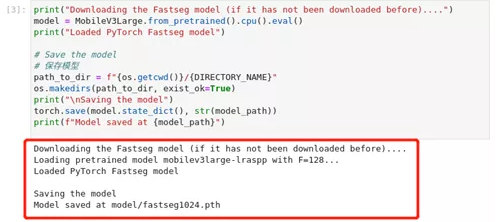
图2-55 pytorch-onnx-to-OpenVINO™ 下载模型
print("Downloading the Fastseg model (if it has not been downloaded before)....")
model = MobileV3Large.from_pretrained().cpu().eval()
print("Loaded PyTorch Fastseg model")
path_to_dir = f"{os.getcwd()}/{DIRECTORY_NAME}"
o***akedirs(path_to_dir, exist_ok=True)
print("\nSaving the model")
torch.save(model.state_dict(), str(model_path))
print(f"Model saved at {model_path}")4、 将PyTorch模型导出为ONNX格式
我们使用torch模块onnx.export功能将PyTorch模型转换为ONNX模型,如果在输出显示一些警告,我们可以忽略。如果输出的最后一行显示 "ONNX模型导出到fastseg1024.onnx.`",则转换成功。
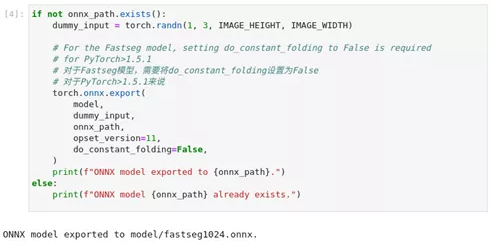
图2-56 pytorch-onnx-to-OpenVINO™ 模型转换
if not onnx_path.exists():
dummy_input = torch.randn(1, 3, IMAGE_HEIGHT, IMAGE_WIDTH)
torch.onnx.export(
model,
dummy_input,
onnx_path,
opset_version=11,
do_constant_folding=False,
)
print(f"ONNX model exported to {onnx_path}.")
else:
print(f"ONNX model {onnx_path} already exists.")5、 将ONNX模型转换为OpenVINO™ IR格式
调用OpenVINO™ 模型优化工具,将ONNX模型转换成OpenVINO™ IR,精度为FP16。模型被保存到当前目录。我们在模型中加入平均值,并用--scale_values对输出的标准偏差进行缩放。有了这些选项,在通过网络传播之前,没有必要对输入数据进行标准化。执行这个命令可能需要一些时间。输出中可能有一些错误或警告。如果输出的最后几行包括[ SUCCESS ] 生成了IR版本10模型,则模型优化是成功的。
1) 准备转换命令
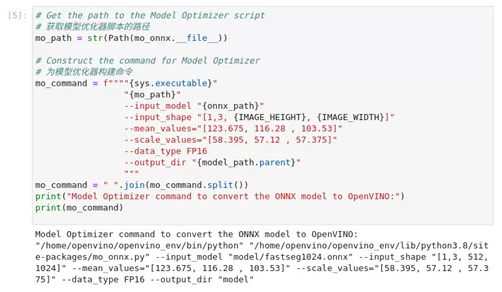
图2-57 pytorch-onnx-to-OpenVINO™ 准备模型优化命令
mo_path = str(Path(mo_onnx.__file__))
mo_command = f""""{sys.executable}"
"{mo_path}"
--input_model "{onnx_path}"
--input_shape "[1,3, {IMAGE_HEIGHT}, {IMAGE_WIDTH}]"
--mean_values="[123.675, 116.28 , 103.53]"
--scale_values="[58.395, 57.12 , 57.375]"
--data_type FP16
--output_dir "{model_path.parent}"
"""
mo_command = " ".join(mo_command.split())
print("Model Optimizer command to convert the ONNX model to OpenVINO:")
print(mo_command)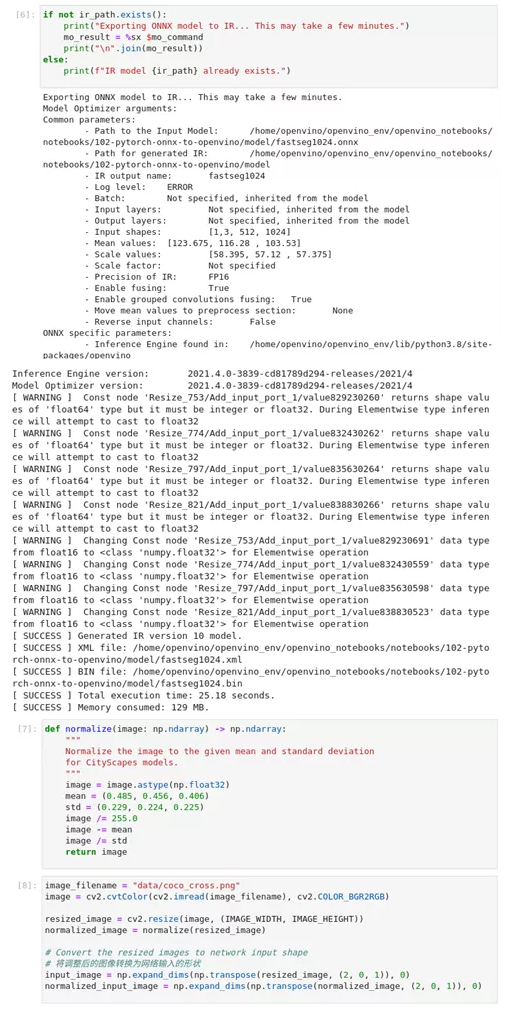
图2-58 pytorch-onnx-to-OpenVINO™ 执行模型优化
if not ir_path.exists():
print("Exporting ONNX model to IR... Thi***ay take a few minute******r>mo_result = %sx $mo_command
print("\n".join(mo_result))
else:
print(f"IR model {ir_path} already exists.")6、 模型对比
通过前面的操作,我们已有了原始模型、ONNX模型以及IR模型,通过比较ONNX、IR和PyTorch模型的预测结果,以确认分割结果与预期相符。
1) 加载和预处理输入图像
对于OpenVINO™ 模型,归一化被移到模型中。对于ONNX和PyTorch模型,图像在通过网络传播之前需要进行标准化处理。
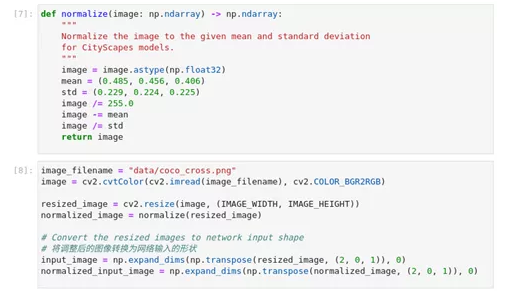
图2-59 pytorch-onnx-to-OpenVINO™ 图片预处理
def normalize(image: np.ndarray) -> np.ndarray:
"""
Normalize the image to the given mean and standard deviation
for CityScape***odel****r>"""
image = image.astype(np.float32)
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
image /= 255.0
image -= mean
image /= std
return image
image_filename = "data/coco_cross.png"
image = cv2.cvtColor(cv2.imread(image_filename), cv2.COLOR_BGR2RGB)
resized_image = cv2.resize(image, (IMAGE_WIDTH, IMAGE_HEIGHT))
normalized_image = normalize(resized_image)
input_image = np.expand_dims(np.transpose(resized_image, (2, 0, 1)), 0)
normalized_input_image = np.expand_dims(np.transpose(normalized_image, (2, 0, 1)), 0)2) 使用ONNX及IR模型进行推理验证
推理引擎可以直接加载ONNX模型。我们首先加载ONNX模型,进行推理并显示结果。之后,我们加载用模型优化器转换为中间表征(IR)的模型,对该模型进行推理并显示结果。我们已经熟悉推理引擎的使用步骤,此处不多赘述。
· 推理引擎中的ONNX模型

图2-60 pytorch-onnx-to-OpenVINO™ onnx模型推理结果
ie = IECore()
net_onnx = ie.read_network(model=onnx_path)
exec_net_onnx = ie.load_network(network=net_onnx, device_name="CPU")
input_layer_onnx = next(iter(exec_net_onnx.input_info))
output_layer_onnx = next(iter(exec_net_onnx.output*****r>res_onnx = exec_net_onnx.infer(inputs={input_layer_onnx: normalized_input_image})
res_onnx = res_onnx[output_layer_onnx]
result_mask_onnx = np.squeeze(np.argmax(res_onnx, axis=1)).astype(np.uint8)
viz_result_image(
image, segmentation_map_to_image(result_mask_onnx, CityScapesSegmentation.get_colormap()), resize=True
)
图2-61 pytorch-onnx-to-OpenVINO™ IR模型推理结果
· PyTorch原始模型推理
在PyTorch模型上做推理,以验证输出在视觉上看起来与ONNX/IR模型的输出相同。

图2-62pytorch-onnx-to-OpenVINO™原始模型推理结果
从结果看,三种模型都成功输出了结果。接下来我们进行性能测试。
1) 性能比较
测量在五幅图像上进行推理所需的时间,给出简版的性能的对比。
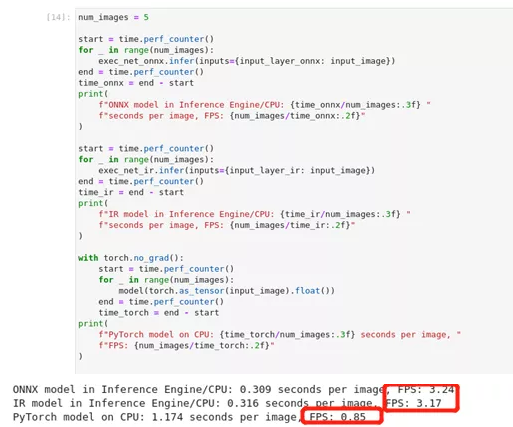
图2-63 pytorch-onnx-to-OpenVINO™ 模型结果对比
num_images = 5
start = time.perf_counter()
for _ in range(num_images):
exec_net_onnx.infer(inputs={input_layer_onnx: input_image})
end = time.perf_counter()
time_onnx = end - start
print(
f"ONNX model in Inference Engine/CPU: {time_onnx/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_onnx:.2f}"
)
start = time.perf_counter()
for _ in range(num_images):
exec_net_ir.infer(inputs={input_layer_ir: input_image})
end = time.perf_counter()
time_ir = end - start
print(
f"IR model in Inference Engine/CPU: {time_ir/num_images:.3f} "
f"seconds per image, FPS: {num_images/time_ir:.2f}"
)
with torch.no_grad():
start = time.perf_counter()
for _ in range(num_images):
model(torch.as_tensor(input_image).float())
end = time.perf_counter()
time_torch = end - start
print(
f"PyTorch model on CPU: {time_torch/num_images:.3f} seconds per image, "
f"FPS: {num_images/time_torch:.2f}"
)从对比结果显示经过模型优化器处理再经推理引擎执行的模型,要比在同一设备上使用原始模型进行推理的效率成倍提升。
2.3.3 PaddlePaddle模型优化
学习目标:
· 掌握PaddlePaddle模型转化为ONNX模型的方法
· 掌握ONNX模型转化为IR格式模型的方法
本节学习如何将在ImageNet数据集上预训练的MobileNet V3 PaddleHub模型转换ONNX及OpenVINO™ IR模型。同时我们继续强化学习如何使用OpenVINO™ Inference Engine对图像进行分类推理,并比较使用PaddlePaddle原始模型与模型优化器转化后的IR模型推理结果差异。
模型来源是:
https://www.paddlepaddle.org.cn/hubdetail?name=mobilenet_v3_large_imagenet_ssld&en_category=ImageClassification
1、 导入模块
图2-64 paddle-onnx-to-OpenVINO™ 原始模型推理结果
print(f"output layout: {net.outputs[output_layer].layout}")
print(f"output precision: {net.outputs[output_layer].precision}")
print(f"output shape: {net.outputs[output_layer].shape}")认识新模块:
· time 用于时间处理的模块
· paddlehub paddlepaddle框架提供的预训练模型库
· Python 是交互式shell库,支持变量自动补全、自动缩进以及多种功能函数
· paddle PaddlePaddle飞桨模型模块
· PIL python图像处理库,用于图像处理例如创建、打开、显示、保存图像、合成、裁剪等等。
· scipy 是一个高级的科学计算库,包含线性代数、优化、集成和统计的模块,该模块包含致力于科学计算中常见问题的各个工具箱。
2、 PaddlePaddle飞桨模型下载配置
设置IMAGE_FILENAME为要使用的图片的文件名。设置MODEL_NAME为要从PaddleHub下载的PaddlePaddle模型。MODEL_NAME也将是转换后的ONNX和IR模型的基本名称。本节使用mobilenet_v3_large_imagenet_ssld模型进行测试。其他模型可能使用不同的预处理方法,可根据需要进行一些修改,以便在原始模型和转换模型上得到相同的结果。hub.config.server是PaddleHub服务器的URL。你应该不需要修改这个设置。

图2-65 paddle-onnx-to-OpenVINO™ 定义模型及下载服务器
IMAGE_FILENAME = "coco_close.png"
MODEL_NAME = "mobilenet_v3_large_imagenet_ssld"
hub.config.server = "https://paddlepaddle.org.cn/paddlehub"3、 PaddlePaddle模型推理
我们从PaddleHub加载并下载模型,读取并显示一幅图像,对该图像进行推理,并显示前三个预测结果。第一次运行时,我们会从PaddleHub下载所需要的模型
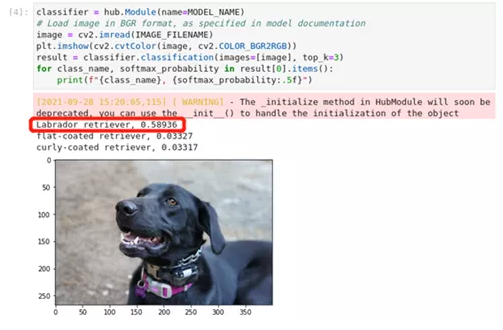
图2-66 paddle-onnx-to-OpenVINO™ 原始模型推理结果
classifier.classification()将一张图片作为输入,并返回图片的类别名称。默认情况下,返回最佳网络结果。使用top_k'参数,将返回最佳的k'结果,其中k是一个数字。对图像的预处理和将网络结果转换为类别名称是在幕后完成的。分类模型返回一个数组,其中包含1000个ImageNet类别中每个类别的浮点值。该值越高,网络就越有信心认为该值对应的类号(该值在网络输出数组中的索引)是该图像的类号。classification()函数将这些数字转换为类别名称和softmax概率。
我们通过process_image()函数查看PaddlePaddle的分类函数以及加载和预处理数据的实现,可以看到裁剪和调整大小的效果。由于归一化,颜色看起来会很奇怪,而且matplotlib会对剪裁值发出警告。
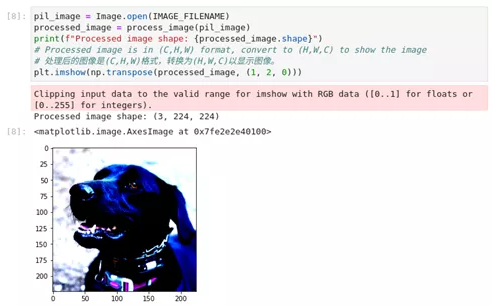
图2-67 paddle-onnx-to-OpenVINO™ process_image结果
4、 将模型转换为OpenVINO™ 的IR格式
为了将PaddlePaddle模型转换为IR格式,我们首先将模型转换为ONNX,然后将ONNX模型转换为IR格式。
1) 准备工作
PaddlePaddle的MobileNet模型包含了关于输入形状、平均值和比例值的信息,我们可以用它来转换模型。

图2-68 paddle-onnx-to-OpenVINO™ 获取模型信息
input_shape = list(classifier.cpu_predictor.get_input_tensor_shape().value******r>print("input shape:", input_shape)
print("mean:", classifier.get_pretrained_image***ean())
print("std:", classifier.get_pretrained_images_std())2) 将PaddlePaddle模型转换为ONNX模型
我们用paddle2onnx.export_onnx_model()方法将PaddlePaddle模型转换为ONNX,详细信息请参考(https://github.com/PaddlePaddle/paddle2onnx)执行完成后我们在model文件夹得到了ONNX模型。

图2-69 paddle-onnx-to-OpenVINO™ 获取模型信息
target_height, target_width = next(iter(input_shape))[2:]
x_spec = InputSpec([1, 3, target_height, target_width], "float32", "x")
print(
"Exporting PaddlePaddle model to ONNX with target_height "
f"{target_height} and target_width {target_width}"
)
classifier.export_onnx_model(".", input_spec=[x_spec], opset_version=11)3) 将ONNX模型转换为OpenVINO™ IR格式
调用OpenVINO™ 模型优化工具,将PaddlePaddle模型转换为OpenVINO™ IR,精度为FP32。这些模型被保存到当前目录中。我们可以用--mean_values将均值添加到模型中,用--scale_values将输出与标准差进行缩放。有了这些选项,在通过网络传播之前,没有必要对输入数据进行标准化处理。然而,为了得到与PaddlePaddle模型完全相同的输出,有必要以同样的方式对图像进行预处理。因此,在本教程中,我们不向模型添加平均值和比例值,我们使用process_image函数,如上节所述,以确保IR和PaddlePaddle模型使用相同的预处理方法。
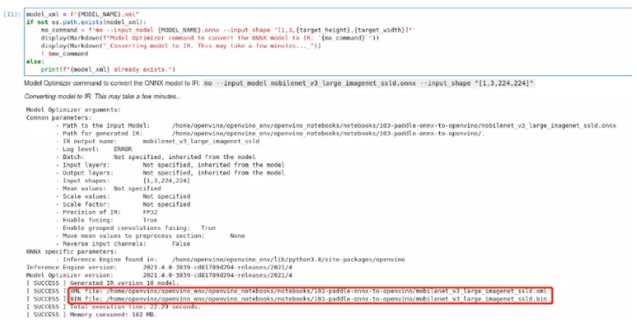
图2-70 paddle-onnx-to-OpenVINO™ 转换为IR模型
model_xml = f"{MODEL_NAME}.xml"
if not os.path.exist***odel_xml):
mo_command = f'mo --input_model {MODEL_NAME}.onnx --input_shape "[1,3,{target_height},{target_width}]"'
display(Markdown(f"Model Optimizer command to convert the ONNX model to IR: `{mo_command}`"))
display(Markdown("_Converting model to IR. Thi***ay take a few minute**********r>! $mo_command
else:
print(f"{model_xml} already exists.")使用模型优化器完成转换后,在model文件夹生成.xml以及.bin的IR模型。
4) 使用推理引擎进行推理
加载IR模型,获取模型信息,加载图像,进行推理,将推理结果转换成有意义的结果,并显示输出
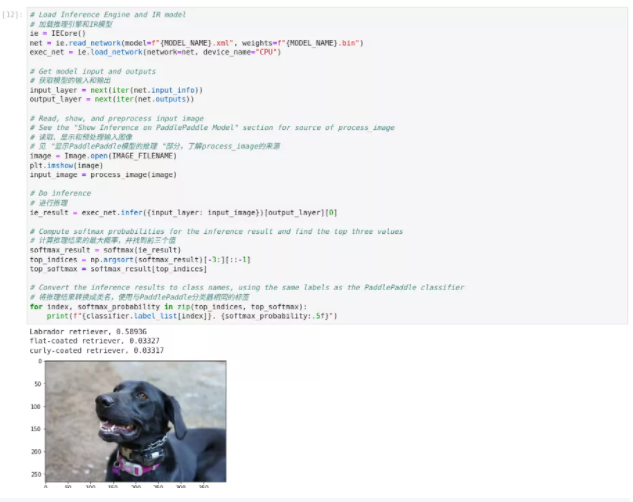
ie = IECore()
net = ie.read_network(f"{MODEL_NAME}.xml")
exec_net = ie.load_network(net, "CPU")
input_layer = next(iter(net.input_info))
output_layer = next(iter(net.output*****r>image = Image.open(IMAGE_FILENAME)
plt.imshow(image)
input_image = process_image(image)
ie_result = exec_net.infer({input_layer: input_image})[output_layer][0]
softmax_result = softmax(ie_result)
top_indices = np.argsort(softmax_result)[-3:][::-1]
top_softmax = softmax_result[top_indice****r>for index, softmax_probability in zip(top_indices, top_softmax):
print(f"{classifier.label_list[index]}, {softmax_probability:.5f}")
ie = IECore()
net = ie.read_network(f"{MODEL_NAME}.xml")
exec_net = ie.load_network(net, "CPU")
input_layer = next(iter(net.input_info))
output_layer = next(iter(net.output*****r>image = Image.open(IMAGE_FILENAME)
plt.imshow(image)
input_image = process_image(image)
ie_result = exec_net.infer({input_layer: input_image})[output_layer][0]
softmax_result = softmax(ie_result)
top_indices = np.argsort(softmax_result)[-3:][::-1]
top_softmax = softmax_result[top_indice****r>for index, softmax_probability in zip(top_indices, top_softmax):
print(f"{classifier.label_list[index]}, {softmax_probability:.5f}")1) 执行效率对比
测量在50张图片上进行推理所需的时间,并比较结果。时间信息给出了一个性能的指示。为了进行公平的比较,我们把处理图像的时间也包括在内。
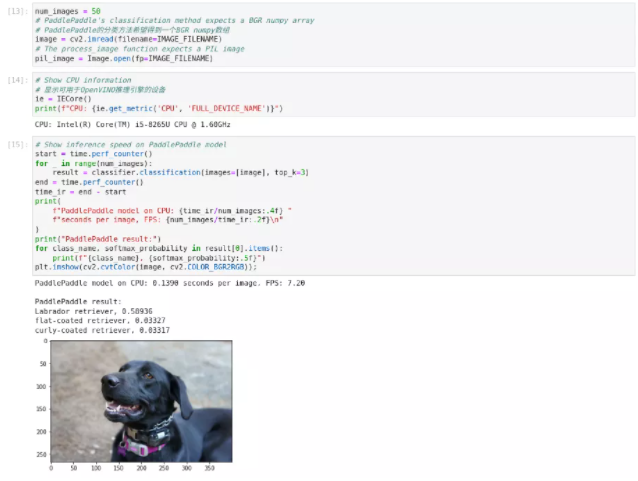
图2-71 paddle-onnx-to-OpenVINO™ 原始模型推理
使用PaddlePaddle原始模型在CPU上进行推理,每幅图像推理时间为0.0506秒,FPS为19.76推理结果为拉布拉多寻回犬。
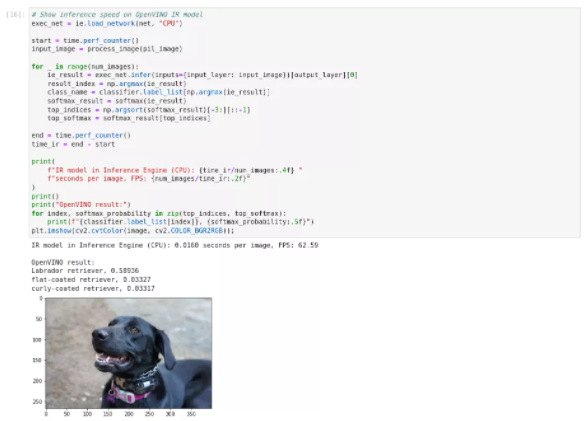
图2-72 paddle-onnx-to-OpenVINO™ IR模型推理
使用优化后的IR模型在CPU上进行推理,每幅图像推理时间为0.0093秒,FPS为107.74推理结果为拉布拉多寻回犬, 在推理精度没有降低的同时推理效率大幅度提升。
2.3.4 模型下载器及转换工具
学习目标:
· 掌握使用模型下载器下载模型
· 掌握使用模型转换器转换公共模型
从前面章节的学习中,我们认识到获取模型、选择模型是人工智能应用开发基础环节同时也是最重要的环节,我们从github、PaddleHub下载了预训练模型,此外Pytorch Hub、Tensorflow都提供了预训练模型供开发者使用。OpenVINO™ 工具包同样提供了Open Model Zoo开放模型库内置了大量的可以商用的预训练模型以及公开模型供我们使用。与此同时,为了方便管理、下载使用这些模型,OpenVINO™工具包提供了模型加载器以及模型转换器工具。本节我们学习使用下载器及转换器,如何从Open Model Zoo下载一个模型,将其转换为OpenVINO™ 的IR格式,显示模型的信息,并对该模型进行基准测试。让我们站在巨人肩膀上加速前进。
关于Open Model Zoo开放模型库的工具
模型下载配套的工具有模型下载器、模型转换器、信息转储器和基准工具。
· 模型下载器 omz_downloader从Open Model Zoo下载模型
· 模型转换器 omz_converter将不是OpenVINO™ 的IR格式的Open Model Zoo模型转换成IR格式
· 信息挖掘器 omz_info_dumper 打印关于Open Model Zoo模型的信息。
基准测试工具benchmark_app 通过计算推理时间对模型性能进行基准测试。
了解以上信息后,我们正式进入操练环节。
1、 准备工作
设置模型名称,设置model_name是下载的Open Model Zoo中模型的名称,演示中我们依旧使MobileNet模型。更多信息可以从官方站点获得:
https://docs.OpenVINO toolkit.org/cn/latest/index.html

图2-73 model-tool 设置模型名称
# model_name = "resnet-50-pytorch"
model_name = "mobilenet-v2-pytorch"2、 导入模块
图2-74 model-tool 导入模块
import json
import os.path
import subproces***r>import sy***r>from pathlib import Path
from IPython.display import Markdown
from OpenVINO.inference_engine import IECore
sys.path.append("../util*****r>from notebook_utils import DeviceNotFoundAlert, NotebookAlertsubprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值
3、 环境配置
设置文件和目录的路径。默认情况下,本演示笔记本从Open Model Zoo下载模型到你的$HOME目录下的open_model_zoo_models目录。在Windows上,$HOME目录通常是c:\users\username,在Linux上是/home/username。如果你想改变文件夹,在下面的单元格中改变base_model_dir。
为了便于模型管理我们可以根据需要修改以下设置。
base_model_dir。模型将被下载到这个目录下的intel和public文件夹。
omz_cache_dir: Open Model Zoo的缓存文件夹。对于模型下载器和模型转换器来说,指定一个缓存目录不是必须的,但它可以加速后续的下载。
precision: 如果指定,只下载此精度的模型。
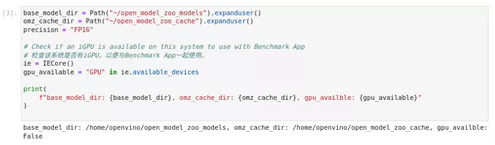
图2-75 model-tool 环节配置
base_model_dir = Path("~/open_model_zoo_models").expanduser()
omz_cache_dir = Path("~/open_model_zoo_cache").expanduser()
precision = "FP16"
ie = IECore()
gpu_available = "GPU" in ie.available_device***r>print(
f"base_model_dir: {base_model_dir}, omz_cache_dir: {omz_cache_dir}, gpu_availble: {gpu_available}"
)4、 从Open Model Zoo下载模型
指定、显示和运行模型下载器命令以下载模型
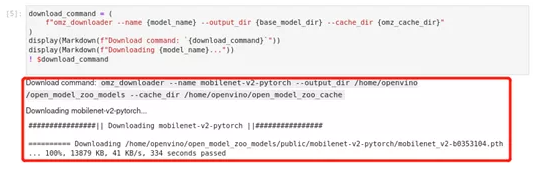
图2-76 model-tool 下载模型
download_command = (
f"omz_downloader --name {model_name} --output_dir {base_model_dir} --cache_dir {omz_cache_dir}"
)
display(Markdown(f"Download command: `{download_command}`"))
display(Markdown(f"Downloading {model_name}..."))
! $download_command我们成功下载了模型,存储在open_model_zoo_models/public/mobilenet-v2-pytorch目录下,需要注意,在下载模型时一定要保证网络畅通。
5、 将模型转换为OpenVINO™ 的IR格式
我们成功下载了PyTorch模型,但推理引擎无法直接加载,因此我们需要进行模型转换。模型转换器的作用是将非IR格式的模型转换为IR格式。通过指定、显示和运行Model Converter命令,将模型转换为IR格式。如果输出的最后几行包括[ SUCCESS ] Generated IR version 10 model。
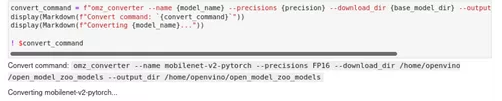
图2-77 model-tool 模型转换命令
convert_command = f"omz_converter --name {model_name} --precisions {precision} --download_dir {base_model_dir} --output_dir {base_model_dir}"
display(Markdown(f"Convert command: `{convert_command}`"))
display(Markdown(f"Converting {model_name}..."))
! $convert_command在前面的小节中,在处理PyTorch模型时需要先转为ONNX,然后在运行模型优化器将ONNX模型转为IR模型,此处我们使用模型转换器这一命令,可以完成全部操作,加快了开发进度。
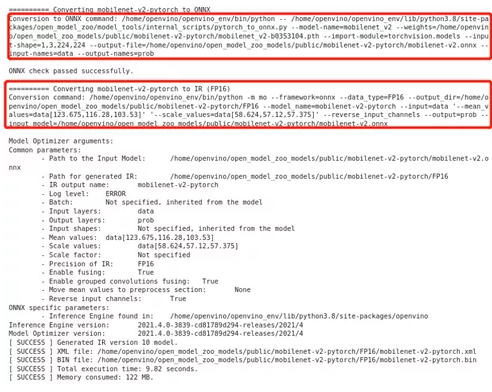
图2-78 model-tool 模型转换结果
通过输出结果我们不难发现,模型转换器为我们自动执行了模型转换以及模型优化工作,这也是Open Model Zoo提供的便捷命令。当然我们也可以需要自行修改参数分步执行。
接下来,info dumper功能查看下我们得到的模型信息。
6、 获取模型信息
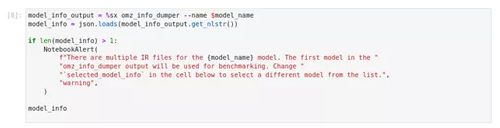
图2-78 model-tool 获取模型信息
model_info_output = %sx omz_info_dumper --name $model_name
model_info = json.load***odel_info_output.get_nlstr())
if len(model_info) > 1:
NotebookAlert(
f"There are multiple IR files for the {model_name} model. The first model in the "
"omz_info_dumper output will be used for benchmarking. Change "
"`selected_model_info` in the cell below to select a different model from the list.",
"warning",
)
model_infoInfo Dumper会打印出Open Model Zoo模型的下列信息。
· 模型名称
· 描述
· 用来训练模型的框架
· 许可证网址
· 模型所支持的精确性
· 子目录:下载模型的位置
· 任务类型
这些信息可以通过在终端运行omz_info_dumper --name model_name来显示。这些信息也可以被解析并在脚本中使用。

图2-78 model-tool info_dumper输出结果
7、 运行基准测试工具
默认情况下,Benchmark Tool在CPU上以异步模式运行推理60秒。它以延迟(每幅图像毫秒)和吞吐量(每秒帧数)的形式返回推理速度。
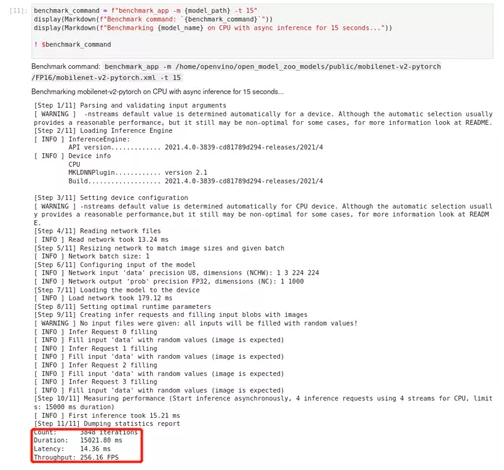
图2-78 model-tool benchmark_app输出结果
用Benchmark工具,我们可以准确跟踪到每一步执行所耗时间以及最终的统计时间,便于我们更好的优化模型及优化程序。此外我们还可以利用基准测试工具提供的扩展参数,进行不同的测试配置,例如指定推理设备、指定运行推理时间、指定同步或一步执行方式以及设置批量大小等等,通过设置不同参数组合,对模型进行多维度测试。下面的单元格显示了一些benchmark_app与不同参数的例子。一些有用的参数是。
-d 用于推理的设备。例如。cpu, gpu, multi. 默认值。CPU
-t 运行推理的时间,以秒数计。默认值:60
-api 使用异步(async)或同步(sync)推理。默认值:async
-b 批量大小。默认值:1
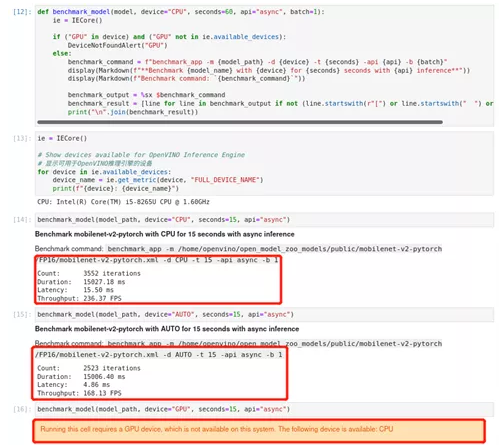
图2-78 model-tool benchmark输出
def benchmark_model(model, device="CPU", seconds=60, api="async", batch=1):
ie = IECore()
if ("GPU" in device) and ("GPU" not in ie.available_devices):
DeviceNotFoundAlert("GPU")
else:
benchmark_command = f"benchmark_app -m {model_path} -d {device} -t {seconds} -api {api} -b {batch}"
display(Markdown(f"**Benchmark {model_name} with {device} for {seconds} seconds with {api} inference**"))
display(Markdown(f"Benchmark command: `{benchmark_command}`"))
benchmark_output = %sx $benchmark_command
benchmark_result = [line for line in benchmark_output if not (line.startswith(r"[") or line.startswith(" ") or line=="")]
print("\n".join(benchmark_result))
ie = IECore()
for device in ie.available_devices:
device_name = ie.get_metric(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")
benchmark_model(model_path, device="CPU", seconds=15, api="async")
benchmark_model(model_path, device="AUTO", seconds=15, api="async")
benchmark_model(model_path, device="GPU", seconds=15, api="async")在笔记中我们指定了CPU设备,指定异步处理,推理时间15秒,批量设置为1,得到了测试结果。由于测试设备中并没有进行GPU配置,因此没有得到GPU推理的参考结果。
2.3.5 小结
通过本节学习我们掌握了模型优化器的使用;掌握了如何将tensorflow、PyTorch、PaddlePaddle模型转化为OpenVINO™ IR模型;此外,我们也学习了如何利用模型下载器从Open Model Zoo开放模型库下载模型,以及使用模型转化器将下载的模型转换为推理引擎支持的IR模型。最后我们也学习了利用Benchmark基准测试工具对模型进行基准测试,为优化模型以及优化程序提供参考。
2.4 本章小结
通过本章学习相信大家已经掌握了OpenVINO™ 推理引擎以及模型优化器的使用,通过多个笔记实操,相信大家也熟练掌握了利用OpenVINO™ 快速开发人工智能应用的精髓:使用模型优化器准备模型,对需要推理的图片进行预处理以满足模型输入的需要,使用推理引擎执行推理获得结果,最后对推理结果进行可视化操作以便于查看。
通过实训相信大家也认识了分类模型、文字检测模型、语义分割模型的使用。在下一章我们继续实战,用OpenVINO™ 工具包开发更复杂、更有趣的应用,同时,我们也会学习从训练到推理的人工智能全流程开发,并借助OpenVINO™ 对训练结果进行性能优化。
【本文转自:英特尔物联网】
0个评论