使用OpenVINO优化和部署DenseNet模型并在DevCloud上完成性能测试-上篇
 openlab_4276841a
更新于 4年前
openlab_4276841a
更新于 4年前
概述
Intel® DevCloud for the Edge支持在英特尔的硬件平台上主动构建原型并试验面向计算机视觉的AI 工作负载。其硬件平台托管在云环境中,专门用于深度学习,用户可以全面访问这些硬件平台。用户可以使用Intel® OpenVINO™ 工具套件以及CPU、GPU和VPU和FPGA的组合来测试模型的性能。Intel® DevCloud使用Jupyter* Notebook直接在web浏览器中执行代码,并立即看到可视化结果。用户可以在云环境中构建创新的计算机视觉解决方案原型,然后利用可用的硬件资源执行代码。
本文借助DevCloud内包含的Jupyter*Notebook教程和示例,及OpenVINO™ 工具套件包含的Benchmark_APP等工具,将下载并转换为IR格式文件的FC-DenseNet-103模型到DevCloud,选择不同的边缘节点,以不同的硬件平台测试模型的性能,完成边缘原型的构建,得到高性能的AI部署解决方案。
在本文中所使用的模型为FC-DenseNet-103—百层提拉米苏,全卷积的DenseNet图像分割模型,如图 1所示为其在CamVid测试集的定性结果。模型FC-DenseNet-103的论文原始出处为:https://arxiv.org/pdf/1611.09326.pdf。
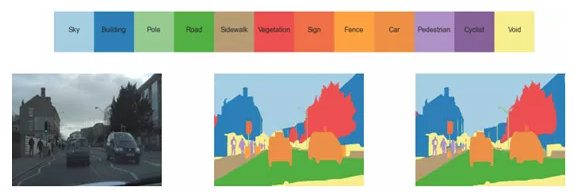
图 1 在CamVid测试集的定性结果
本文具体步骤主要分为以下四步:
● 第一步,安装TensorFlow相关支持并验证安***r>
● 第二步,下载并运行FC-DenseNet-03预训练模型
● 第三步,将Keras h5模型转换模型为ONNX格式和IR格式文件
● 第四步,使用Benchmark_APP在各个目标硬件上进行性能测试
本文需要的软件运行环境及其对应版本如下:
● OpenVINO™ 2021.4 LTS
● TensorFlow 2.2.0
● Python 3.8.10
一、使用OpenVINO™ 工具套件转化和部署FC-DenseNet-103模型
1.1 OpenVINO™ 工具套件简介
OpenVINO™ 工具套件全称是Open Visual Inference & Neural Network Optimization,是英特尔® 于2018年发布的开源工具包,专注于优化神经网络推理。OpenVINO™ 工具套件主要包括Model Optimizer(模型优化器)和Inference Engine(推理引擎)两个部分。Model Optimizer是用于优化神经网络模型的工具,Inference Engine是用于加速推理计算的软件包。如图1-1所示,即为OpenVINO™ 工具套件的主要组成部分。
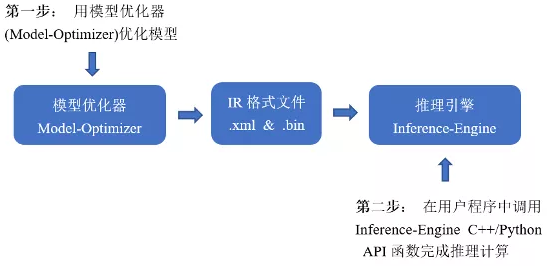
图1-1 OpenVINO™ 工具套件
1.2 安装Keras2ONNX转换ONNX模型
Keras最初是由Google工程师撰写的研究项目,是基于TensorFlow的深度学习库,是由Python语言编写而成的高层神经网络API。如果安装了TensorFlow2.2.0,则已经安装了Keras,ONNX模型(开放神经网络变换)是一种用于表示深度学习模型的开放格式。我们需要将FC-DenseNet-103模型转换为ONNX模型,再使用OpenVINO™ 工具套件进行优化部署。具体转换的步骤如下:
第一步,在将Keras模型转换为ONNX之前,需要安装Keras2onnx软件包。打开windows命令行终端,进入TensorFlow虚拟环境,输入命令< pip install keras2onnx >安装Keras2ONNX支持,如图1-2所示:
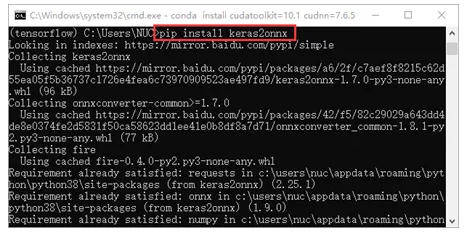
图1-2 安装Keras2ONNX支持
或者从源代码安装Keras2ONNX,使用命令为:< pip install -U git+https://github.com/microsoft/onnxconverter-common;pip install -U git+https://github.com/onnx/keras-onnx > ,Keras2ONNX的安装依赖于onnxconverter-common,此转换器的最新代码需要onnxconverter-common的最新版本,因此,如果从源代码安装此转换器,需要,安装Keras2ONNX之前以源码形式安装onnxconverter-common。
第二步,转换ONNX模型,在打开的“TensorFlow”虚拟环境命令行终端,通过运行命令来运行转换ONNX模型的Python脚本,其代码具体内容如代码清单1-1所示:
代码清单1-1 转换ONNX模型
from tensorflow.kera***odels import Model
from tensorflow.keras.layers import *
from tiramisu.model import create_tiramisu
import keras2onnx
# Set the weight file name
kera***odel_weight******odel***y_tiramisu.h5"
onnx_model_weights = kera***odel_weights.split('.')[0]+'.onnx'
# Load model and weight***r>
input_shape = (224, 224, 3)
number_classes = 32 # CamVid data consist of 32 classe***r>
# Prepare the model information
img_input = Input(shape=input_shape, batch_size=1)
x = create_tiramisu(number_classes, img_input)
model = Model(img_input, x)
# Load the kera***odel weight***r>
model.load_weights(kera***odel_weight****r>
print("Line17")
print(model.name)
onnx_model = keras2onnx.convert_kera***odel, model.name)
# Save the onnx model weight***r>
keras2onnx.save_model(onnx_model, onnx_model_weights)运行成功后会在“models”文件夹中自动生成名为my_tiramisu.onnx的ONNX模型,用以进行OpenVINO™ 工具套件的优化部署。
1.3 使用Model_Optimizer优化模型
使用OpenVINO™ 工具套件将ONNX模型转换为IR格式文件,需要以下几步:
第一步,初始化OpenVINO™ 工具套件,进入Windows命令行终端,输入命令<"C:\Program Files (x86)\Intel\openvino_2021.4.582\bin\setupvar***at">对其进行初始化。
第二步,使用Model_Optimizer将ONNX模型转换为IR格式文件,首先进入\deployment_tools\model_optimizer路径下的命令行终端,使用命令 <python mo_onnx.py="" --input_model="" \my_tiramisu.onnx --output_dir>,即可生成如图1-3所示的IR格式文件。

图1-3 转换成IR格式文件
1.4 Inference Engine 应用程序典型开发流程
Inference Engine典型的开发流程一共有八步,如图1-4所示。每一步使用相应的API函数进行应用程序的开发。本文基于1.3节生成的IR格式文件my_tiramisu.xml和my_tiramisu.bin从零开始,实现完整的OpenVINO™ AI推理Python程序。
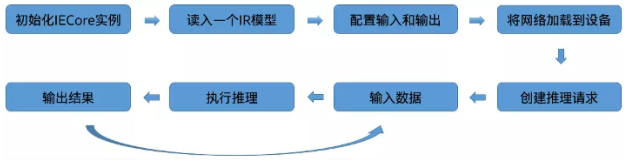
图1-4 Inference Engine典型开发流程
本文通过直接调用Inference Engine Python API函数来开发OpenVINO™ AI推理计算Python程序,具体步骤如下:
具体代码如下:inference_run.py
第一步,导入必要的openvino.inference_engine、cv2、numpy、time、os、sys、decode和argparse模块并配置相关变量,如代码清单1-2所示。
代码清单1-2 导入必要模块
from openvino.inference_engine import IECore
import numpy as np
import time
import cv2 as cv
import os,sy****r>
from camvid.mapping import decode
import argparse第二步,使用ie=IECore()方法,初始化IECore实例,此类表示推理引擎实体,并允许使用统一的接口操纵插件,如代码清单1-3所示。参考Inference_Engine典型推理流程第一步。
代码清单1-3 初始化IECore()实例
#1.初始化IECore()实例
ie = IECore()
for device in ie.available_devices:
print(device)第三步,读取IR文件,用net=ie.read.network()方法将IR文件读取到对象net中去,如代码清单1-4所示。参考Inference_Engine典型推理流程第二步。
代码清单1-4 读取IR文件
#2.读入IR格式文件
model_xml = "model***y_tiramisu.xml"
model_bin = "model***y_tiramisu.bin"
net = ie.read_network(model=model_xml, weight***odel_bin)第四步,配置输入输出,通过input_info和output_info的方法来配置网络输入输出,如代码清单1-5所示。参考Inference_Engine典型推理流程第三步。
代码清单1-5 配置输入输出
#3.配置输入和输出
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))第五步,载入模型到执行硬件,使用exec_net=ie.load_network(),将从中间表示 (IR) 读取的网络加载到具有指定设备名称的插件中,载入模型到执行硬件,如代码清单1-6所示。参考Inference_Engine典型推理流程第四步。
代码清单1-6 载入模型到执行硬件
#4.载入模型到执行硬件
exec_net = ie.load_network(network=net, device_name=args.d)第六步,准备输入数据,根据AI模型输入张量的要求,对图像进行缩放处理,创建模型的输入数据,如代码清单1-7所示。参考Inference_Engine典型推理流程第六步。
代码清单1-7 准备输入数据
#5.准备输入数据
n, h, w, c = net.input_info[input_blob].input_data.shape
print(n, h, w, c)
test = 'images/test_image1.png'
frame = cv.imread(test)
print(frame.shape)
image = cv.resize(frame, (w, h))
#image = image.transpose(2, 0, 1)
print(image.shape)
img_input = image[np.newaxis,:]第七步,创建推理请求并执行推理计算,在创建推理引擎和执行推理计算的步骤中,使用res=exec_net.infer()方法创建推理请求,并执行推理计算,还可以通过time模块来记录推理所用的时间,如代码清单1-8所示。参考Inference_Engine典型推理流程第五步和第七步;
代码清单1-8 创建推理请求并执行推理计算
#6.创建推理请求, 7.执行推理计算
infer_time_list = []
inf_start = time.time()
res = exec_net.infer(inputs={input_blob:img_input})
inf_end = time.time() - inf_start
infer_time_list.append(inf_end)第八步,处理计算结果,根据模型需要的输出格式,从net.infer()方法的返回值中获得推理计算结果,经过处理后将结果显示在图像上,如代码清单1-9所示。参考Inference_Engine典型推理流程第八步。
代码清单1-9 处理计算结果
#8.处理计算结果
res = res[out_blob].reshape((n, h, w, 32))
res = np.squeeze(res, 0)
res = np.argmax(res, axis=-1)
hh, ww = res.shape
print(res.shape)
mask = color_label(res,id2code)
mask = cv.resize(mask, (frame.shape[1], frame.shape[0]))
result = cv.addWeighted(frame, 0.5, mask, 0.5, 0)
cv.putText(result, "infer time(ms): %.3f, FPS: %.2f"%(inf_end*1000, 1/(inf_end+0.0001)), (10, 50),
cv.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 255), 2, 8)
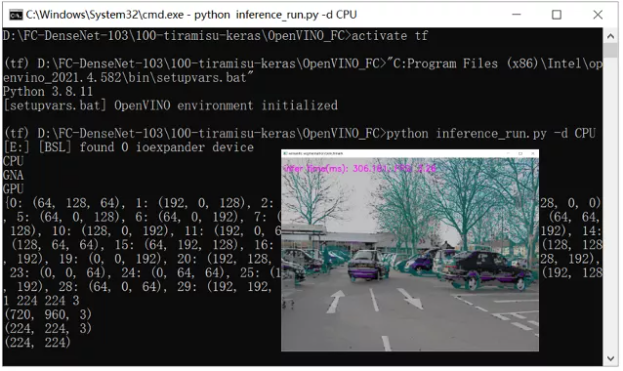
cv.imshow("semantic segmentation benchmark", result)
cv.waitKey(0) # wait for the image show第九步,打开Windows的命令行终端,进入tensorflow2.2.0版本的虚拟环境中,初始化OpenVINO™ 工具套件,然后使用命令运行程序,推理结果如图1-5所示,至此,整个部署流程就结束了,已经成功把模型落地并部署到了边缘设备的CPU上。